
golang性能诊断看这篇就够了
- Go语言进阶学习앞으로
- 2023-07-24 16:18:331906검색
타임 슬라이스가 모두 소모되고 CPU는 정상적으로 다음 작업을 예약합니다.

작업 실행 시 I/O 차단이 발생하고 현재 작업을 일시 중지한 후 다음 작업으로 전환
사용자 코드 적극적으로 정지됨 현재 작업이 CPU를 포기합니다
멀티태스킹이 리소스를 점유하고 사용할 수 없기 때문에 일시 중지됩니다하드웨어 인터럽트
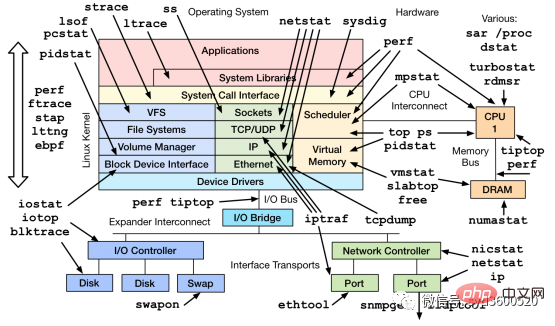
1.2 메모리
운영 체제 관점에서 볼 때 메모리는 응용 프로세스가 충분한지 여부를 고려하는 free –m 명령을 사용할 수 있습니다. 메모리 사용량을 확인하려면
top 명령을 통해 프로세스에서 사용하는 가상 메모리 VIRT 및 물리적 메모리 RES를 볼 수 있습니다. VIRT = SWAP + RES 공식에 따라 특정 응용 프로그램에서 사용하는 스왑 파티션(Swap)을 계산할 수 있습니다. 스왑 파티션은 애플리케이션 성능에 영향을 미칩니다. 스왑성 값을 최대한 작게 조정할 수 있습니다.
1.3 I/O
I/O에는 디스크 I/O와 네트워크 I/O가 포함됩니다. 일반적으로 디스크에는 I/O 병목 현상이 발생하기 쉽습니다. iostat를 통해 디스크의 읽기, 쓰기 상태를 확인할 수 있고, CPU의 I/O 대기를 통해 디스크 I/O의 정상 여부를 확인할 수 있습니다.
디스크 I/O가 항상 높은 상태라면 디스크가 너무 느리거나 결함이 있어 성능 병목 현상이 발생했다는 의미입니다. 애플리케이션 최적화 또는 디스크 교체가 필요합니다.
top, ps, vmstat, iostat 등과 같이 일반적으로 사용되는 명령 외에도 mpstat, tcpdump, netstat, pidstat, sar 및 기타 Linux 성능 진단 도구와 같이 시스템 문제를 진단할 수 있는 다른 Linux 도구가 있습니다.
프로파일링은 프로그램 실행 중에 특정 이벤트를 수집하고 샘플링 통계를 수집하여 문제의 정확한 위치를 쉽게 찾아냅니다.
추적은 코드를 탐지하는 방법으로, 분석에 사용됩니다. 호출 또는 사용자 요청의 수명 전체에 걸쳐 지연되며 여러 Go 프로세스에 걸쳐 있을 수 있습니다.
2.1 프로파일링
1. 먼저 프로파일링 코드는
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("0.0.0.0:9090", nil))
}()
...
}2에 저장됩니다. 힙 정보 저장 등 특정 시점에 프로필을 저장합니다.
