
운영 체제 요약을 자세히 설명하는 30장의 사진!
- Linux中文社区앞으로
- 2023-08-02 17:56:011686검색
1. 개요
기본 기능
1. 동시성
동시성은 거시적인 의미에서 여러 프로그램을 동시에 실행하는 능력을 의미하고, 병렬성은 동시에 여러 프로그램을 실행하는 능력.
병렬 처리에는 다중 파이프라인, 다중 코어 프로세서 또는 분산 컴퓨팅 시스템과 같은 하드웨어 지원이 필요합니다.
운영 체제에서는 프로세스와 스레드를 도입하여 프로그램을 동시에 실행할 수 있습니다.
2. 공유
공유는 시스템의 리소스를 여러 동시 프로세스에서 사용할 수 있음을 의미합니다.
공유 방법에는 상호 배타적 공유와 동시 공유의 두 가지가 있습니다.
상호 배타적인 공유 리소스는 프린터 등과 같은 중요한 리소스라고 하며 동시에 하나의 프로세스만 액세스할 수 있으며 상호 배타적인 액세스를 달성하려면 동기화 메커니즘이 필요합니다.
3. 가상
가상 기술은 물리적 개체를 여러 논리적 개체로 변환합니다.
가상 기술에는 크게 두 가지가 있는데, 시간(시간) 분할 다중화 기술과 공간(공간) 분할 다중화 기술입니다.
시분할 다중화 기술을 사용하여 동일한 프로세서에서 여러 프로세스를 동시에 실행할 수 있으므로 각 프로세스가 차례로 프로세서를 점유하여 매번 작은 시간 조각만 실행하고 빠르게 전환할 수 있습니다.
가상 메모리는 물리적 메모리를 주소 공간으로 추상화하는 공간 분할 다중화 기술을 사용하며, 각 프로세스는 자체 주소 공간을 갖습니다. 주소 공간의 페이지는 물리적 메모리에 매핑됩니다. 주소 공간의 모든 페이지가 물리적 메모리에 있을 필요는 없습니다. 물리적 메모리에 없는 페이지를 사용하는 경우 페이지 교체 알고리즘이 실행되어 해당 페이지를 메모리로 교체합니다.
4. 비동기식
비동기식은 프로세스가 한꺼번에 실행되지 않고 정지했다가 알 수 없는 속도로 진행되는 것을 의미합니다.
기본 기능
1. 프로세스 관리
프로세스 제어, 프로세스 동기화, 프로세스 통신, 교착 상태 처리, 프로세서 스케줄링 등
2. 메모리 관리
메모리 할당, 주소 매핑, 메모리 보호 및 공유, 가상 메모리 등
3. 파일 관리
파일 저장 공간 관리, 디렉토리 관리, 파일 읽기 및 쓰기 관리 및 보호 등
4. 장치 관리
사용자의 I/O 요청을 완료하고 사용자가 다양한 장치를 사용할 수 있도록 하며 장치 활용도를 향상시킵니다.
주로 버퍼 관리, 장치 할당, 장치 처리, 가상 장치 등이 포함됩니다.
시스템 호출
프로세스가 사용자 모드에서 커널 상태 기능을 사용해야 하는 경우 시스템 호출을 하고 커널에 빠지면 운영 체제가 대신 완료합니다.
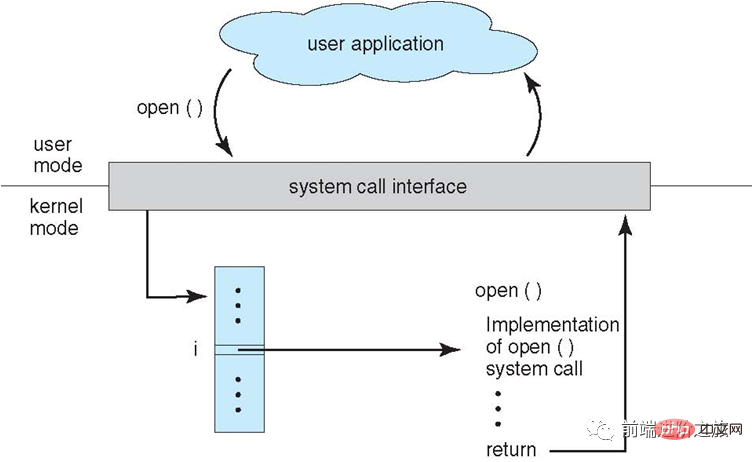
Linux의 시스템 호출에는 주로 다음이 포함됩니다.

대형 커널 및 마이크로 커널
1. 대형 커널
대형 커널은 운영 체제를 처리합니다. 로 기능한다 닫기 결합된 전체가 커널에 저장됩니다.
각 모듈은 정보를 공유하기 때문에 성능이 좋습니다.
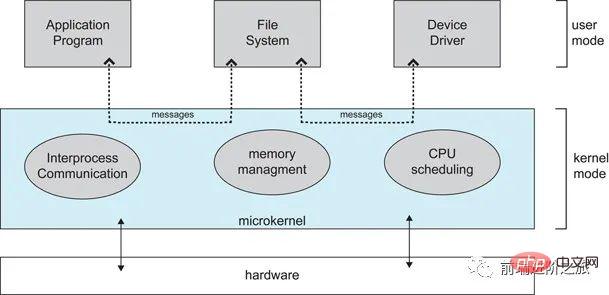
2. 마이크로커널
운영 체제가 계속해서 복잡해짐에 따라 일부 운영 체제 기능이 커널 밖으로 이동되어 커널의 복잡성이 줄어듭니다. 제거된 부분은 레이어링 원리에 따라 여러 서비스로 분할되어 서로 독립적입니다.
마이크로커널 구조에서 운영 체제는 작고 잘 정의된 모듈로 구분됩니다. 마이크로커널 모듈만 커널 모드에서 실행되고 다른 모듈은 사용자 모드에서 실행됩니다.
사용자 모드와 코어 모드 사이를 자주 전환해야 하기 때문에 특정 성능 손실이 발생합니다.
인터럽트 분류
1. 외부 인터럽트
는 I/O 완료 인터럽트와 같은 CPU 실행 명령 이외의 이벤트로 인해 발생합니다. 완료되고 프로세서는 다음 입력/출력 요청을 보낼 수 있습니다. 또한 클럭 인터럽트, 콘솔 인터럽트 등이 있습니다.

2. 예외
는 CPU가 잘못된 opcode, 범위를 벗어난 주소, 산술 오버플로 등의 명령을 실행할 때 내부 이벤트로 인해 발생합니다.
3. 사용자 프로그램에서 시스템 호출을 사용하는
에 빠지다.
2. 프로세스 관리
프로세스 및 스레드
1. 프로세스
프로세스는 자원 할당의 기본 단위입니다.
