
Python 웹 크롤러를 사용하여 자금 정보를 얻는 방법을 단계별로 가르칩니다.
- Go语言进阶学习앞으로
- 2023-07-24 14:53:201002검색
1. 소개
몇일 전 한 팬이 펀드 정보를 얻기 위해 찾아왔습니다. 관심 있는 친구들도 적극적으로 시도해 볼 수 있습니다.
2. 데이터 수집
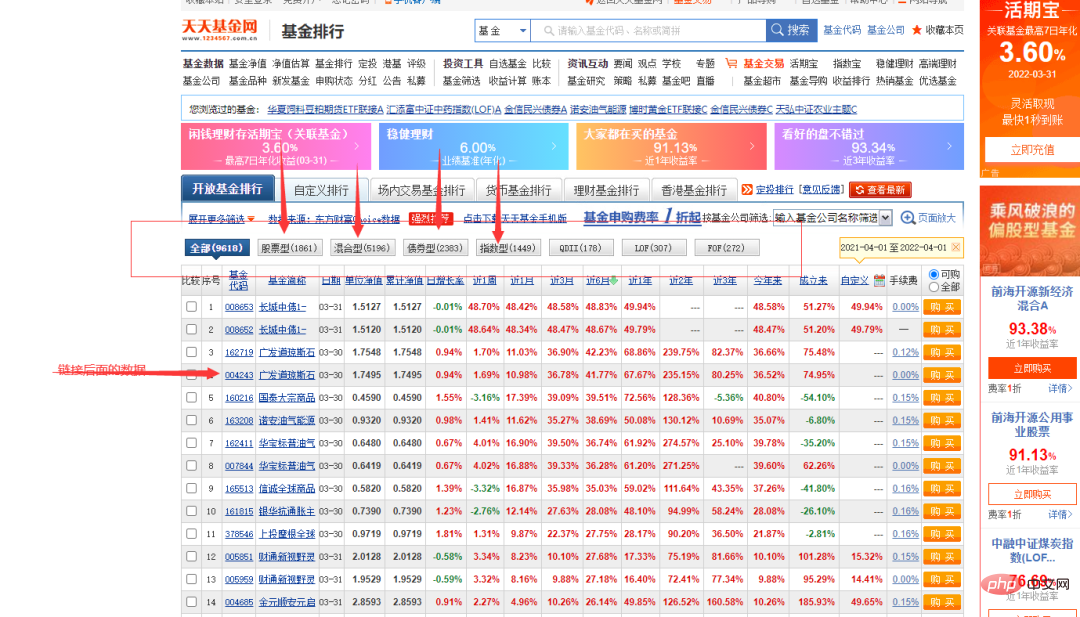
여기서 우리가 타겟으로 삼는 웹사이트는 펀드의 공식 웹사이트이며, 수집해야 할 데이터는 아래 그림과 같습니다.
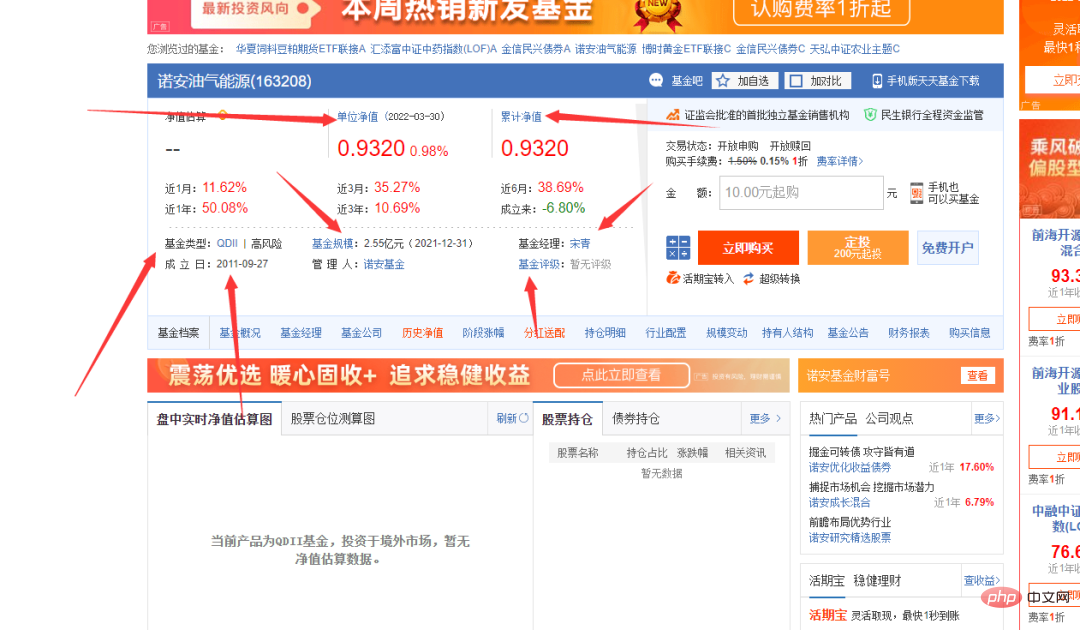 위 사진의 펀드 코드 열에 숫자가 다른 것을 볼 수 있습니다. 무작위로 하나를 클릭하면 펀드 세부 정보 페이지로 들어갈 수 있으며, 링크도 매우 규칙적이며 기호가 있습니다.