3. go 도구 pprof를 사용하면 위의 힙 정보를 분석하는 등 저장된 프로필 스냅샷을 분석할 수 있습니다. 함수 실행 문제C 과도한 PU 사용량 문제
curl http://localhost:6060/debug/pprof/heap --output heap.tar.gz
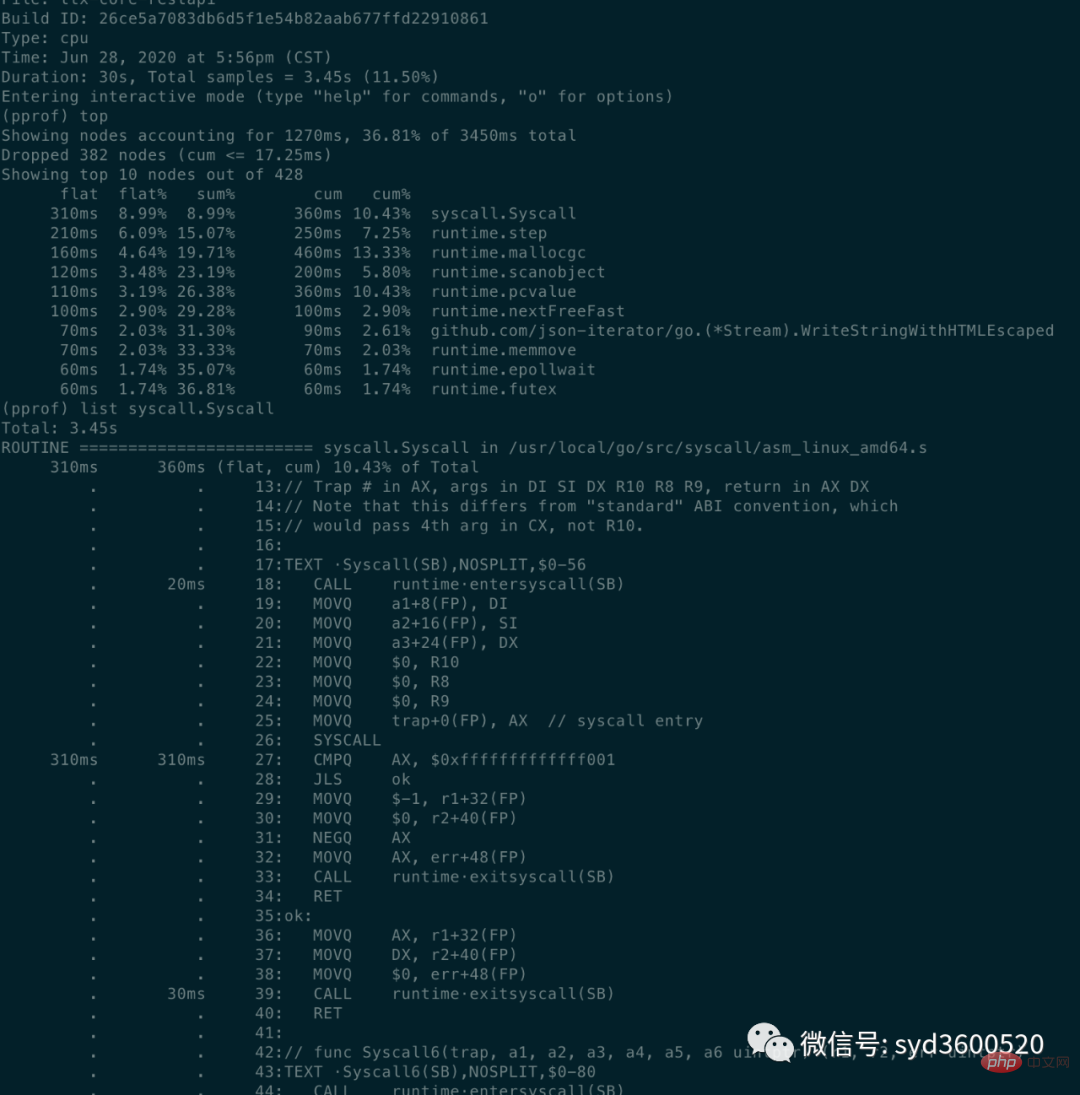
명령줄 방식: 공통 명령 상위 목록 추적
top: 메모리 양 또는 CPU 점유량 기준으로 정렬된 상위 10개 함수 정보 보기
flat: 현재 함수가 CPU 시간을 차지합니다(호출하는 다른 함수는 제외
flat%: 총 CPU 시간 중 현재 함수가 사용하는 CPU 비율sum%: 각 이전 줄의 균일 백분율의 합
cum: 누적량, 현재 함수와 하위 함수가 CPU를 차지하는 시간
- cum%: 전체의 백분율로 나타낸 누적량
cum>=flat
list: 查看某个函数的代码 以及该函数每行代码的指标信息
traces:打印所有函数调用栈 以及调用栈的指标信息
UI界面方式:从服务器download下生成的sample文件
go tool pprof -http=:8080 pprof.xxx.samples.cpu.001.pb.gz
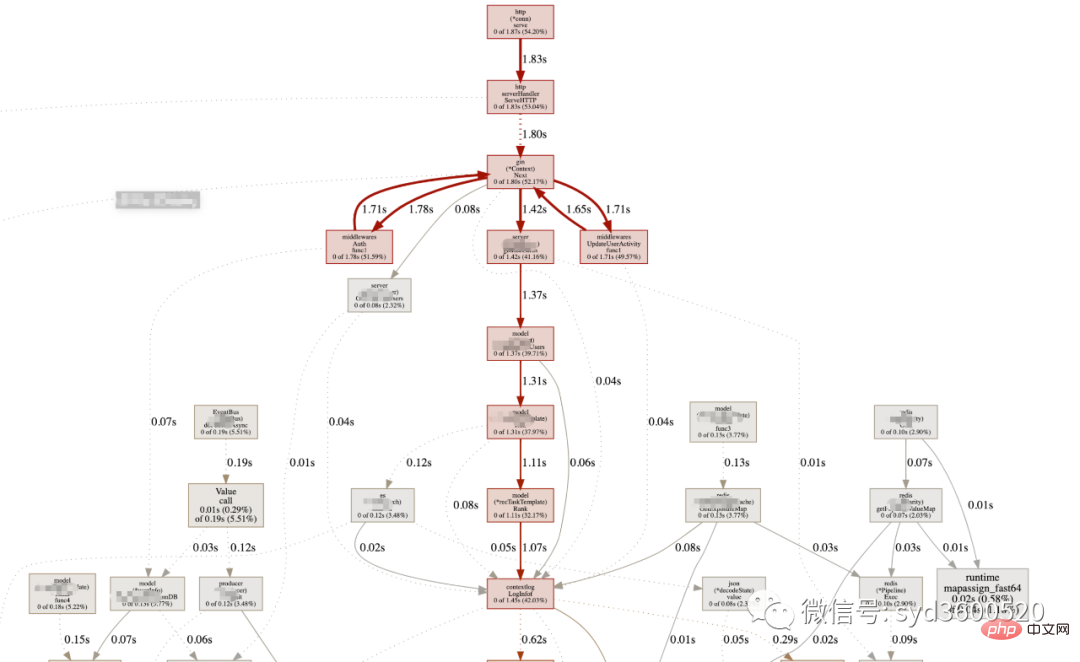
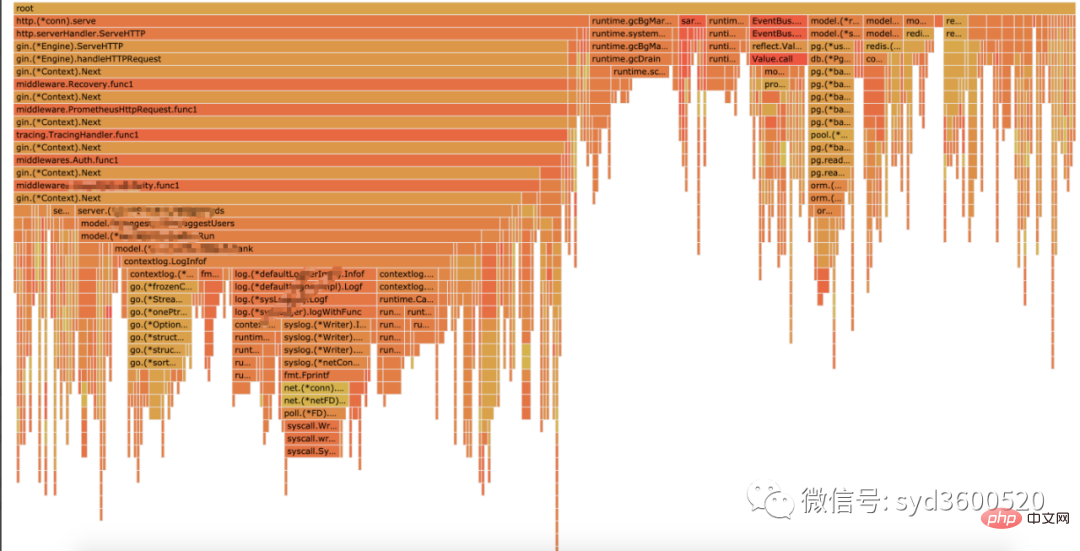
Flame graph很清晰得可以看到当前CPU被哪些函数执行栈占用
1.2 Heap Profiling
go tool pprof http://localhost:6060/debug/pprof/heap?second=10