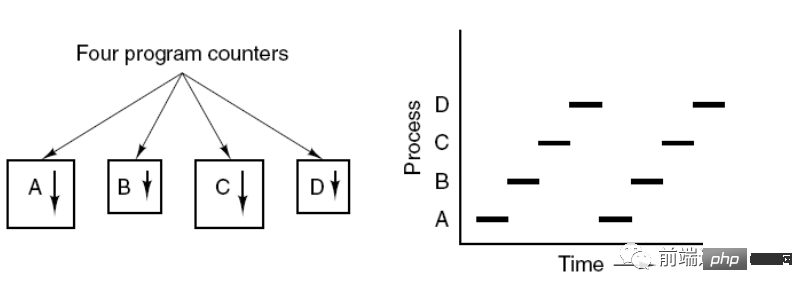
프로세스 제어 블록(PCB)은 프로세스의 기본 정보와 실행 상태를 설명합니다. 소위 프로세스 생성 및 취소는 PCB에서의 작업을 나타냅니다.
아래 그림은 4개의 프로그램이 4개의 프로세스를 생성하고, 이 4개의 프로세스가 동시에 실행될 수 있음을 보여줍니다.
2. 스레드
스레드는 독립 스케줄링의 기본 단위입니다.
한 프로세스에는 여러 스레드가 있을 수 있으며 프로세스 리소스를 공유합니다.
QQ와 브라우저는 두 가지 프로세스입니다. 브라우저 프로세스에는 HTTP 요청 스레드, 이벤트 응답 스레드, 렌더링 스레드 등 많은 스레드가 있습니다. 스레드를 동시에 실행하면 브라우저에서 새 링크를 클릭하여 시작할 수 있습니다. HTTP 요청. 브라우저는 사용자의 다른 이벤트에도 응답할 수 있습니다.
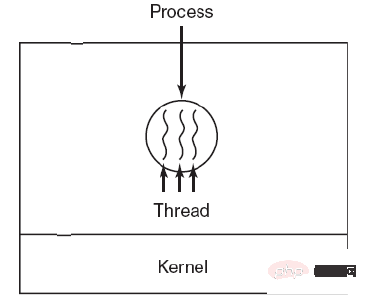
3. 차이점
Ⅰ 리소스 소유
프로세스는 리소스 할당의 기본 단위이지만 스레드는 리소스를 소유하지 않으며 스레드는 프로세스에 속한 리소스에 액세스할 수 있습니다.
II Scheduling
스레드는 독립적인 스케줄링의 기본 단위입니다. 동일한 프로세스에서 스레드 전환으로 인해 한 프로세스의 스레드에서 다른 프로세스의 스레드로 전환되면 프로세스 전환이 발생합니다.
III 시스템 오버헤드
프로세스를 생성하거나 취소할 때 시스템은 메모리 공간, I/O 장치 등의 자원을 할당하거나 재활용해야 하기 때문에 발생하는 오버헤드는 스레드를 생성하거나 취소할 때의 오버헤드보다 훨씬 큽니다. 마찬가지로 프로세스를 전환할 때도 현재 실행 중인 프로세스의 CPU 환경을 저장하고 새로 예약된 프로세스의 CPU 환경을 설정하는 작업이 포함됩니다. 그러나 스레드를 전환할 때는 소수의 레지스터 내용만 저장하고 설정하면 됩니다. 오버헤드가 매우 작습니다.
IV 통신에 있어서
스레드는 동일한 프로세스에서 데이터를 직접 읽고 쓰는 방식으로 통신할 수 있지만, 프로세스 통신에는 IPC를 사용해야 합니다.
프로세스 상태 전환
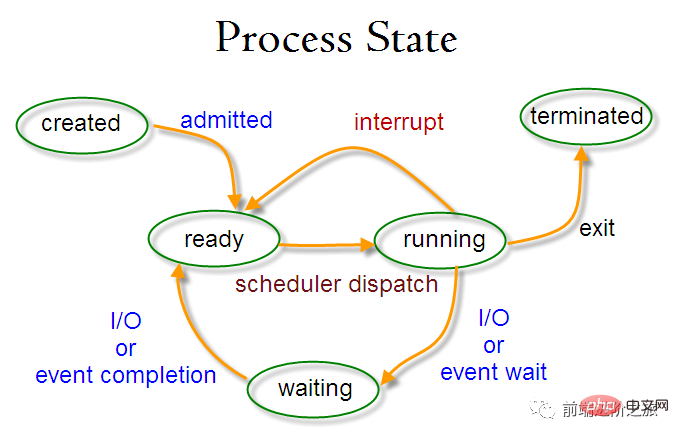
준비 상태(준비): 예약 대기 중
실행 상태(실행 중)
-
차단 상태(대기) : 리소스를 기다릴 때
다음 사항에 주의해야 합니다.
준비 상태와 실행 상태만 서로 변환될 수 있으며 나머지는 단방향 변환입니다. 준비 상태의 프로세스는 스케줄링 알고리즘을 통해 CPU 시간을 획득하고 실행 상태로 변경되며, 실행 상태의 프로세스는 할당된 CPU 시간 조각을 모두 사용한 후 준비 상태로 변경되어 다음 스케줄링을 기다립니다. .
Blocking 상태는 필요한 리소스가 부족하여 실행 중인 상태에서 변환되지만, 이 리소스에는 CPU 시간이 포함되지 않아 실행 중 상태에서 준비 상태로 변환됩니다.
Process Scheduling Algorithm
다양한 환경의 스케줄링 알고리즘은 목표가 다르기 때문에 다양한 환경에 대한 스케줄링 알고리즘을 논의해야 합니다.
1. 일괄 처리 시스템
일괄 처리 시스템은 사용자 작업이 너무 많지 않습니다. 이 시스템에서 스케줄링 알고리즘의 목표는 처리량과 처리 시간(제출부터 종료까지의 시간)을 보장하는 것입니다.
1.1 선착순 서버(FCFS)
요청 순서대로 예약하는 비선점형 예약 알고리즘입니다.
긴 작업에는 좋지만 짧은 작업에는 좋지 않습니다. 왜냐하면 짧은 작업은 이전 긴 작업이 완료될 때까지 기다려야 실행이 가능하고, 긴 작업은 오랜 시간 동안 실행해야 하므로 결과적으로 시간이 단축되기 때문입니다. 너무 오랫동안 기다리는 작업.
1.2 최단 작업 우선(SJF)
예상 실행 시간이 가장 짧은 순서대로 스케줄링하는 비선점형 스케줄링 알고리즘입니다.
긴 작업은 굶어 죽을 수도 있고, 짧은 작업이 완료되기를 기다리는 상태일 수도 있습니다. 왜냐하면 항상 짧은 일자리가 오면 긴 일자리는 결코 예약되지 않을 것이기 때문입니다.
1.3 가장 짧은 남은 시간 다음(SRTN)
가장 짧은 작업을 먼저 선점하는 버전으로, 남은 실행 시간 순으로 예약됩니다. 새 작업이 도착하면 해당 작업의 전체 실행 시간을 현재 프로세스의 남은 시간과 비교합니다. 새 프로세스에 더 적은 시간이 필요한 경우 현재 프로세스가 일시 중지되고 새 프로세스가 실행됩니다. 그렇지 않으면 새 프로세스가 대기합니다.