위 사진의 펀드 코드 열에 숫자가 다른 것을 볼 수 있습니다. 무작위로 하나를 클릭하면 펀드 세부 정보 페이지로 들어갈 수 있으며, 링크도 매우 규칙적이며 기호가 있습니다.
사실 이 웹사이트는 데이터가 암호화되어 있지 않아, 웹페이지에 있는 정보를 소스코드에서 직접 볼 수 있습니다. 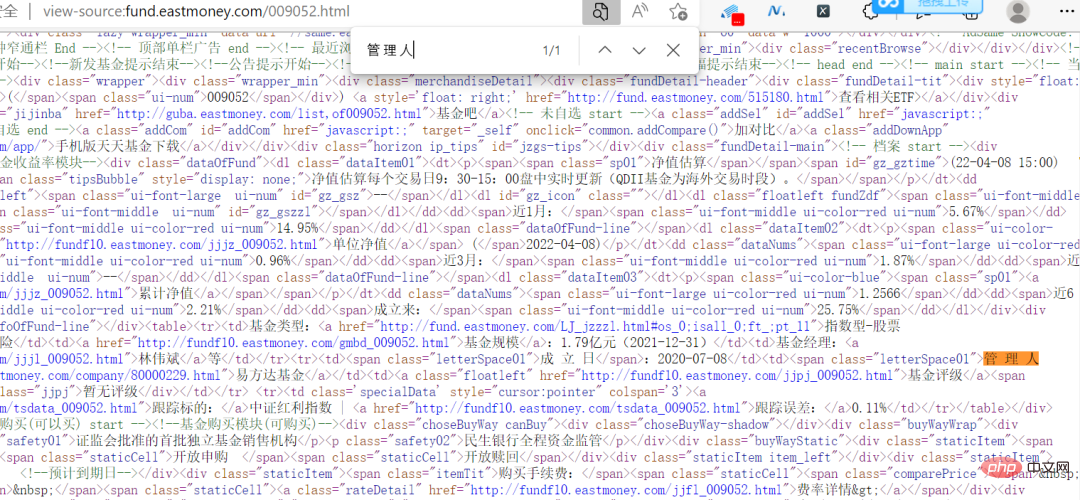
이렇게 하면 크롤링의 어려움이 줄어듭니다. 브라우저 패킷 캡처 방식을 통해 특정 요청 매개변수를 볼 수 있고, 요청 매개변수에서 pi만 변경되는 것을 볼 수 있는데, 이 값이 해당 페이지에 해당하게 되므로 요청 매개변수를 직접 구성할 수 있습니다. 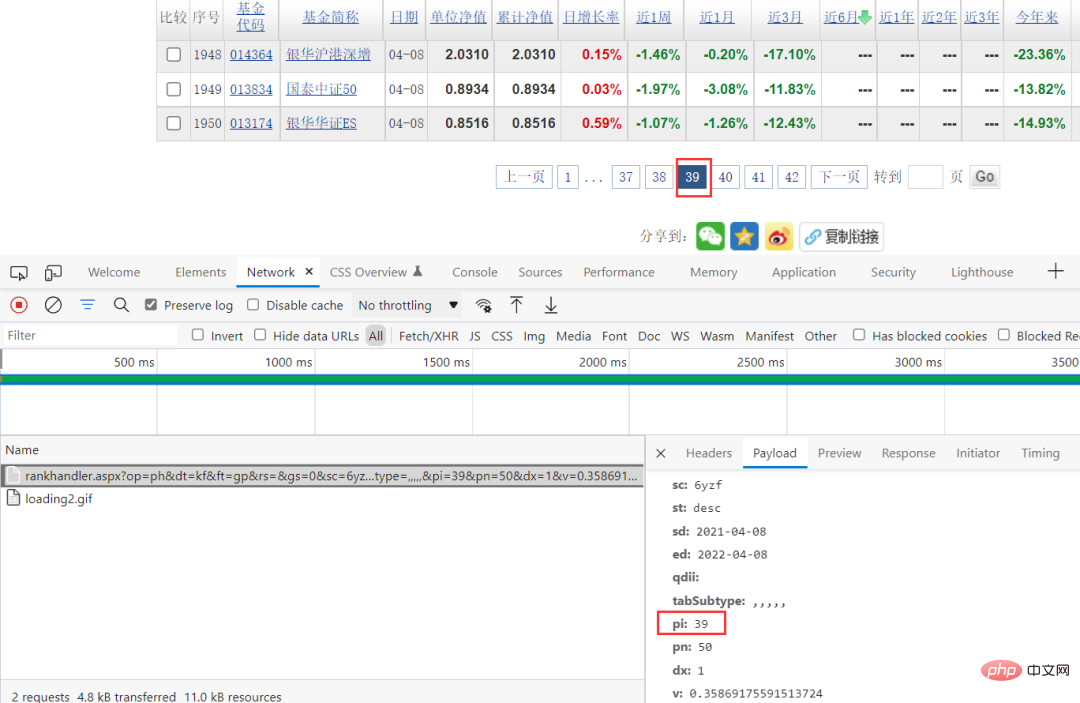