命令行 UI查看方式 同理
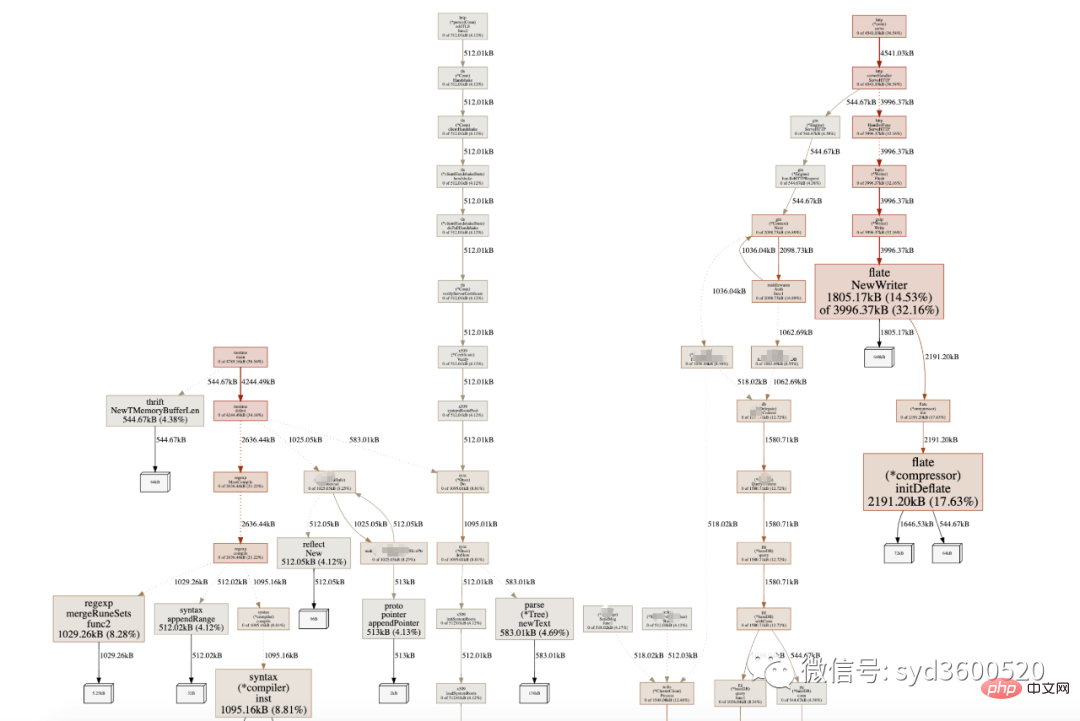

graph中方框越大 占用内存越多 火焰图 宽度越大 占用内存越多
SAMPLE->inuse_objects可以查看当前的对象数量 这个参数对于分析gc线程占用较高cpu时很有用处 它侧重查看对象数量
inuse_space图可以查看具体的内存占用
毕竟对于10个100m的对象和1亿个10字节的对象占用内存几乎一样大,但是回收起来一亿个小对象肯定比10个大对象要慢很多。
go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap : 分析应用程序的常驻内存占用情况 (默认) go tool pprof -alloc_objects http://localhost:6060/debug/pprof/heap: 分析应用程序的内存临时分配情况
1.3 并发请求问题 查看方式跟上面类似。
go tool pprof http://localhost:6060/debug/pprof/goroutine go tool pprof http://localhost:6060/debug/pprof/block go tool pprof http://localhost:6060/debug/pprof/mutex
2.2 tracing
trace并不是万能的,它更侧重于记录分析 采样时间内运行时系统具体干了什么。
收集trace数据的三种方式:
1. 使用runtime/trace包 调用trace.Start()和trace.Stop()
2. 使用go test -trace=28897b20adb25fbae118a3f80f538dec测试标识
