
Vernacular Go 메모리 모델 및 Happen-Before
- Go语言进阶学习앞으로
- 2023-07-24 14:50:411305검색
여러 고루틴이 동일한 데이터에 동시에 액세스하는 경우 동시 액세스 작업은 직렬화되어야 합니다. Go에서 읽기 및 쓰기의 직렬화는 채널 통신이나 기타 동기화 기본 요소(예: 뮤텍스 잠금, 동기화 패키지의 읽기-쓰기 잠금, 동기화/원자적 작업의 원자적 작업)를 통해 보장될 수 있습니다.
이전에 발생합니다
단일 고루틴에서 읽기 및 쓰기 동작은 프로그램에서 지정한 실행 순서와 일치해야 합니다. 즉, 컴파일러와 프로세서는 언어 사양에 정의된 동작을 변경하지 않고도 단일 고루틴에서 명령을 재정렬할 수 있습니다.
a := 1 b := 2
지시문 재정렬로 인해 b := 2는 a := 1실행합니다. 단일 고루틴에서는 실행 순서를 조정해도 최종 결과에 영향을 미치지 않습니다. 그러나 여러 고루틴 시나리오에서는 문제가 발생할 수 있습니다. b := 2可能先于a := 1执行。单goroutine中,该执行顺序的调整并不会影响最终结果。但多个goroutine场景下可能就会出现问题。
var a, b int
// goroutine A
go func() {
a := 5
b := 1
}()
// goroutine B
go func() {
for b == 1 {}
fmt.Println(a)
}()执行上述代码时,预期goroutine B能够正常输出5,但因为指令重排序,b := 1可能先于a := 5
func sleep() bool {
time.Sleep(time.Second)
return true
}
go fmt.Println(sleep())위 코드를 실행하면 고루틴 B는 정상적으로 5를 출력할 것으로 예상되는데 명령어 재정렬로 인해 b := 1가 a := 5가 실행되고 고루틴 B는 결국 0을 출력할 수 있습니다. 🎜"Note: 위의 예는 잘못된 예이며 설명용일 뿐입니다.
"
읽기 및 쓰기 작업에 대한 요구 사항을 명확히 하기 위해 Go에서는 수행 방법을 나타내는 happens before을 도입했습니다. 메모리 작업은 부분 순서 관계입니다.
이전 발생의 역할
여러 고루틴이 공유 변수에 액세스할 때 읽기에서 예상되는 쓰기를 관찰할 수 있도록 이전 발생 조건을 보장하는 동기화 이벤트를 설정해야 합니다.
What is Happens Before
이벤트 e1이 이벤트 e2 이전에 발생하면 e2가 e1 이후에 발생했다고 말합니다. 마찬가지로, e1이 e2 이전이나 e2 이후에 발생하지 않으면 e1과 e2가 동시에 발생한다고 말합니다.
단일 고루틴에서는 이전에 발생한 순서가 프로그램 실행 순서입니다. 그렇다면 이전에 일어난 순서는 무엇입니까? 아래 조건을 살펴보겠습니다.
변수 v에 대한 읽기 작업 r과 쓰기 작업 w가 다음 두 조건을 만족하면 r은 w를 관찰하는 것이 허용됩니다.
r은 w보다 먼저 발생하지 않습니다. w 이후와 r 이전에는 다른 쓰기 작업이 발생하지 않습니다.
변수 v의 읽기 작업 r이 특정 쓰기 작업 w를 관찰할 수 있도록 하려면 w가 r이 관찰할 수 있는 유일한 쓰기 작업인지 확인해야 합니다. 그러면 r과 w가 모두 다음 조건을 만족하면 r은 w를 보장 관찰할 수 있습니다.
w가 r보다 먼저 발생합니다. 다른 쓰기 작업은 w 이전과 r 이후에 발생합니다.
단일 고루틴에는 동시성이 없으며 이 두 조건은 동일합니다. Lao Xu는 이를 기반으로 확장하여 이 두 가지 조건 세트가 단일 코어 운영 환경에서 동일하다는 것을 발견했습니다. 동시성의 경우 후자의 조건 집합이 첫 번째 조건 집합보다 더 엄격합니다.
헷갈리셨다면 정답입니다! Lao Xu도 처음에는 혼란스러워했습니다. 이 두 가지 조건은 동일했습니다. 이러한 이유로 노서는 위의 이해가 올바른지 확인하기 위해 특별히 원문과 반복적으로 비교했습니다.