2. 대화형 시스템
대화형 시스템은 사용자 상호 작용이 많으며 이 시스템의 스케줄링 알고리즘의 목표는 신속하게 응답하는 것입니다.
2.1 시간 분할 회전
FCFS 원칙에 따라 모든 준비된 프로세스를 대기열에 배열합니다. 예약될 때마다 CPU 시간이 타임 슬라이스를 실행할 수 있는 대기열 리더 프로세스에 할당됩니다. 타임 슬라이스가 모두 소모되면 타이머에 의해 클럭 인터럽트가 발생하고 스케줄러는 프로세스의 실행을 중지하고 이를 준비 큐의 끝으로 보내는 동시에 선두 프로세스에 CPU 시간을 계속 할당합니다. 대기열.
타임 슬라이스 회전 알고리즘의 효율성은 타임 슬라이스의 크기와 큰 관계가 있습니다.
프로세스 전환은 프로세스 정보를 저장하고 새로운 프로세스 정보를 로드해야 하기 때문에 타임 슬라이스가 너무 작을 경우, 프로세스 전환이 발생합니다. 프로세스를 전환하는 데 너무 자주, 너무 많은 시간이 소요됩니다.
그리고 타임 슬라이스가 너무 길면 실시간 성능을 보장할 수 없습니다.
2.2 우선순위 스케줄링
각 프로세스에 우선순위를 할당하고 우선순위에 따라 예약합니다.
우선순위가 낮은 프로세스가 예약을 기다리지 않도록 방지하려면 시간이 지남에 따라 대기 프로세스의 우선순위를 높일 수 있습니다.
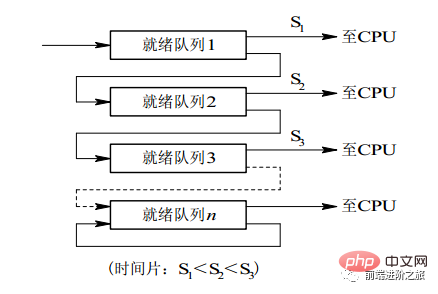
2.3 다단계 피드백 큐
프로세스는 100개의 타임 슬라이스를 실행해야 합니다. 타임 슬라이스 회전 스케줄링 알고리즘을 사용하면 100개의 교환이 필요합니다.
다중 레벨 큐는 여러 개의 타임 슬라이스를 연속적으로 실행해야 하는 프로세스에 대해 고려되며, 여러 개의 큐를 설정하며 각 큐는 1,2,4,8 등과 같이 서로 다른 타임 슬라이스 크기를 갖습니다. 프로세스가 첫 번째 큐에서 실행을 마치지 않으면 다음 큐로 이동합니다. 이런 식으로 이전 프로세스는 7번만 교체하면 됩니다.
각 대기열에는 서로 다른 우선순위가 있으며, 가장 높은 대기열의 우선순위가 가장 높습니다. 따라서 이전 큐에 프로세스가 없는 경우에만 현재 큐의 프로세스를 예약할 수 있습니다.
이 스케줄링 알고리즘은 타임 슬라이스 회전 스케줄링 알고리즘과 우선순위 스케줄링 알고리즘의 조합으로 간주할 수 있습니다.
3. 실시간 시스템
실시간 시스템에서는 특정 시간 내에 요청에 응답해야 합니다.
牛逼啊!接私活必备的 N 个开源项目!赶快收藏吧...
는 하드 실시간과 소프트 실시간으로 구분됩니다. 전자는 절대 기한을 준수해야 하며 후자는 특정 시간 초과를 허용할 수 있습니다.
프로세스 동기화
1. 크리티컬 섹션
크리티컬 리소스에 액세스하는 코드를 크리티컬 섹션이라고 합니다.
중요 리소스에 상호 배타적으로 액세스하려면 중요 섹션에 들어가기 전에 각 프로세스를 확인해야 합니다.
// entry section // critical section; // exit section
2. 동기화 및 상호 배제
동기화: 협력으로 인한 직접적인 제한 관계로 인해 여러 프로세스가 일정한 순차적 실행 관계를 갖습니다.
상호 배제: 여러 프로세스 중 하나의 프로세스만 동시에 임계 영역에 들어갈 수 있습니다.
3. 세마포어
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// 生产者客户端
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// 消费者客户端
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;经典同步问题
生产者和消费者问题前面已经讨论过了。
1. 哲学家进餐问题
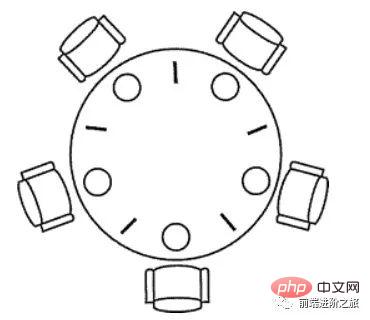
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
#define N 5
void philosopher(int i) {
while(TRUE) {
think();
take(i); // 拿起左边的筷子
take((i+1)%N); // 拿起右边的筷子
eat();
put(i);
put((i+1)%N);
}
}为了防止死锁的发生,可以设置两个条件:
必须同时拿起左右两根筷子;
只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5
#define LEFT (i + N - 1) % N // 左邻居
#define RIGHT (i + 1) % N // 右邻居
#define THINKING 0
#define HUNGRY 1
#define EATING 2
typedef int semaphore;
int state[N]; // 跟踪每个哲学家的状态
semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
semaphore s[N]; // 每个哲学家一个信号量
void philosopher(int i) {
while(TRUE) {
think(i);
take_two(i);
eat(i);
put_two(i);
}
}
void take_two(int i) {
down(&mutex);
state[i] = HUNGRY;
check(i);
up(&mutex);
down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
}
void put_two(i) {
down(&mutex);
state[i] = THINKING;
check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
check(RIGHT);
up(&mutex);
}
void eat(int i) {
down(&mutex);
state[i] = EATING;
up(&mutex);
}
// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
void check(i) {
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
state[i] = EATING;
up(&s[i]);
}
}2. 读者-写者问题
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。另外,搜索公众号顶级算法后台回复“算法”,获取一份惊喜礼包。
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
typedef int semaphore;
semaphore count_mutex = 1;
semaphore data_mutex = 1;
int count = 0;
void reader() {
while(TRUE) {
down(&count_mutex);
count++;
if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
up(&count_mutex);
read();
down(&count_mutex);
count--;
if(count == 0) up(&data_mutex);
up(&count_mutex);
}
}
void writer() {
while(TRUE) {
down(&data_mutex);
write();
up(&data_mutex);
}
}以下内容由 @Bandi Yugandhar 提供。
The first case may result Writer to starve. This case favous Writers i.e no writer, once added to the queue, shall be kept waiting longer than absolutely necessary(only when there are readers that entered the queue before the writer).