3. 使用debug/pprof/trace handler 获取运行时系统最好的方法
例如,通过
go tool pprof http://localhost:6060/debug/pprof/trace?seconds=20 > trace.out
获取运行时服务的trace信息,使用
go tool trace trace.out
会自动打开浏览器展示出UI界面
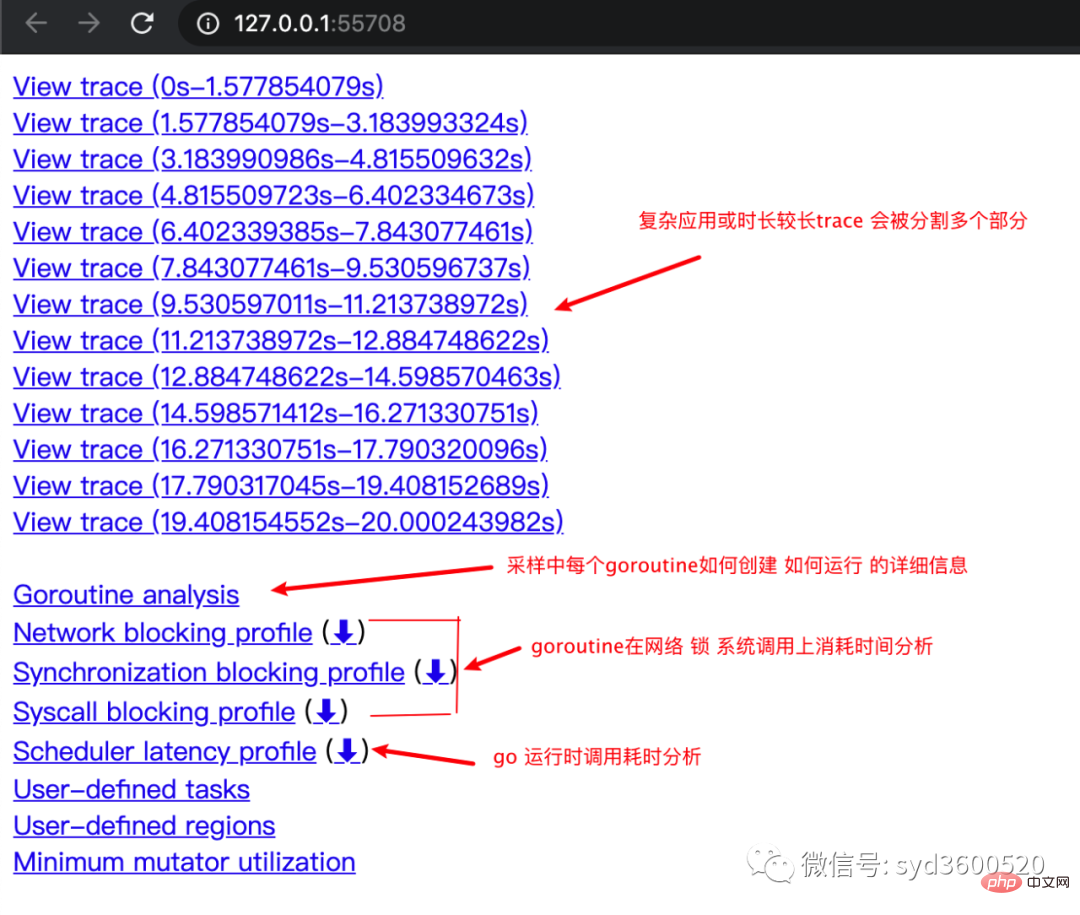
其中trace view 只能使用chrome浏览器查看,这里go截止1.14版本存在一个 bug,解决办法如下:
go tool trace trace.out 无法查看trace view go bug:https://github.com/golang/go/issues/25151 mac 解决版本:安装gotip go get golang.org/dl/gotip gotip download then 使用 gotip tool trace trace.out即可
获取的trace.out 二进制文件也可以转化为pprof格式的文件
go tool trace -pprof=TYPE trace.out > TYPE.pprof Tips:生成的profile文件 支持 network profiling、synchronization profiling、syscall profiling、scheduler profiling go tool pprof TYPE.pprof
使用gotip tool trace trace.out可以查看到trace view的丰富操作界面:
操作技巧:
ctrl + 1 选择信息
ctrl + 2 移动选区
ctrl + 3 放大选区
