
매우 낮은 수준의 성능 최적화: CPU가 코드를 더 빠르게 실행하도록 합니다.
- 嵌入式Linux充电站앞으로
- 2023-07-31 15:44:431074검색
캐시가 성능에 미치는 영향
먼저 CPU가 메모리에 액세스할 때 메모리에 직접 액세스하지 않고 먼저 캐시(캐시). CPU访问内存时,不是直接去访问内存的,而是先访问缓存(cache)。
当缓存中已经有了我们要的数据时,CPU就会直接从缓存中读数据,而不是从内存中读。
CPU和缓存的关系如下:
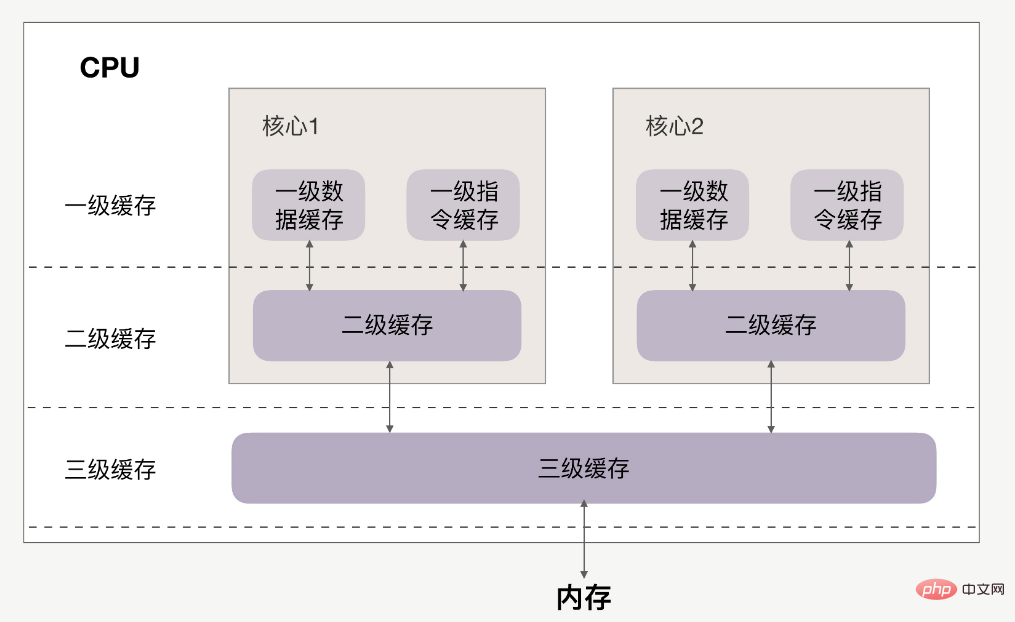
缓存分为一级、二级、三级,最靠近CPU的是一级缓存,最远的是内存,离CPU越近速度越快。
访问速度上,L1>L2>L3>内存,缓存比内存速度要快得非常多。
如果CPU操作的数据在缓存中,则直接从缓存中读取,这个过程就叫缓存命中。
因此提升性能的关键,就是要提高缓存命中率。下面来看如何提高缓存命中率。
提高数据缓存命中率
来看一个实例,有一个N*N
CPU는 메모리에서 읽는 대신 캐시에서 직접 데이터를 읽습니다.