생각을 바꾸고 역추론을 해보자. 두 가지 조건이 동일하다면 원본 텍스트를 두 번 작성할 필요가 없습니다. 물론 문제는 간단하지 않습니다.

분석을 계속하기 전에 중국어 선생님께 감사의 말씀을 전하고 싶습니다. 선생님이 없었다면 저는 둘의 차이점을 발견할 수 없었을 것입니다.
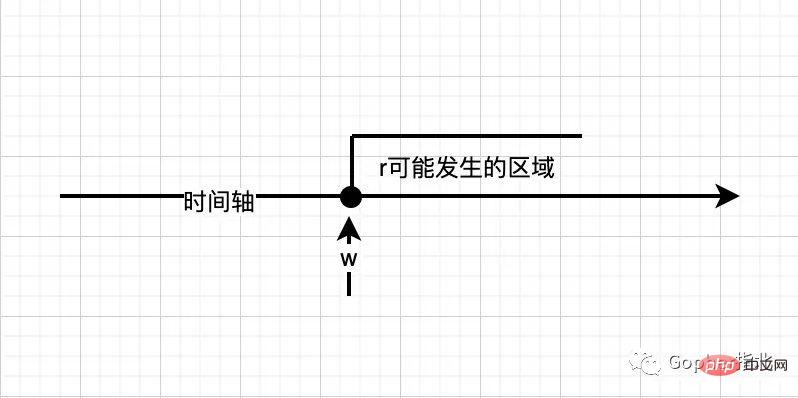
r은 하지 않았습니다. w 이전에 발생하고 r에 대해 가능한 상황은 아래 그림에 표시된 것처럼 r이 w 이후에 발생하거나 w와 동시에 발생하는 것입니다(실선은 동시에 발생할 수 있음을 나타냄). r没有发生在w之前,则r可能的情况是r发生在w之后或者和w同时发生,如下图(实心表示可同时)。
没有其他写操作发生在w之后和r之前
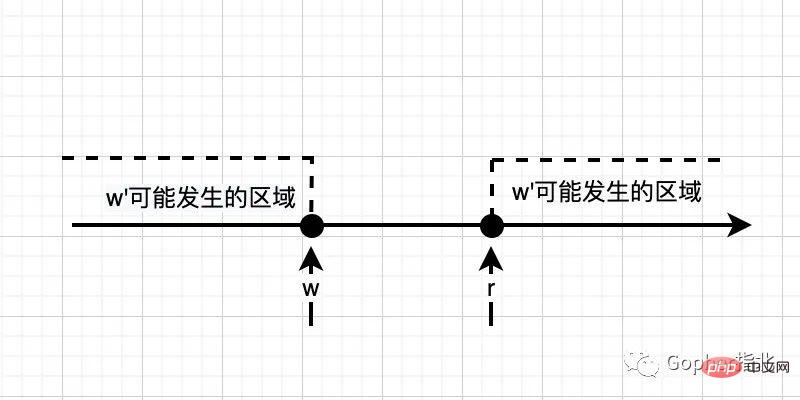
w 뒤 및 r 앞 이후에는 다른 쓰기 작업이 발생하지 않습니다. w'는 w 이전에 발생할 수도 있고 w와 동시에 발생할 수도 있으며, 아래 그림과 같이 r 이후에 또는 r과 동시에 발생할 수도 있습니다(실선은 동시에 발생할 수 있음을 나타냄). 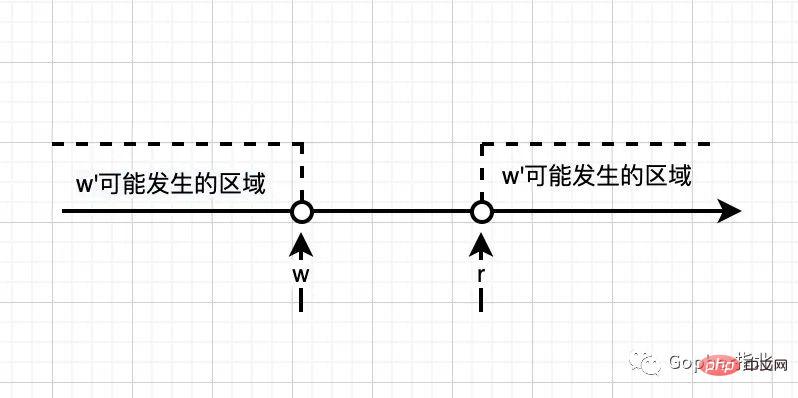 두 번째 조건 세트는 아래 그림과 같이 w가 r 이전에 발생하고 다른 쓰기 작업은 w 이전 또는 r 이후에만 발생할 수 있다는 것이 매우 명확합니다(빈 공간은 동시에 발생할 수 없음을 나타냅니다). ).
