
一篇文章带你搞定Python中urllib库(操作URL)
- Go语言进阶学习앞으로
- 2023-07-25 14:08:04994검색
1. URL 조작
urllib은 URL을 조작하기 위한 일련의 함수를 제공합니다. 관련 콘텐츠를 분류합니다.
2.Get()
urllib's요청request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的URLhttps://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078 모듈은 URL 콘텐츠를 쉽게 캡처할 수 있습니다. 즉, 지정된 페이지에 GET 요청을 보낸 다음 HTTP 응답을 반환합니다. 예를 들어 Douban
https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078🎜🎜크롤링하고 응답 반환: 🎜🎜🎜🎜
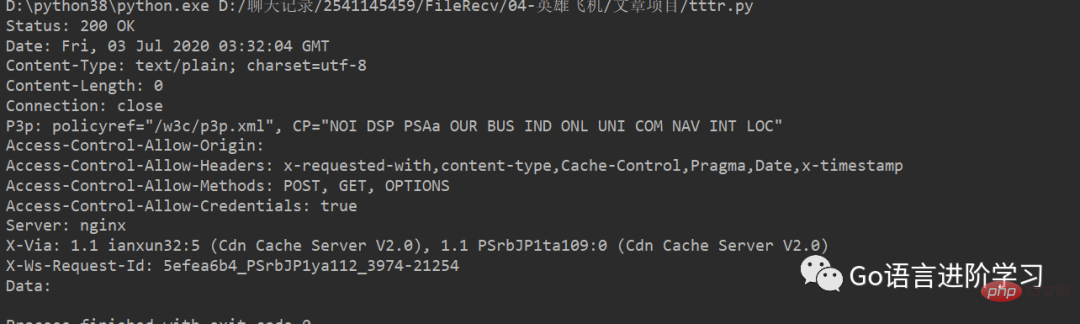
from urllib import request
with request.urlopen('https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', data.decode('utf-8'))HTTP 응답의 헤더와 JSON 데이터를 볼 수 있습니다.
GET 요청을 보내는 브라우저를 시뮬레이션하려면 요청Request对象,通过往Request对象添加HTTP头,就可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:
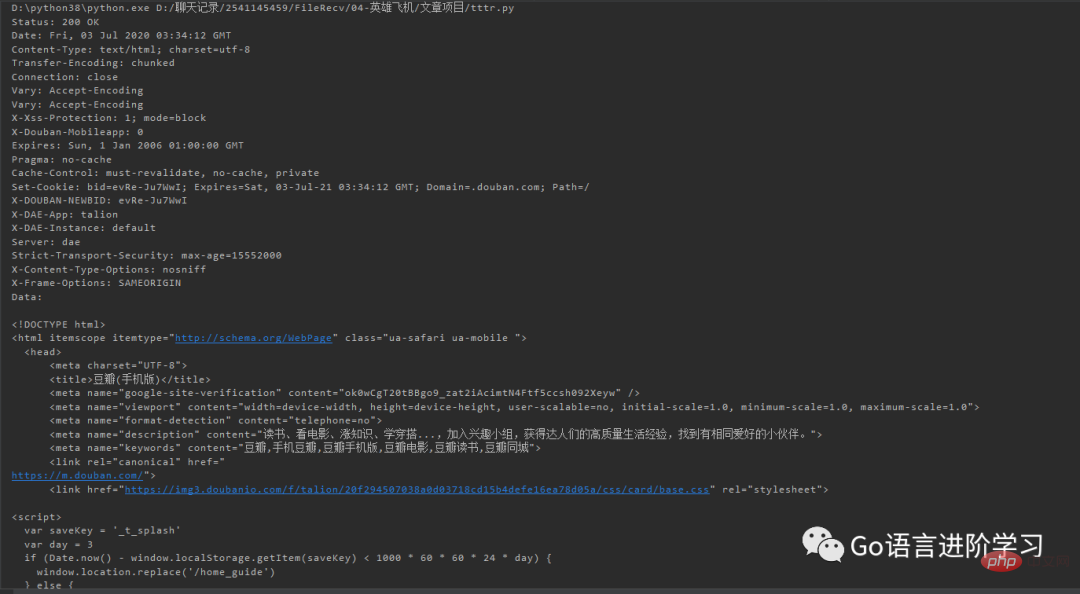
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))这样豆瓣会返回适合iPhone的移动版网页:
三、Post()
如果要以POST发送一个请求,只需要把参数data 객체, 요청 code><br>
from urllib import request, parse
print('Login to weibo.cn...')
