
Microsoft의 최신 NaturalSpeech2 음성 합성 모델: 보다 정확한 음성 재구성을 제공하고 스틱 읽기 효과를 방지합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-08-04 09:41:051153검색

7월 27일 Microsoft는 최근 NaturalSpeech2라는 음성 모델을 출시했습니다. 이 모델은 "잠재적 확산" 설계를 채택했으며 제로 샘플 음성 합성 수준에서 뛰어난 결과를 제공한다고 Microsoft는 주장합니다. "등급" 음성/노래 솔루션은 사용자에게 고품질의 다양한 음성 합성 경험을 제공할 수 있습니다.
Microsoft는 샘플 없이 다양한 화자 ID, 운율 및 스타일(예: 노래)로 음성을 생성하는 NaturalSpeech2의 능력을 보여주는 일련의 시연을 실시했습니다.

▲ 이미지 출처는 NaturalSpeech 2 논문에서 가져온 것입니다.
보고되었습니다 기존의 음성-텍스트(TTS) 시스템과 달리 Microsoft의 NaturalSpeech2는 "이산 마커" 대신 "연속 벡터"를 사용하여 음성을 표현함으로써 "감정 부족"을 생성하지 않고 보다 완전한 음성 세그먼트를 생성합니다. 스틱 읽기(단어 단위로 말하기)".
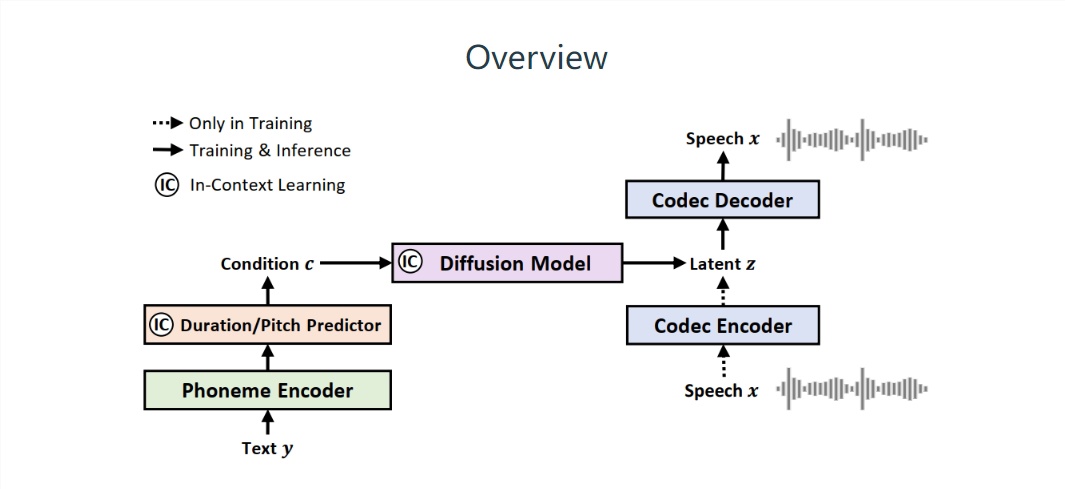
NaturalSpeech2가 제로 샘플 조건에서 생성한 음성은 음성 프롬프트 및 실제 음성의 운율과 거의 일치하며 LibriTTS에서는 자연스럽습니다. 및 VCTK 테스트 세트 학위(CMOS에서 측정)는 사람의 말과 구별할 수 없습니다 .
이 프로젝트의 논문은 GitHub에 게시되었습니다. 관심 있는 IT House 친구들은여기를 클릭하여 방문할 수 있습니다.
위 내용은 Microsoft의 최신 NaturalSpeech2 음성 합성 모델: 보다 정확한 음성 재구성을 제공하고 스틱 읽기 효과를 방지합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!