int readcount, writecount; //(initial value = 0)
semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)
//READER
void reader() {
<ENTRY Section>
down(&readLock); // reader is trying to enter
down(&rmutex); // lock to increase readcount
readcount++;
if (readcount == 1)
down(&resource); //if you are the first reader then lock the resource
up(&rmutex); //release for other readers
up(&readLock); //Done with trying to access the resource
<CRITICAL Section>
//reading is performed
<EXIT Section>
down(&rmutex); //reserve exit section - avoids race condition with readers
readcount--; //indicate you're leaving
if (readcount == 0) //checks if you are last reader leaving
up(&resource); //if last, you must release the locked resource
up(&rmutex); //release exit section for other readers
}
//WRITER
void writer() {
<ENTRY Section>
down(&wmutex); //reserve entry section for writers - avoids race conditions
writecount++; //report yourself as a writer entering
if (writecount == 1) //checks if you're first writer
down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
up(&wmutex); //release entry section
<CRITICAL Section>
down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
//writing is performed
up(&resource); //release file
<EXIT Section>
down(&wmutex); //reserve exit section
writecount--; //indicate you're leaving
if (writecount == 0) //checks if you're the last writer
up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
up(&wmutex); //release exit section
}We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
int readCount; // init to 0; number of readers currently accessing resource
// all semaphores initialised to 1
Semaphore resourceAccess; // controls access (read/write) to the resource
Semaphore readCountAccess; // for syncing changes to shared variable readCount
Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
void writer()
{
down(&serviceQueue); // wait in line to be servicexs
// <ENTER>
down(&resourceAccess); // request exclusive access to resource
// </ENTER>
up(&serviceQueue); // let next in line be serviced
// <WRITE>
writeResource(); // writing is performed
// </WRITE>
// <EXIT>
up(&resourceAccess); // release resource access for next reader/writer
// </EXIT>
}
void reader()
{
down(&serviceQueue); // wait in line to be serviced
down(&readCountAccess); // request exclusive access to readCount
// <ENTER>
if (readCount == 0) // if there are no readers already reading:
down(&resourceAccess); // request resource access for readers (writers blocked)
readCount++; // update count of active readers
// </ENTER>
up(&serviceQueue); // let next in line be serviced
up(&readCountAccess); // release access to readCount
// <READ>
readResource(); // reading is performed
// </READ>
down(&readCountAccess); // request exclusive access to readCount
// <EXIT>
readCount--; // update count of active readers
if (readCount == 0) // if there are no readers left:
up(&resourceAccess); // release resource access for all
// </EXIT>
up(&readCountAccess); // release access to readCount
}进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
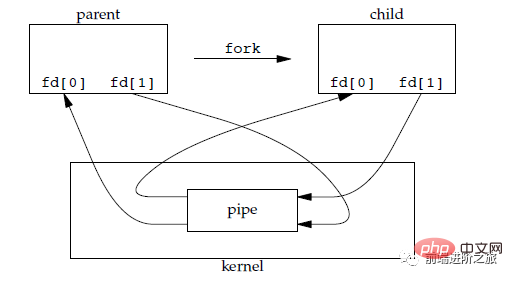
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include <unistd.h> int pipe(int fd[2]);
它具有以下限制:
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
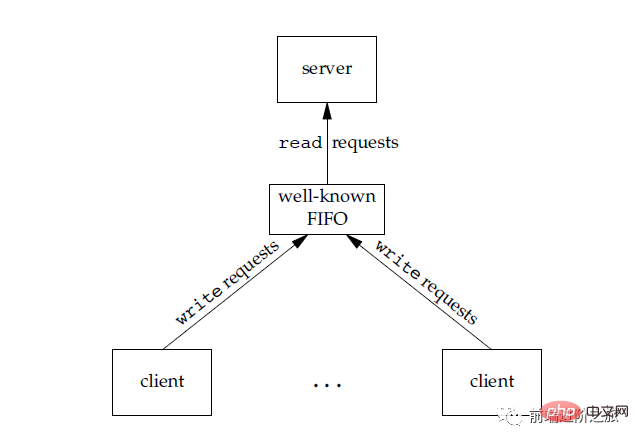
2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h> int mkfifo(const char *path, mode_t mode); int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
3. 메시지 대기열
FIFO와 비교하여 메시지 대기열은 다음과 같은 장점이 있습니다.
메시지 대기열은 읽기 및 쓰기 프로세스와 독립적으로 존재할 수 있으므로 동기화 열기 및 닫기를 피할 수 있습니다. FIFO의 파이프를 닫을 때 발생할 수 있는 어려움
- FIFO의 동기화 차단 문제를 방지하고 프로세스 자체에서 동기화 방법을 제공할 필요가 없습니다.
- 읽기 프로세스는 메시지에 따라 선택적으로 메시지를 받을 수 있습니다. 유형은 FIFO와 달리 기본적으로 수신만 가능합니다.
공유 데이터 개체에 대한 액세스를 여러 프로세스에 제공하는 데 사용되는 카운터입니다.
5. 공유 저장소를 사용하면 여러 프로세스가 특정 저장소 영역을 공유할 수 있습니다. 프로세스 간에 데이터를 복사할 필요가 없기 때문에 가장 빠른 유형의 IPC입니다.
공유 저장소에 대한 액세스를 동기화하려면 세마포어를 사용해야 합니다.
여러 프로세스가 동일한 파일을 주소 공간에 매핑하여 공유 메모리를 확보할 수 있습니다. 또한 XSI 공유 메모리는 파일을 사용하지 않지만 익명의 메모리 세그먼트를 사용합니다.
6.소켓다른 통신 메커니즘과 달리 다른 기계 간의 프로세스 통신에 사용할 수 있습니다. 가상 메모리의 목적은 실제 메모리를 더 큰 논리적 메모리로 확장하여 프로그램이 더 많은 사용 가능한 메모리를 확보할 수 있도록 하는 것입니다. 메모리를 더 잘 관리하기 위해 운영 체제는 메모리를 주소 공간으로 추상화합니다. 각 프로그램에는 여러 블록으로 나누어진 자체 주소 공간이 있으며, 각 블록을 페이지라고 합니다. 페이지는 실제 메모리에 매핑되지만 인접한 실제 메모리에 매핑될 필요는 없으며 모든 페이지가 실제 메모리에 있을 필요도 없습니다. 프로그램이 물리적 메모리에 없는 페이지를 참조하면 하드웨어는 필요한 매핑을 수행하고 누락된 부분을 물리적 메모리에 로드한 다음 실패한 명령을 다시 실행합니다. 위 설명에서 볼 수 있듯이 가상 메모리를 사용하면 프로그램이 주소 공간의 모든 페이지를 실제 메모리에 매핑하지 않아도 됩니다. 즉, 프로그램을 실행하기 위해 메모리에 로드할 필요가 없으므로 제한적입니다. 메모리 대용량 프로그램을 실행할 수 있습니다. 예를 들어, 컴퓨터가 16비트 주소를 생성할 수 있다면 프로그램의 주소 공간 범위는 0~64K입니다. 컴퓨터의 실제 메모리는 32KB에 불과하며 가상 메모리 기술을 사용하면 컴퓨터에서 64K 프로그램을 실행할 수 있습니다. 3. 메모리 관리
가상 메모리
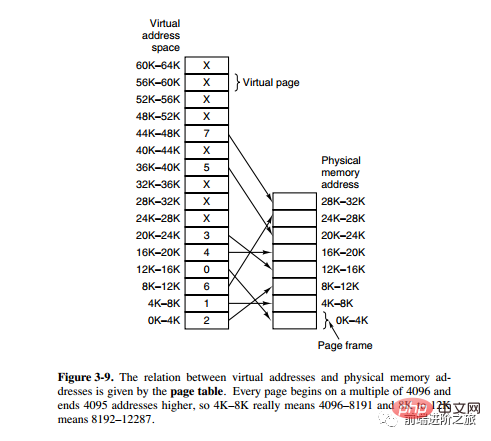
페이징 시스템 주소 매핑
메모리 관리 장치(MMU)는 주소 공간과 물리적 메모리의 변환을 관리하고, 페이지 테이블(페이지 테이블)은 페이지(프로그램 주소 공간)와 페이지 프레임을 저장합니다. (물리적 메모리 공간) 매핑 테이블입니다.