#电子邮件
email = input('Email: ')
#密码
passwd = input('Password: ')
#相关的参数
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
#网址请求
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
#构造User-Agent
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))🎜🎜이러한 방식으로 Douban은 iPhone에 적합한 웹 페이지의 모바일 버전을 반환합니다: 🎜🎜🎜🎜 🎜🎜🎜🎜
🎜🎜🎜🎜
🎜Three, Post()🎜
🎜 🎜
🎜🎜POST로 요청을 보내려면 매개변수만 입력하면 됩니다 🎜🎜data🎜🎜는 바이트 단위로 전달됩니다. 🎜🎜🎜
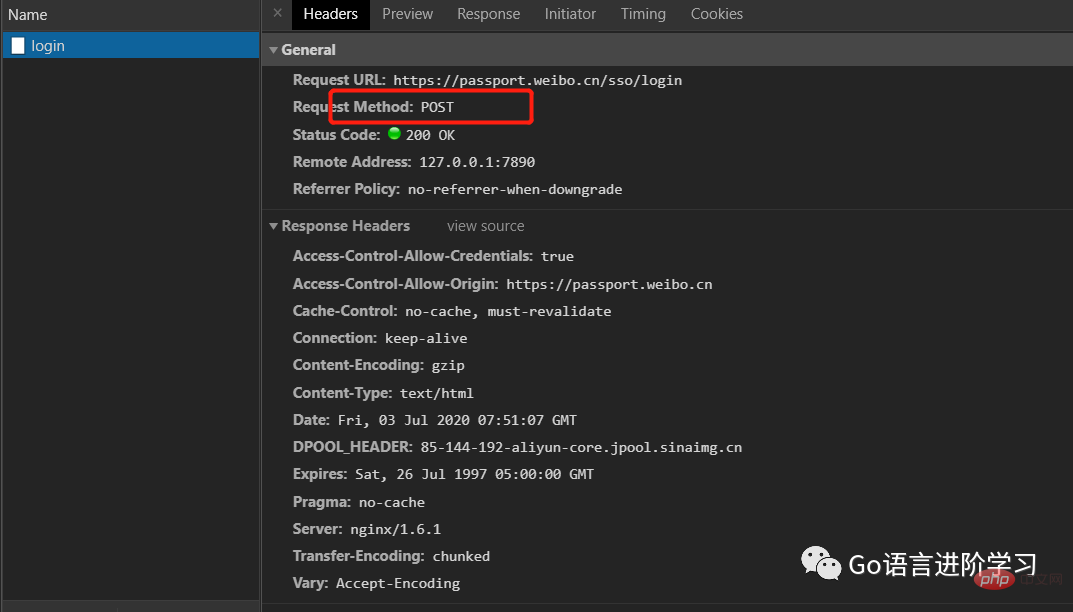
模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
from urllib import request, parse
print('Login to weibo.cn...')
#电子邮件
email = input('Email: ')
#密码
passwd = input('Password: ')
#相关的参数
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
#网址请求
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
#构造User-Agent
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
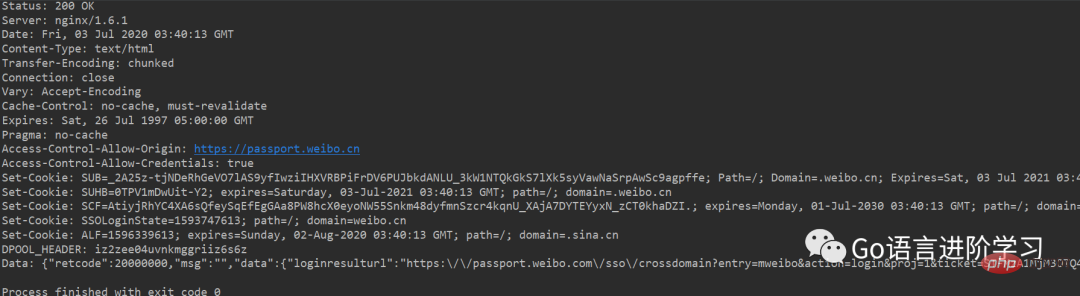
print('Data:', f.read().decode('utf-8'))如果登录成功,获得的响应如下:
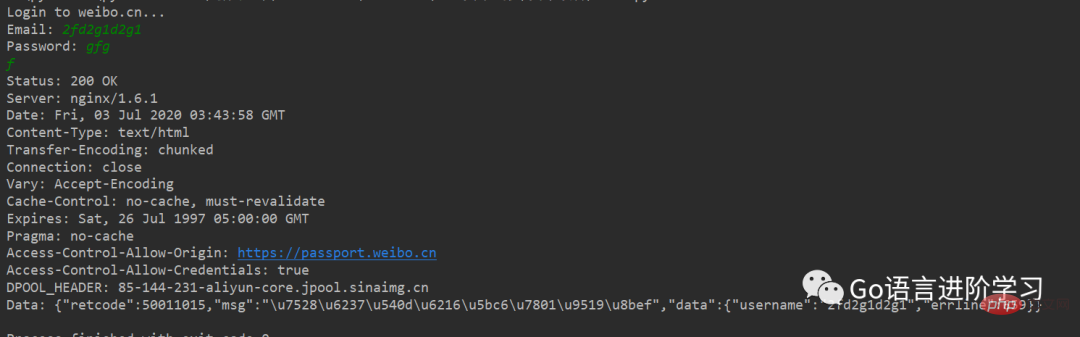
如果登录失败,获得的响应如下:
四、Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,需要利用ProxyHandler来处理,示例代码如下:
import urllib.request
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"https": "27.191.234.69:9999"})
nullproxy_handler = urllib.request.ProxyHandler({})
# 定义一个代理开关
proxySwitch = True
# 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
# 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request)
# 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urllib.request.urlopen(request)
# 获取服务器响应内容
html = response.read().decode("utf-8")
# 打印结果
print(html)如果代理成功返回网址的信息。
URL이 잘못되었거나 프록시 주소가 잘못된 경우 아래 인터페이스로 돌아가세요.

5. 요약
Python 언어를 사용하면 누구나 Python을 더 잘 배울 수 있습니다. urllib에서 제공하는 기능은 프로그램을 사용하여 다양한 HTTP 요청을 수행하는 것입니다. 특정 기능을 완료하기 위해 브라우저를 시뮬레이션하려면 요청을 브라우저로 위장해야 합니다. 위장 방법은 먼저 브라우저에서 보낸 요청을 모니터링한 다음 브라우저의 요청 헤더를 기반으로 이를 위장하는 것입니다. User-Agent 헤더는 브라우저를 식별하는 데 사용됩니다.
위 내용은 一篇文章带你搞定Python中urllib库(操作URL)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!