CPU 및 캐시 관계는 다음과 같습니다: 🎜N*N 2차원 배열, 예: 🎜int array[N][N];🎜이제 두 개의 for 루프를 사용하여 이 배열을 탐색하고 각 요소의 내용에 액세스합니다. 🎜
for(i = 0; i < N; i+=1)
{
for(j = 0; j < N; j+=1)
{
array[i][j] = 0;//速度快
//array[j][i] = 0;//速度慢
}
}有两种访问方式:array[i][j]和array[j][i]。
在性能上,array[i][j]会比array[j][i]执行地更快,并且速度相差8倍。
1、速度更快的原因
首先数组在内存上是连续的,假设N等于2,则array[2][2]在内存中的排布是:
array[0][0]、array[0][1]、array[1][0]、array[1][1]、
以array[i][j]方式访问,即按内存中的顺序访问,当访问array[0][0]时,CPU就已经把数组的剩余三个数据(array[0][1]、array[1][0]、array[1][1])加载到了缓存当中。
当继续访问后三个元素时,CPU会直接从缓存中读取数据,而不需要从内存中读取(cache命中)。因此速度会很快。
如果以array[j][i]方式访问数组,则访问顺序为:
array[0][0]、array[1][0]、array[0][1]、array[1][1]
此时访问顺序是跳跃的,并不是按数组在内存中的的排布顺序来访问。如果N很大的话,那么执行array[j][i]时,array[j+1][i]的内容是没法读进缓存里的,等到要访问array[j+1][i]时就只能从内存中读取。
所以array[j][i]的速度会慢于array[i][j]。
2、速度相差8倍的原因
刚刚提到,如果这个二维数组的N很大,array[j+1][i]的内容是没法读到缓存里的,那CPU一次能够将多少数据加载进缓存里呢?
这个其实跟cache line有关,cache line代表缓存一次载入数据的大小。可以通过以下命令查看cache line为多大:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size

cache line为64,代表CPU缓存一次数据的大小为64字节。
배열[0][0], 요소가 차지하는 바이트 수가 64바이트, CPU 후속 요소는 순서대로 보완되며 다음 배열[0 ][1], 배열 [1] [0]충분할 때까지 캐시에 있는 콘텐츠를 함께 읽습니다.64바이트. array[0][0]时,该元素所占用的字节数不到64字节,CPU就会按顺序补足后续元素,就会把后面的array[0][1]、array[1][0]等内容一起读到缓存里,直到凑够64字节。
正因如此,按顺序访问的array[i][j]才会比不按顺序访问的array[j][i]
배열[i ][j ]는 순서 없이 액세스되는 것보다 더 좋습니다.array[j][i]는 빠릅니다. 🎜속도가 왜 8倍。我们知道,二维数组中,第一维元素放的是地址,第二维元素才是数据。64位系统中,地址占用8个字节,cache line为64的话,地址已经占用了8字节,那每个cache line最多能载入不到8个二维数组元素,N很大的情况下,他们的性能平均下来就会相差将近8배 다른지 살펴보겠습니다.
결론: 메모리 레이아웃 순서로 액세스하면 데이터 캐시 적중률을 향상시킬 수 있습니다.
명령어 캐시 적중률 향상
앞서 이야기한 것은 데이터 캐시에 관한 것인데, 이제 명령어 캐시 적중률을 향상시키는 방법을 살펴보겠습니다.
有一个数组array,数组元素内容为0-255之间的随机数:
int array[N]; for (i = 0; i < TESTN; i++) array[i] = rand() % 256;
现在,要把数组中数字小于128的元素置为0,并且对数组排序。
大家应该都能想到,有两种方法:
先遍历数组,把小于128的元素置为0,然后排序。 先对数组排序,再遍历数组,把小于128的元素置为0。
for(i = 0; i < N; i++) {
if (array [i] < 128)
array[i] = 0;
}
sort(array, array +N);先排序后遍历的速度会比较快,为什么?
因为在for循环中会执行很多次if分支判断语句,而CPU拥有分支预测器。
如果分支预测器可以预测接下来要执行的分支(执行if还是执行else),那么就可以提前把这些指令放到缓存中,CPU执行的时候就会很快了。
如果一个数组的内容完全随机的话,那么分支预测器就很难进行正确的预测。但如果数组内容是有序的,它就会根据历史命中数据的情况对未来进行预测,那命中率就会很高,所以先排序后遍历的速度会比较快。
怎么验证指令缓存命中率的情况呢?