ctrl + 4 指定选区区间
shift + ? 帮助信息
AWSD跟游戏快捷键类似 玩起来跟顺手
整体的控制台信息 如下图:
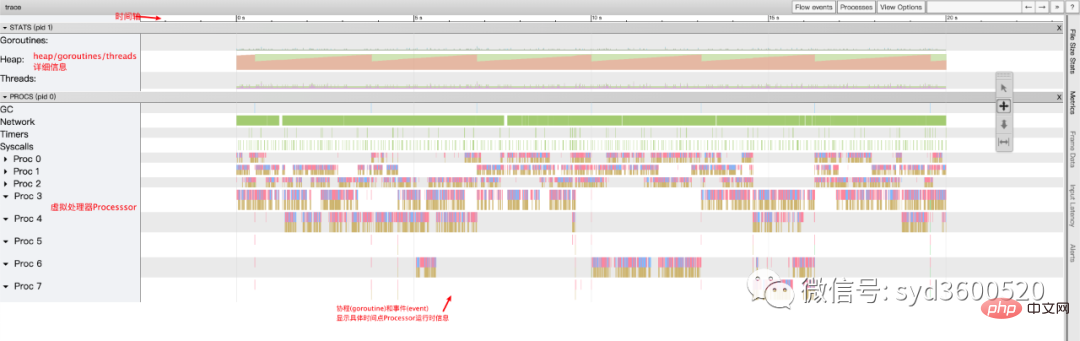
时间线: 显示执行的时间单元 根据时间的纬度不同 可以调整区间
堆: 显示执行期间内存的分配和释放情况
协程(Goroutine): 显示每个时间点哪些Goroutine在运行 哪些goroutine等待调度 ,其包含 GC 等待(GCWaiting)、可运行(Runnable)、运行中(Running)这三种状态。
goroutine区域选中时间区间
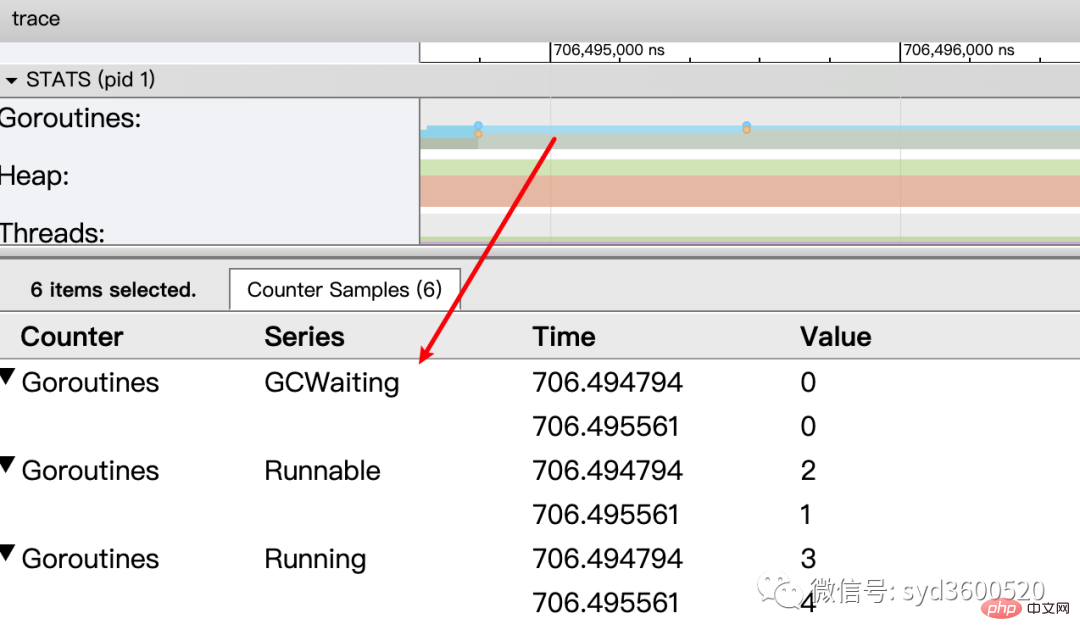
OS线程(Machine): 显示在执行期间有多少个线程在运行,其包含正在调用 Syscall(InSyscall)、运行中(Running)这两种状态。
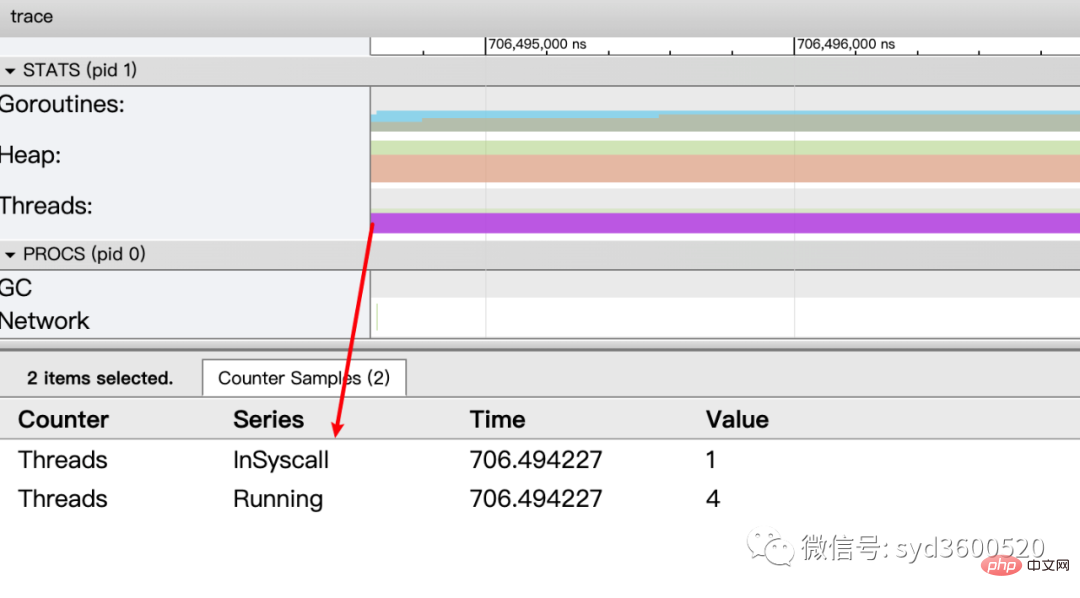
虚拟处理器Processor: 每个虚拟处理器显示一行,虚拟处理器的数量一般默认为系统内核数。数量由环境变量GOMAXPROCS控制
协程和事件: 显示在每个虚拟处理器上有什么 Goroutine 正在运行,而连线行为代表事件关联。
每个Processor分两层,上一层表示Processor上运行的goroutine的信息,下一层表示processor附加的事件比如SysCall 或runtime system events
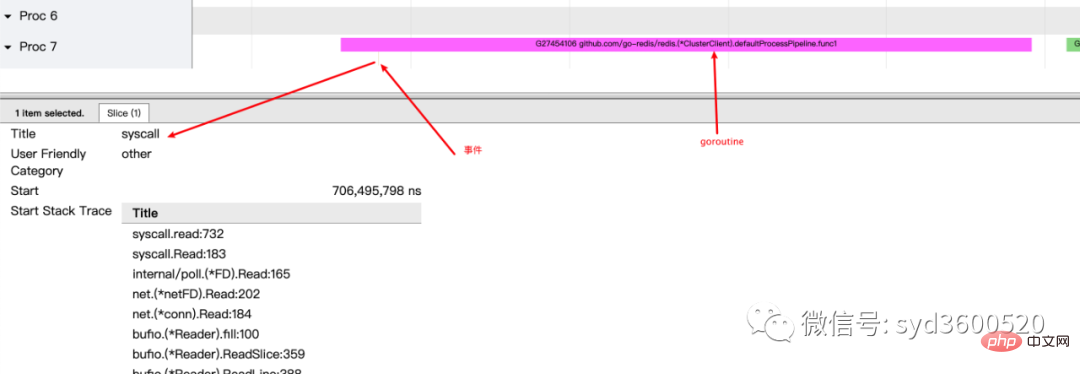
ctrl+3 放大选区,选中goroutine 可以查看,特定时间点 特定goroutine的执行堆栈信息以及关联的事件信息
goroutine analysis