가상 주소는 두 부분으로 나누어져 있는데, 한 부분은 페이지 번호를 저장하고 다른 부분은 오프셋을 저장합니다.
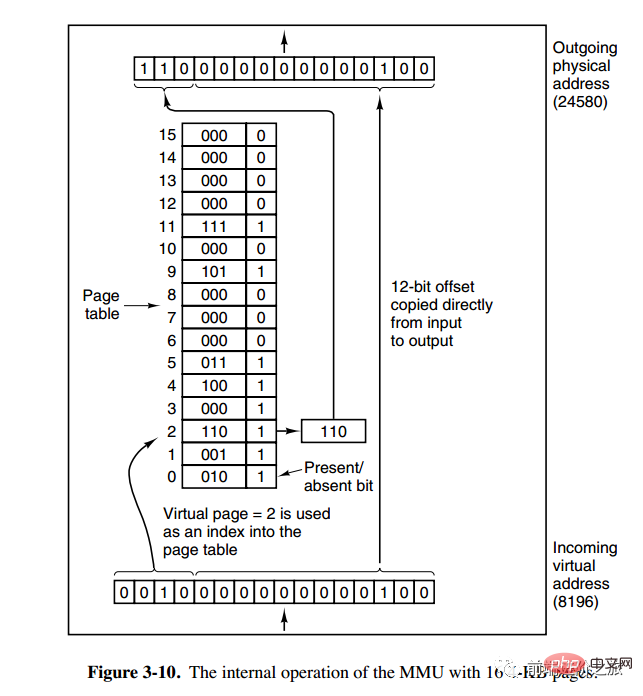
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
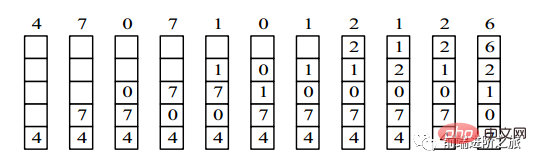
4,7,0,7,1,0,1,2,1,2,6
3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
R=0,M=0 R=0,M=1 R=1,M=0 R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. 선입선출
FIFO, First In First Out
교체 대상으로 선택한 페이지가 먼저 입력된 페이지입니다.
이 알고리즘은 자주 액세스하는 페이지를 교체하여 페이지 오류율을 높입니다.
5. 두 번째 기회 알고리즘
FIFO 알고리즘은 자주 사용되는 페이지를 대체할 수 있습니다. 이 문제를 방지하려면 알고리즘을 간단히 수정하세요.
페이지에 액세스할 때(읽기 또는 쓰기) ) 페이지의 R 비트를 1로 설정합니다. 교체가 필요한 경우 가장 오래된 페이지의 R 비트를 확인하세요. R 비트가 0이면 페이지는 오래되고 사용되지 않으며 1이면 즉시 교체할 수 있습니다. R 비트를 0으로 지우고 페이지를 링크된 목록의 끝에 두고 로드 시간을 수정합니다. 방금 로드된 것처럼 작동하고 목록의 선두부터 계속 검색합니다.

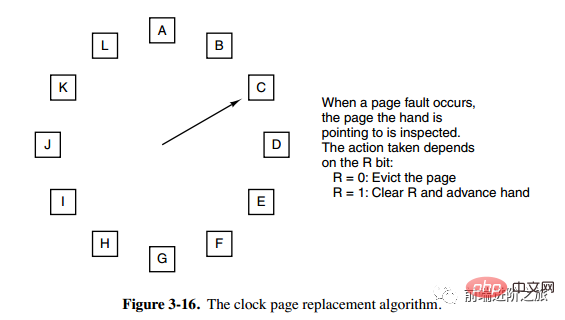
6. Clock
Clock
두 번째 기회 알고리즘은 연결 목록에서 페이지를 이동해야 하므로 효율성이 떨어집니다. 시계 알고리즘은 순환 연결 목록을 사용하여 페이지를 연결한 다음 포인터를 사용하여 가장 오래된 페이지를 가리킵니다.
Segmentation
가상 메모리는 페이징 기술을 사용합니다. 즉, 주소 공간을 고정 크기 페이지로 나누고 각 페이지를 메모리에 매핑합니다.
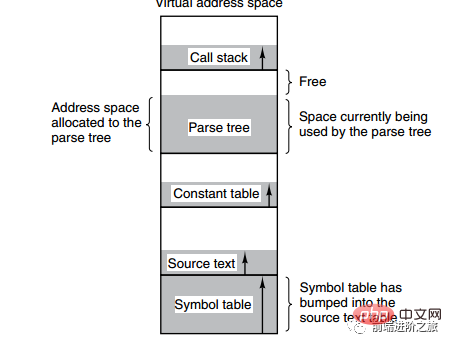
아래 그림은 컴파일 과정에서 컴파일러가 생성한 여러 테이블을 보여줍니다. 테이블 중 4개가 동적으로 증가하고 있습니다. 페이징 시스템의 1차원 주소 공간을 사용하면 동적 증가 특성으로 인해 적용 범위 문제가 발생합니다.
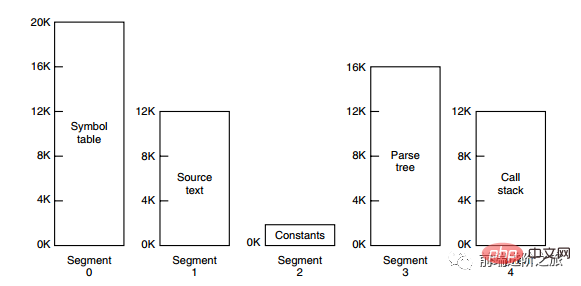
세그먼테이션 방법은 각 테이블을 세그먼트로 나누는 것이며, 각 세그먼트는 독립적인 주소 공간을 구성합니다. 각 세그먼트는 길이가 다를 수 있으며 동적으로 증가할 수 있습니다.
세그먼트 페이징
프로그램의 주소 공간은 독립적인 주소 공간을 갖는 여러 세그먼트로 나뉘며, 각 세그먼트의 주소 공간은 동일한 크기의 페이지로 나뉩니다. 이는 분할된 시스템의 공유 및 보호 기능뿐만 아니라 페이징 시스템의 가상 메모리 기능도 갖추고 있습니다.