두 번째 조건 세트는 아래 그림과 같이 w가 r 이전에 발생하고 다른 쓰기 작업은 w 이전 또는 r 이후에만 발생할 수 있다는 것이 매우 명확합니다(빈 공간은 동시에 발생할 수 없음을 나타냅니다). ). Go에서의 동기화
🎜🎜다음은 Go에서 합의된 일부 동기화 이벤트입니다. 이는 프로그램이 사전 발생 원칙을 따르도록 하여 동시 고루틴이 비교적 질서정연하게 되도록 할 수 있습니다. 🎜Go的初始化
程序初始化运行在单个goroutine中,但是该goroutine可以创建其他并发运行的goroutine。
如果包p导入了包q,则q包init函数执行结束先于p包init函数的执行。main函数的执行发生在所有init函数执行完成之后。
goroutine的创建结束
goroutine的创建先于goroutine的执行。老许觉得这基本就是废话,但事情总是没有那么简单,其隐含之意大概是goroutine的创建是阻塞的。
func sleep() bool {
time.Sleep(time.Second)
return true
}
go fmt.Println(sleep())上述代码会阻塞主goroutine一秒,然后才创建子goroutine。
goroutine的退出是无法预测的。如果用一个goroutine观察另一个goroutine,请使用锁或者Channel来保证相对有序。
Channel的发送和接收
Channel通信是goroutine之间同步的主要方式。
Channel的发送动作先于相应的接受动作完成之前。
无缓冲Channel的接受先于该Channel上的发送完成之前。
这两点总结起来分别是开始发送、开始接受、发送完成和接受完成四个动作,其时序关系如下。
开始发送 > 接受完成 开始接受 > 发送完成
“注意:开始发送和开始接受并无明确的先后关系
”
Channel的关闭发生在由于通道关闭而返回零值接受之前。
容量为C的Channel第k个接受先于该Channel上的第k+C个发送完成之前。
这里使用极限法应该更加易于理解,如果C为0,k为1则其含义和无缓冲Channel的一致。
Lock
对于任何sync.Mutex或sync.RWMutex变量l以及n < m,第n次l.Unlock()的调用先于第m次l.Lock()的调用返回。
假设n为1,m为2,则第二次调用l.Lock()返回前一定要先调用l.UnLock()。
对于sync.RWMutex的变量l存在这样一个n,使得l.RLock()的调用返回在第n次l.Unlock()之后发生,而与之匹配的l.RUnlock()发生在第n + 1次l.Lock()之前。
不得不说,上面这句话简直不是人能理解的。老许将其翻译成人话:
有写锁时:l.RLock()的调用返回发生在l.Unlock()之后。
有读锁时:l.RUnlock()的调用发生在l.Lock()之前。
“注意:调用l.RUnlock()前不调用l.RLock()和调用l.Unlock()前不调用l.Lock()会引起panic。
”
Once
once.Do(f)中f的返回先于任意其他once.Do的返回。
不正确的同步
错误示范一
var a, b int
func f() {
a = 1
b = 2
}
func g() {
print(b)
print(a)
}
func main() {
go f()
g()
}这个例子看起来挺简单,但是老许相信大部分人应该会忽略指令重排序引起的异常输出。假如goroutine f指令重排序后,b=2先于a=1发生,此时主goroutine观察到b发生变化而未观察到a变化,因此有可能输出20。
“老许在本地实验了多次结果都是输出
”00,20这个输出估计只活在理论之中了。
错误示范二
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func doprint() {
if !done {
once.Do(setup)
}
print(a)
}
func twoprint() {
go doprint()
go doprint()
}这种双重检测本意是为了避免同步的开销,但是依旧有可能打印出空字符串而不是“hello, world”。说实话老许自己都不敢保证以前没有写过这样的代码。现在唯一能想到的场景就是其中一个goroutine doprint执行到done = true(指令重排序导致done=true先于a="hello, world"执行)时,另一个goroutine doprint刚开始执行并观察到done的值为true从而打印空字符串。
위 내용은 Vernacular Go 메모리 모델 및 Happen-Before의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!