재Linux下,可以使用Perf性能分析工具进行验证。통법-e选项,指定분기 로드 와branch-loads-misses事件,可以分别统计流分支预测成功的次数 강한> 및분할 방식, 일반적으로L1-icache-load-misses사건 발생기 : 14px; 패딩: 2px 4px; 테두리 반경: 4px; 여백 오른쪽: 2px; 여백 왼쪽: 2px; 배경색: rgba(27, 31, 35, 0.05); 글꼴 계열: "연산자 모노", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);">성능工具能否统计这些事件取决于CPU是否支持以及芯書原厂是否去实现了该接口,我看很多촌놈이 없습니다. -오른쪽: 2px;여백-왼쪽: 2px;배경색: rgba(27, 31, 35, 0.05); 글꼴 계열: "Operator Mono", Consolas, Monaco, Menlo, monospace;단어 나누기: 모두 중단 ;색상: rgb(239, 112, 96);">가능성 있음 및가능성 없음宏,并且它们도시출현만약语句中,这两个宏的작업용就是为了提高性能。Linux下,可以使用Perf性能分析工具进行验证。通过-e选项,指定branch-loads和branch-loads-misses事件,可以分别统计出分支预测成功的次数和分支预测失败的次数,通过L1-icache-load-misses事件也能统计一级缓存中指令未命中的次数。但是,这些性能事件都属于硬件事件,perf工具能否统计这些事件取决于CPU是否支持以及芯片原厂是否去实现了该接口,我看很多都是不支持或者没实现的。
另外,在Linux内核中,可以看到大量的likely和unlikely宏,并且它们都出现if语句中,这两个宏的作用就是为了提高性能。
这是显示预测概率的宏,如果你觉得CPU的分支预测不准,但if中条件为"真"的概率很高,那么你就可以使用likely()
if中条件为"真"的概率很高,那么你就可以使用likely() 括起来,以此提升性能。🎜#define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0) if (likely(a == 1)) …
提高多核CPU下的缓存命中率
首先要清楚,一级缓存、二级缓存是每颗核心独享的,三级缓存则面向所有核心。
但多核CPU下的系统有个特点,存在CPU核心迁移问题。
예를 들어 프로세스 A在时间片内使用CPU核心1,自然填满了CPU核心1的一、二级缓存,但基于调度策略,时间片结束后,CPU核心1会被让出,防止某些进程饿死。如果此时CPU核心1很忙,那么进程A很可能就会被调度到CPU核心2上运行。这样的话,无论我们怎么优化代码,也只能在一个时间片内高效地使用CPU첫 번째 및 두 번째 수준 캐시는 다음 타임 슬라이스에서 캐시 효율성 문제에 직면하게 됩니다.
이 경우 프로세스를 CPU에 바인딩하여 실행하는 것을 고려할 수 있습니다.
perf 도구도 이러한 종류의 성능을 제공합니다. 이벤트 통계는 cpu-마이그레이션 , 그것은CPU 마이그레이션 수 perf工具也提供了这类性能事件的统计,叫cpu-migrations,即CPU迁移次数。CPU迁移次数多的话,缓存效率就会低。
将进程绑定CPU运行,性能也会得到提升。
总结
这些是CPU입니다. CPU 마이그레이션 수가 많으면 캐시 효율성이 낮아집니다.
요약
이것은CPU 캐시가 성능에 미치는 영향, 이는 이미 매우 낮은 수준입니다. 어떤 프로그래밍 언어가 유효한지에 관계없이 성능 최적화. 캐싱을 정말 이해하고, 기본 레이어에 대한 이해가 큰 도움이 될 것이라고 믿습니다. - 데이터 캐시 적중률 향상
: 연속적인 메모리 데이터를 순차적으로 연산 - 명령어 캐시 적중률 향상
: 정규 조건부 분기
위 내용은 매우 낮은 수준의 성능 최적화: CPU가 코드를 더 빠르게 실행하도록 합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!