페이징과 세분화 비교
프로그래머에 대한 투명성: 페이징은 투명하지만 세분화를 위해서는 프로그래머가 각 세그먼트를 명시적으로 나누어야 합니다.
주소 공간 차원: 페이징은 1차원 주소 공간이고 분할은 2차원입니다.
크기 변경 가능 여부: 페이지 크기는 변경할 수 없으며 세그먼트 크기는 동적으로 변경할 수 있습니다.
출현 이유: 페이징은 주로 더 큰 주소 공간을 얻기 위해 가상 메모리를 구현하는 데 사용됩니다. 분할은 주로 프로그램과 데이터를 논리적으로 독립된 주소 공간으로 분할하고 공유 및 보호를 용이하게 하기 위한 것입니다.
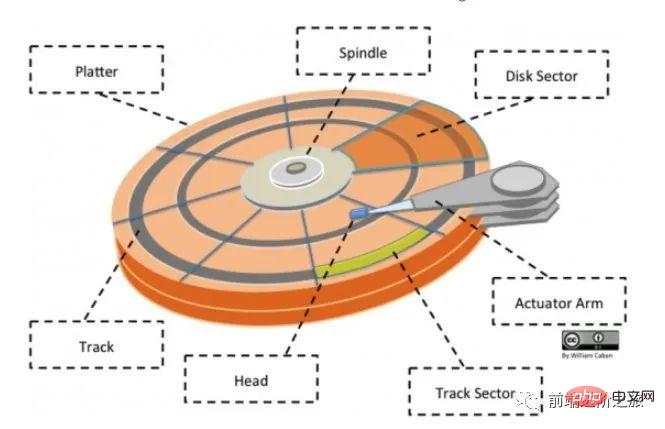
4. 장치 관리 management 디스크 구조 : 디스크에는 여러 디스크가 있습니다.
트랙 섹터: 트랙의 호 세그먼트로, 트랙은 여러 섹터를 가질 수 있으며, 현재 주로 512바이트와 4K의 두 가지 크기로 제공됩니다.
헤드: 디스크 표면에 매우 가깝고, 디스크 표면의 자기장을 전기 신호로 변환(읽기)하거나 전기 신호를 디스크 표면의 자기장으로 변환(쓰기)할 수 있습니다. 공개 계정 Linux를 검색하면 깜짝 선물 패키지를 얻기 위해 백그라운드에서 "Linux"라고 답하는 방법을 배워야 합니다.
액추에이터 암: 트랙 사이에서 자기 헤드를 이동하는 데 사용됩니다.
스핀들: 디스크 전체를 회전시킵니다.
디스크 스케줄링 알고리즘
디스크 블록을 읽고 쓰는 시간에 영향을 미치는 요소는 다음과 같습니다.
회전 시간(스핀들이 디스크 표면을 회전하여 헤드를 이동함) 해당 섹터로 이동) )
Seek 시간(브레이크 암 이동, 헤드를 해당 트랙으로 이동)
실제 데이터 전송 시간
그 중 탐색 시간은 디스크 스케줄링의 주요 목표는 평균 디스크 탐색 시간을 최소화하는 것입니다.
1. 선착순
FCFS, 선착순
스케줄링은 디스크 요청 순으로 진행됩니다.
장점은 공정성과 단순성입니다. 단점도 분명합니다. 검색에 대한 최적화가 수행되지 않아 평균 검색 시간이 더 길어질 수 있기 때문입니다.
2. 최단 탐색 시간 우선
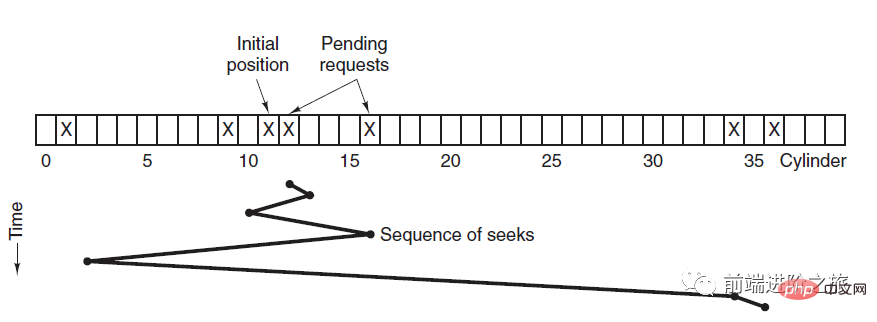
SSTF, 최단 탐색 시간 우선
현재 헤드가 위치한 트랙에 가장 가까운 트랙에 우선 순위를 부여합니다.
평균 검색 시간은 상대적으로 낮지만 충분히 공평하지 않습니다. 새로 도착한 추적 요청이 항상 대기 중인 추적 요청보다 가까우면 대기 중인 추적 요청은 영원히 기다리게 됩니다. 즉, 기아 상태가 발생합니다. 특히 양쪽 끝의 추적 요청은 기아 상태에 빠지기 쉽습니다. 저 리모콘 시스템 좀 보세요, 정말 우아해요(소스 코드 첨부)!
3. 엘리베이터 알고리즘
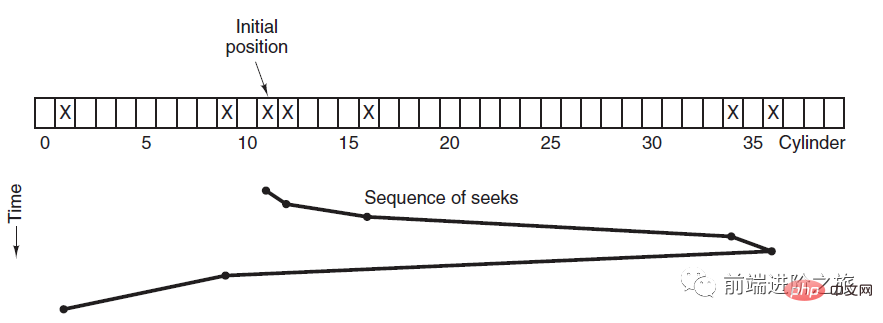
SCAN
엘리베이터는 해당 방향에 대한 요청이 없을 때까지 항상 한 방향으로 계속 운행하다가 운행 방향을 변경합니다.
엘리베이터 알고리즘(스캔 알고리즘)은 엘리베이터의 작동 프로세스와 유사합니다. 해당 방향에 미결 디스크 요청이 없을 때까지 항상 한 방향으로 디스크를 예약한 다음 방향을 변경합니다.
이동 방향을 고려하기 때문에 모든 디스크 요청이 충족되어 SSTF 기아 문제가 해결됩니다.