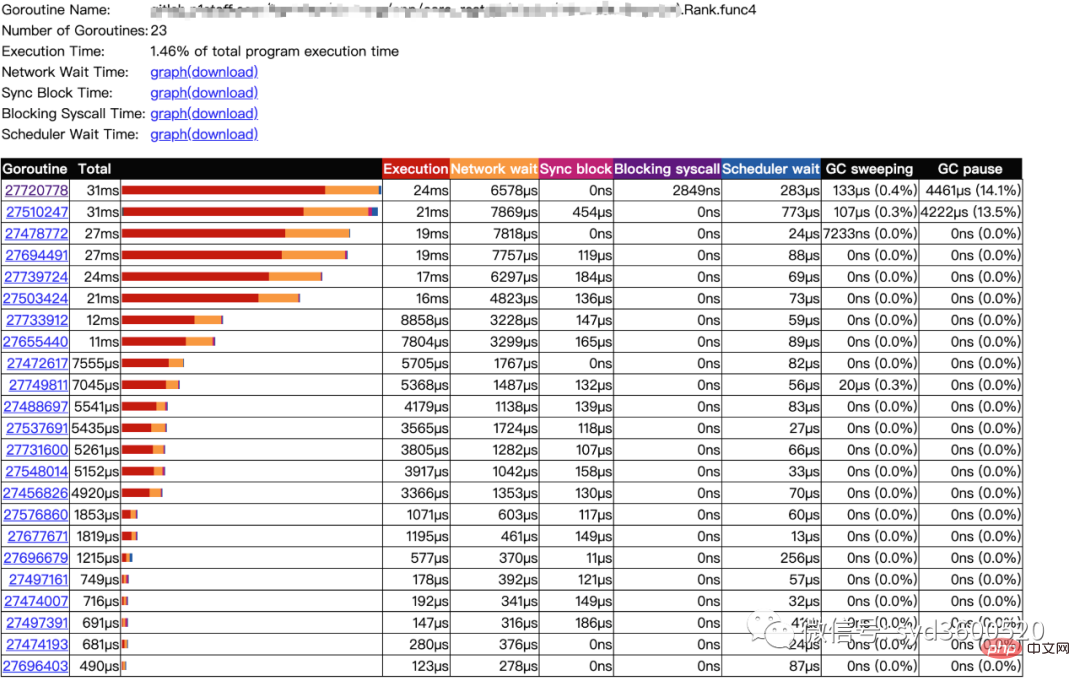
点击goroutine的id 可以跳到trace view 详细查看goroutine具体干了什么
| 名称 |
含义 |
| Execution | 执行时间 |
| Network wait | 网络等待时间 |
| Sync Block | 同步阻塞时间 |
| Blocking syscall | 系统调用阻塞时间 |
| Scheduler wait | 调度等待时间 |
| GC Sweeping | GC清扫时间 |
| GC Pause | GC暂停时间 |
实践 一个延迟问题诊断
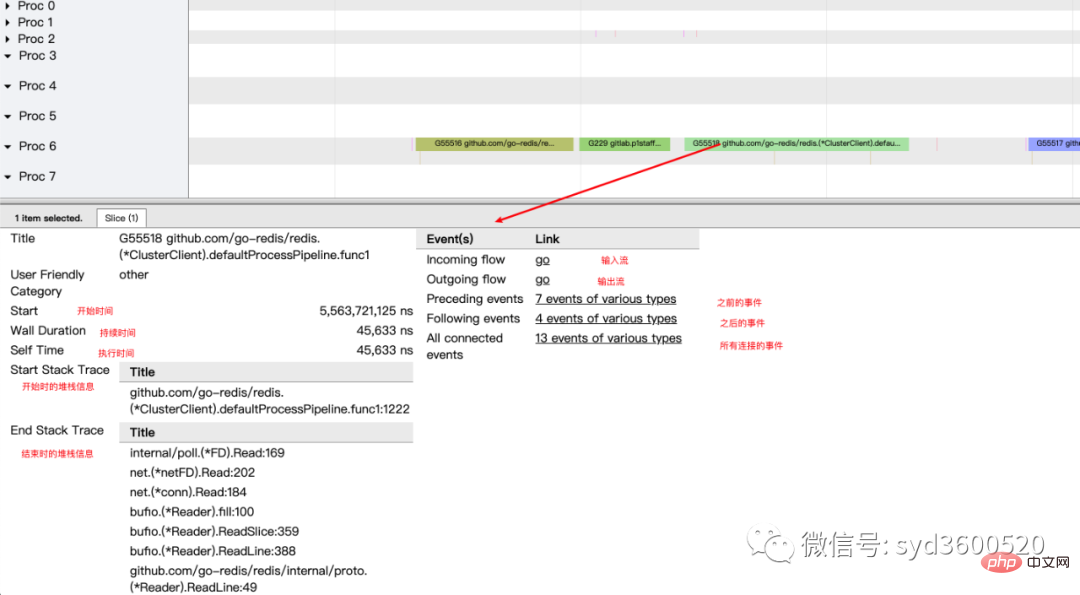
当我们一个执行关键任务的协程从运行中被阻塞。这里可能的原因:被syscall阻塞 、阻塞在共享内存(channel/mutex etc)、阻塞在运行时(如 GC)、甚至有可能是运行时调度器不工作导致的。这种问题使用pprof很难排查,
使用trace只要我们确定了时间范围就可以在proc区域很容易找到问题的源头

上图可见,GC 的MARK阶段阻塞了主协程的运行
2.3 GC
初始所有对象都是白色
Stack scan阶段:从root出发扫描所有可达对象,标记为灰色并放入待处理队列;root包括全局指针和goroutine栈上的指针
Mark阶段:1.从待处理队列取出灰色对象,将其引用的对象标记为灰色并放入队列,自身标记为黑色 2. re-scan全局指针和栈,因为mark和用户程序并行运行,故过程1的时候可能会有新的对象分配,这时需要通过写屏障(write barrier)记录下来;re-scan再完成检查;
重复步骤Mark阶段,直到灰色对象队列为空,执行清扫工作(白色即为垃圾对象)