코드 구현 과정
데이터 소스를 찾은 후 다음 단계는 코드를 구현하는 것입니다.
주식 ID 데이터 가져오기
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]결과는 아래 그림과 같습니다.
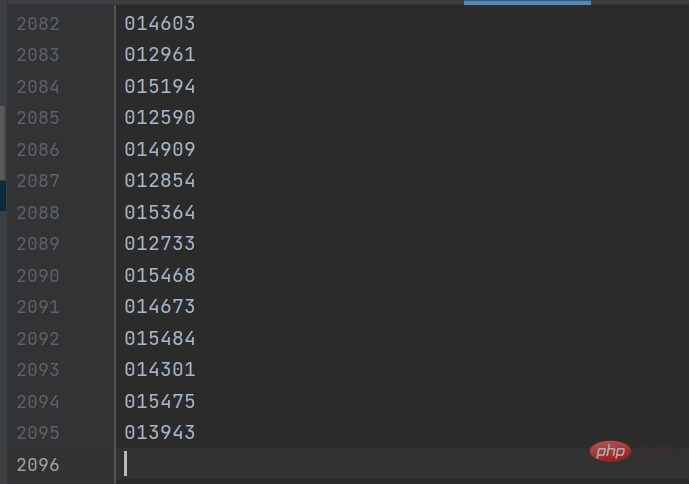
그런 다음 세부 페이지 링크를 구성하여 세부 페이지에서 펀드 정보를 가져옵니다. 키 코드는 다음과 같습니다. :
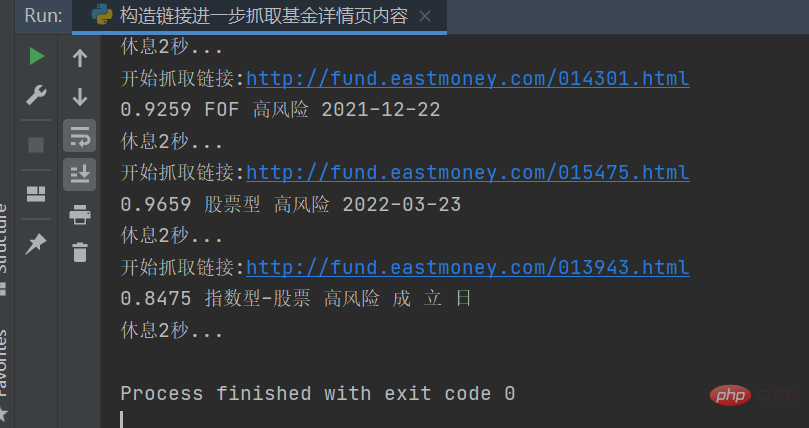
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
결과는 아래 그림과 같습니다.