五、链接
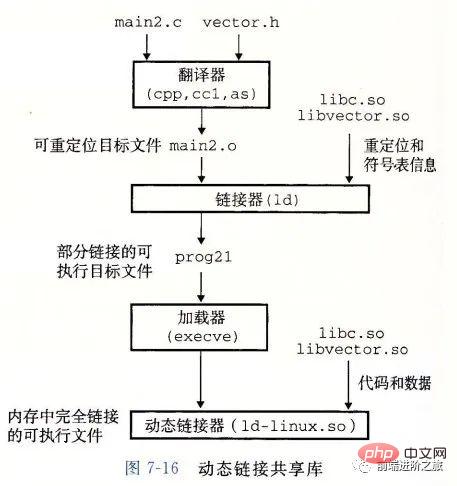
编译系统
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

预处理阶段:处理以 # 开头的预处理命令;
编译阶段:翻译成汇编文件;
汇编阶段:将汇编文件翻译成可重定位目标文件;
链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
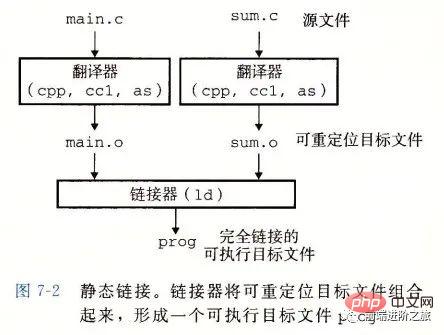
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
기호 해석: 각 기호는 함수, 전역 변수 또는 정적 변수에 해당합니다. 기호 해석의 목적은 각 기호 참조를 기호 정의와 연결하는 것입니다.
재배치: 링커는 각 기호 정의를 메모리 위치와 연결한 다음 이러한 기호에 대한 모든 참조를 수정하여 이 메모리 위치를 가리키도록 합니다.
대상 파일
실행 가능한 대상 파일: 메모리에서 직접 실행 가능
재배치 가능한 대상 파일: 다른 파일과 결합 가능 재배치 가능한 대상 파일이 병합됩니다. 연결 단계에서 실행 가능한 개체 파일을 생성합니다.
- 공유 개체 파일: 이는 동적으로 메모리에 로드되고 런타임에 연결될 수 있는 특수 재배치 가능한 개체 파일입니다.
정적 라이브러리에는 다음과 같은 두 가지 문제가 있습니다.
printf와 같은 표준 함수 라이브러리의 경우 모든 프로그램에 코드가 필요하다면 이는 엄청난 리소스 낭비가 될 것입니다.
공유 라이브러리는 정적 라이브러리의 이러한 두 가지 문제를 해결하기 위해 설계되었습니다. 일반적으로 Linux 시스템에서는 .so 접미사로 표시되며 Windows 시스템에서는 DLL이라고 합니다. 이는 다음과 같은 특징을 가지고 있습니다:
지정된 파일 시스템에는 라이브러리에 대한 파일이 하나만 있습니다. 이 파일은 라이브러리를 참조하는 모든 실행 가능 개체 파일에 의해 공유됩니다. ;
메모리에서는 공유 라이브러리의 .text 섹션(컴파일된 프로그램의 기계어 코드) 복사본을 실행 중인 다른 프로세스에서 공유할 수 있습니다.
printf와 같은 표준 함수 라이브러리의 경우 모든 프로그램에 코드가 필요하다면 이는 엄청난 리소스 낭비가 될 것입니다.
지정된 파일 시스템에는 라이브러리에 대한 파일이 하나만 있습니다. 이 파일은 라이브러리를 참조하는 모든 실행 가능 개체 파일에 의해 공유됩니다. ;
메모리에서는 공유 라이브러리의 .text 섹션(컴파일된 프로그램의 기계어 코드) 복사본을 실행 중인 다른 프로세스에서 공유할 수 있습니다.
6. 교착상태
필요조건
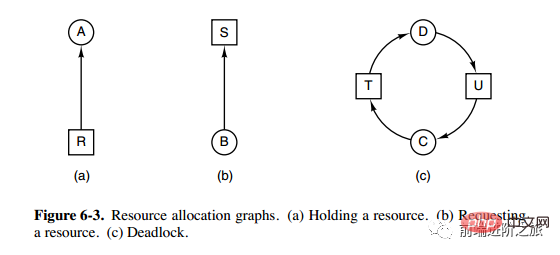
상호 배제: 각 리소스는 이미 프로세스에 할당되었거나 사용 가능합니다.
점유 및 대기: 이미 리소스를 획득한 프로세스는 새 리소스를 요청할 수 있습니다.
비선점형: 프로세스에 할당된 리소스는 강제로 선점될 수 없으며, 해당 리소스를 점유하는 프로세스에 의해서만 명시적으로 해제될 수 있습니다.
루프 대기: 루프를 형성하는 두 개 이상의 프로세스가 있으며 루프의 각 프로세스는 다음 프로세스가 차지하는 리소스를 기다리고 있습니다. ㅋㅋㅋ 교착상태 방지
교착상태 회피
-
Oostrich Strategy
모래 속에 머리를 파묻고 전혀 문제가 없는 척하세요.
교착 상태 문제를 해결하는 데 드는 비용이 매우 높기 때문에 작업 조치를 취하지 않는 타조 전략이 더 높은 성능을 달성합니다.
교착 상태가 발생하면 사용자에게 큰 영향을 미치지 않거나 교착 상태가 발생할 확률이 매우 낮을 경우 타조 전략을 사용할 수 있습니다.
Unix, Linux, Windows를 포함한 대부분의 운영 체제는 교착 상태 문제를 무시함으로써 간단히 처리합니다.
교착 상태 감지 및 교착 상태 복구
는 교착 상태를 방지하려고 시도하지 않지만 교착 상태가 감지되면 복구하기 위한 조치를 취합니다.
1. 유형별 하나의 리소스 교착 상태 감지
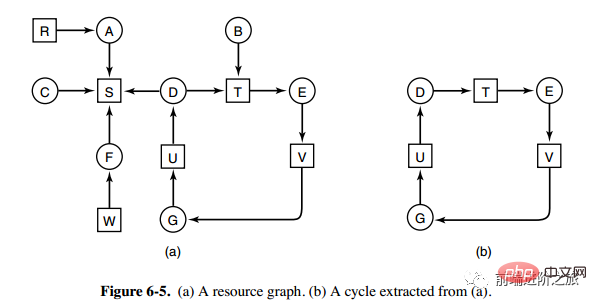
위 그림은 리소스 할당 다이어그램으로, 상자는 리소스를 나타내고 원은 프로세스를 나타냅니다. 프로세스를 가리키는 자원은 해당 프로세스에 자원이 할당되었음을 의미하고, 자원을 가리키는 프로세스는 프로세스가 자원 획득을 요청한다는 것을 의미한다.
그림 b와 같이 그림 a에서 루프를 추출할 수 있는데, 이는 루프 대기 조건을 만족하므로 교착 상태가 발생합니다.
각 리소스 유형에 대한 교착 상태 감지 알고리즘은 유향 그래프에 주기가 있는지 감지하고 노드에서 시작하여 깊이 우선 검색을 수행하고 표시된 노드를 방문하면 표시하는 방식으로 구현됩니다. 유향 그래프에 주기가 있음을 나타냅니다. 즉, 교착 상태 발생이 감지됩니다.