GC即将开始时,需要STW 做一些准备工作, 如enable write barrier
re-scan也需要STW,否则上面Mark阶段的re-scan无法终止
通过GODEBUG=gctrace=1可以开启gc日志,查看gc的结果信息
$ GODEBUG=gctrace=1 go run main.go gc 1 @0.001s 19%: 0.014+3.7+0.015 ms clock, 0.11+2.8/5.7/3.2+0.12 ms cpu, 5->6->6 MB, 6 MB goal, 8 P gc 2 @0.024s 6%: 0.004+3.4+0.010 ms clock, 0.032+1.4/4.5/5.3+0.085 ms cpu, 13->14->13 MB, 14 MB goal, 8 P gc 3 @0.093s 3%: 0.004+6.1+0.027 ms clock, 0.032+0.19/11/15+0.22 ms cpu, 24->25->22 MB, 26 MB goal, 8 P scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB) scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB) scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB) scvg: 0 MB released scvg: inuse: 4, idle: 58, sys: 63, released: 58, consumed: 4 (MB)
格式
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
含义
gc#:GC 执行次数的编号,每次叠加。
@#s:自程序启动后到当前的具体秒数。
#%:自程序启动以来在GC中花费的时间百分比。
#+...+#:GC 的标记工作共使用的 CPU 时间占总 CPU 时间的百分比。
#->#-># MB:分别表示 GC 启动时, GC 结束时, GC 活动时的堆大小.
#MB goal:下一次触发 GC 的内存占用阈值。
#P:当前使用的处理器 P 的数量。
https://github.com/felixge/fgprof 给出了一个解决方案:
具体用法:
package main
import(
_ "net/http/pprof"
"github.com/felixge/fgprof"
)
func main() {
http.DefaultServeMux.Handle("/debug/fgprof", fgprof.Handler())
go func() {
log.Println(http.ListenAndServe(":6060", nil))
}()
// <code to profile>
}
git clone https://github.com/brendangregg/FlameGraph
cd FlameGraph
curl -s 'localhost:6060/debug/fgprof?seconds=3' > fgprof.fold
./flamegraph.pl fgprof.fold > fgprof.svg如果遇到这种CPU消耗型和非CPU消耗型混合的情况下 可以试试排查下。
위 내용은 golang性能诊断看这篇就够了의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!