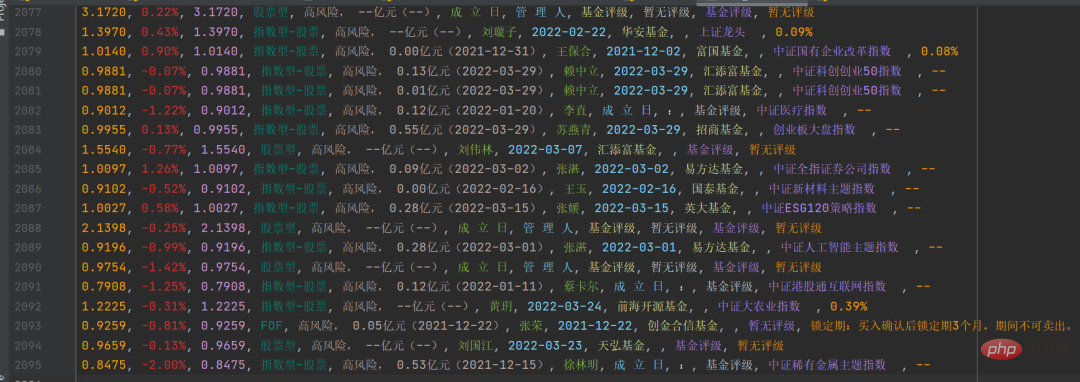
 특정 정보를 해당 문자열로 처리한 후
특정 정보를 해당 문자열로 처리한 후 csv 파일에 저장합니다. 결과는 아래와 같습니다.
 이렇게 하면 됩니다. 추가 통계 및 데이터 분석.
이렇게 하면 됩니다. 추가 통계 및 데이터 분석.
3. 요약
안녕하세요 여러분, 저는 Python 숙련자입니다. 이 글에서는 주로 Python 웹 크롤러를 사용하여 펀드 데이터 정보를 얻는 방법을 공유합니다. 이 프로젝트는 그다지 어렵지 않지만 몇 가지 함정이 있습니다. 문제가 발생하면 저를 친구로 추가해 주세요. 나는 그것을 해결하는 데 도움을 줄 것입니다.
이 글에서는 주로 [주식 유형] 분류를 다루었습니다. 다른 유형에 대해서는 수행하지 않았습니다. 실제로 논리는 동일하므로 매개 변수만 변경하면 됩니다. 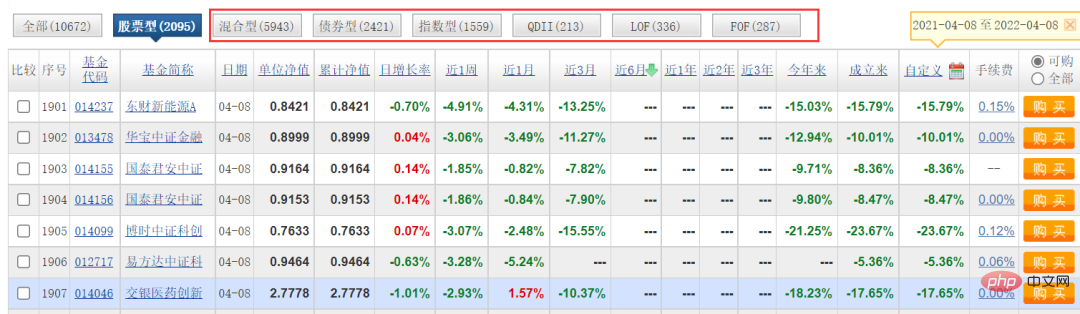
위 내용은 Python 웹 크롤러를 사용하여 자금 정보를 얻는 방법을 단계별로 가르칩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!