2. 각 유형의 여러 리소스에 대한 교착 상태 감지

위 그림에는 3개의 프로세스와 4개의 리소스가 있습니다. 각 데이터의 의미는 다음과 같습니다.
E 벡터: 총 리소스 양
벡터: 남은 리소스 양
-
C 매트릭스: 각 프로세스가 소유한 리소스 수. 각 행은 프로세스가 소유한 리소스 수를 나타냅니다. R 매트릭스: 각 프로세스 P1 및 P2에서 요청한 리소스 수입니다. 리소스가 충족되면 프로세스 P3만이 P3을 실행한 후 P3이 소유한 리소스를 해제할 수 있습니다. A = (2 2 2 0) P2가 실행될 수 있으며, P2가 소유한 리소스는 실행 후 해제됩니다. A = (4 2 2 1). P1도 실행될 수 있습니다. 모든 프로세스는 교착상태 없이 원활하게 실행됩니다.
알고리즘을 요약하면 다음과 같습니다. - 각 프로세스는 처음에 표시되지 않으며, 실행 프로세스가 표시될 수 있습니다. 알고리즘이 종료되면 표시되지 않은 모든 프로세스는 교착 상태에 빠진 프로세스입니다.
요청된 리소스가 A보다 작거나 같은 표시되지 않은 프로세스 Pi를 찾습니다.
이러한 프로세스가 발견되면 C 행렬의 i번째 행 벡터를 A에 추가하고 프로세스를 표시한 다음 다시 1로 전환합니다.
3. 교착 상태 복구
선점 복구 사용
롤백 복구 사용
Killing 프로세스를 통한 복구
교착 상태 방지
프로그램 실행 전에 교착 상태를 방지합니다.
1. 상호 배제 조건 깨기
예를 들어 스풀 프린터 기술을 사용하면 여러 프로세스가 동시에 출력할 수 있으며 실제로 물리적 프린터를 요청하는 유일한 프로세스는 프린터 데몬입니다.
2. 소유 및 대기 조건 파괴
이를 달성하는 한 가지 방법은 모든 프로세스가 실행을 시작하기 전에 필요한 모든 리소스를 요청하도록 지정하는 것입니다.
3. 비선점형 조건을 삭제합니다
4. 루프 대기를 삭제합니다.
리소스 번호를 균일하게 지정하고 프로세스는 번호 순서대로만 리소스를 요청할 수 있습니다.
교착 상태 방지
프로그램이 실행되는 동안 교착 상태를 방지하세요.
1. 보안 상태
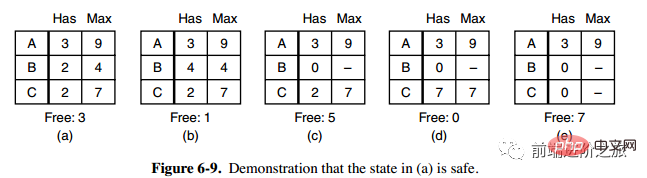
그림 a의 두 번째 열 Has는 이미 소유한 리소스 수를 나타내고, 세 번째 열 Max는 필요한 총 리소스 수를 나타내며 Free는 사용할 수 있는 리소스 수를 나타냅니다. 그림 a부터 시작하여 먼저 B가 필요한 모든 리소스를 갖게 합니다(그림 b). 작업이 완료된 후 B를 해제합니다. 이때 Free는 5가 되고(그림 c) C와 A도 같은 방식으로 실행합니다. 두 프로세스 모두 성공적으로 실행될 수 있으므로 그림 a에 표시된 상태는 안전하다고 말할 수 있습니다.
정의: 교착 상태가 발생하지 않고 모든 프로세스가 갑자기 리소스에 대한 최대 수요를 요청하더라도 각 프로세스가 완료될 때까지 실행되도록 하는 예약 순서가 여전히 있는 경우 상태는 안전하다고 합니다.
안전 상태 감지는 교착 상태 감지와 유사합니다. 왜냐하면 안전 상태에서는 교착 상태가 발생할 수 없도록 요구해야 하기 때문입니다. 다음 뱅커 알고리즘은 교착 상태 감지 알고리즘과 매우 유사하며 참조 및 비교를 위해 결합할 수 있습니다.
2. 단일 자원을 위한 은행원 알고리즘
작은 마을의 한 은행원이 고객 그룹에게 일정 금액을 약속했습니다. 알고리즘이 해야 할 일은 요청에 대한 만족이 안전하지 않은 상태에 들어갈지 여부를 결정하는 것입니다. . 그렇다면 요청을 거부하고 그렇지 않으면 할당하십시오. 위 그림의
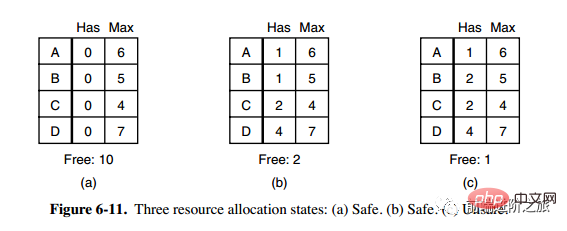
C는 안전하지 않은 상태이므로 알고리즘은 그림 c의 상태로 진입하지 않도록 이전 요청을 거부합니다.
3. 다중 자원을 위한 뱅커 알고리즘
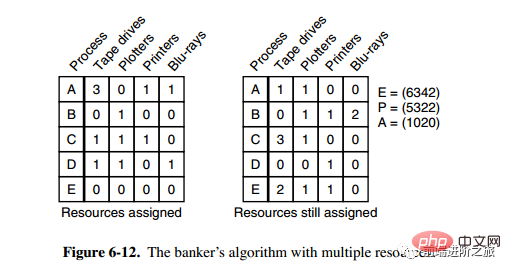
위 그림에는 5개의 프로세스와 4개의 자원이 있습니다. 왼쪽 그림은 할당된 자원을 나타내고, 오른쪽 그림은 아직 할당해야 하는 자원을 나타냅니다. 가장 오른쪽의 E, P, A는 각각 총 리소스, 할당된 리소스, 사용 가능한 리소스를 나타냅니다. 이 세 개는 특정 값이 아닌 벡터입니다. 예를 들어 A=(1020)은 각각 1/4 리소스가 남아 있음을 의미합니다. 0/2/0.
상태가 안전한지 확인하는 알고리즘은 다음과 같습니다.
오른쪽 행렬에서 벡터 A보다 작거나 같은 행이 있는지 찾습니다. 그러한 행이 없으면 시스템은 교착 상태에 빠지고 상태는 안전하지 않습니다.
이러한 줄이 발견되면 프로세스를 종료된 것으로 표시하고 할당된 리소스를 A에 추가합니다.
모든 프로세스가 종료로 표시될 때까지 위의 두 단계를 반복하면 안전 상태가 됩니다.
안전하지 않은 상태라면 이 상태에 들어가는 것을 거부해야 합니다.
위 내용은 운영 체제 요약을 자세히 설명하는 30장의 사진!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!