
Byte 팀은 인지 생성 목록 SoTA를 이해하는 다중 모드 LLM인 Lynx 모델을 제안했습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-07-17 21:57:301428검색
GPT4와 같은 현재 LLM(대형 언어 모델)은 이미지가 제공된 개방형 명령을 따르는 데 뛰어난 다중 모드 기능을 보여주었습니다. 그러나 이러한 모델의 성능은 네트워크 구조, 훈련 데이터 및 훈련 전략의 선택에 크게 좌우되지만 이러한 선택은 이전 문헌에서 널리 논의되지 않았습니다. 또한 현재 이러한 모델을 평가하고 비교할 수 있는 적절한 벤치마크가 부족하여 다중 모드 LLM의 개발이 제한됩니다.
 Pictures
Pictures
- Paper: https://arxiv.org/abs/2307.02469
- 웹사이트: https://lynx-llm.github.io/
- 코드: https: //github.com/bytedance/lynx-llm
이 기사에서 저자는 정량적 측면과 질적 측면 모두에서 이러한 모델의 훈련에 대한 체계적이고 포괄적인 연구를 수행합니다. 20개 이상의 변형이 네트워크 구조에 대해 설정되었으며, 교육 데이터에 대해 다양한 LLM 백본과 모델 설계가 비교되었으며, 지침 측면에서 데이터 및 샘플링 전략이 모델에 미치는 영향이 연구되었습니다. 지시에 따른 능력이 미치는 영향을 탐구하였다. 벤치마크를 위해 이 기사는 이미지 및 비디오 작업을 포함하는 개방형 시각적 질문 답변 평가 세트인 Open-VQA를 처음으로 제안했습니다.
저자는 실험적 결론을 바탕으로 기존 오픈 소스 GPT4 스타일 모델에 비해 최고의 다중 모드를 유지하면서 가장 정확한 다중 모드 이해를 보여주는 Lynx 생성 능력을 제안했습니다.
평가 방식
일반적인 시각적 언어 작업과 달리 GPT4 스타일 모델을 평가할 때 가장 중요한 과제는 텍스트 생성 기능과 다중 모드 이해 정확도 성능의 균형을 맞추는 것입니다. 이러한 문제를 해결하기 위해 저자는 영상 및 이미지 데이터를 포함한 새로운 벤치마크 Open-VQA를 제안하고, 현재 오픈소스 모델에 대한 종합적인 평가를 수행한다.
구체적으로 두 가지 정량적 평가 방식을 채택합니다.
- 객체, OCR, 계산, 추론, 동작 인식 및 시간 순서에 대한 정보가 포함된 Open-VQA(Open Visual Question Answering) 테스트 세트를 수집합니다. . 및 기타 다양한 카테고리의 질문이 있습니다. 표준 답변이 있는 VQA 데이터 세트와 달리 Open-VQA의 답변은 개방형입니다. Open-VQA의 성능을 평가하기 위해 GPT4가 판별자로 사용되었으며 결과는 인간 평가와 95% 일치했습니다.
- 또한 저자는 mPLUG-owl[1]에서 제공하는 OwlEval 데이터 세트를 사용하여 모델의 텍스트 생성 능력을 평가했습니다. 비록 50장의 그림과 82개의 질문만 포함되어 있지만 스토리 생성, 광고 생성, 코드 생성 등 다양한 질문을 하고 인간 주석자를 모집하여 다양한 모델의 성능을 평가합니다.
결론
다중 모드 LLM의 훈련 전략을 심층적으로 연구하기 위해 저자는 주로 네트워크 구조(접두사 미세 조정/교차 주의), 훈련 데이터(데이터 선택 및 조합 비율), 명령어(단일 명령어/다양한 표시 등 다양한 측면에서 20개 이상의 변형이 설정됨), LLM 모델(LLaMA [5]/Vicuna [6]), 이미지 픽셀(420/224) 등 실험을 통해 다음과 같은 주요 결론이 도출되었습니다.
- 다중 모드 LLM의 지시 따르기 능력은 LLM만큼 좋지 않습니다. 예를 들어 InstructBLIP[2]은 입력 지시와 관계없이 짧은 응답을 생성하는 경향이 있는 반면, 다른 모델은 지시와 관계없이 긴 문장을 생성하는 경향이 있는데, 이는 저자가 생각하는 고품질의 다양한 다중 응답이 부족하기 때문이라고 생각합니다. 명령 데이터로 인한 양식.
- 훈련 데이터의 품질은 모델 성능에 매우 중요합니다. 다양한 데이터에 대한 실험 결과에 따르면 대규모의 노이즈 데이터를 사용하는 것보다 소량의 고품질 데이터를 사용하는 것이 더 나은 성능을 발휘하는 것으로 나타났습니다. 저자는 이것이 생성 훈련과 대조 훈련의 차이점이라고 생각한다. 생성 훈련은 텍스트와 이미지의 유사성보다는 단어의 조건부 분포를 직접 학습하기 때문이다. 따라서 더 나은 모델 성능을 위해서는 데이터 측면에서 두 가지가 충족되어야 합니다. 1) 고품질의 부드러운 텍스트를 포함합니다. 2) 텍스트와 이미지 내용이 잘 정렬되어 있습니다.
- 퀘스트와 프롬프트는 제로샷 기능에 매우 중요합니다. 다양한 작업과 지침을 사용하면 알 수 없는 작업에 대한 모델의 제로 샷 생성 능력이 향상될 수 있으며 이는 일반 텍스트 모델의 관찰과 일치합니다.
- 정확성과 언어 생성 기능의 균형을 맞추는 것이 중요합니다. 모델이 다운스트림 작업(예: VQA)에 대해 과소 훈련된 경우 시각적 입력과 일치하지 않는 조작된 콘텐츠를 생성할 가능성이 더 높으며 모델이 다운스트림 작업에 대해 과도하게 훈련된 경우 짧은 답변을 생성하는 경향이 있습니다. 더 긴 답변을 생성하려면 사용자 지침을 따를 수 없습니다.
- PT(Prefix-finetuning)는 현재 LLM의 다중 모드 적응을 위한 최고의 솔루션입니다. 실험에서 Prefix-Finetuning 구조의 모델은 CA(Cross-Attention)가 있는 모델 구조보다 다양한 지침을 더 빠르게 따르는 능력을 향상시키고 훈련시키기가 더 쉽습니다. (prefix-tuning과 cross-attention은 두 가지 모델 구조입니다. 자세한 내용은 Lynx 모델 소개 섹션을 참조하세요.)
Lynx 모델
저자가 제안한 Lynx(猞猁)——2단계 학습 GPT4 접두사 미세 조정이 포함된 스타일 모델입니다. 첫 번째 단계에서는 약 120M 이미지-텍스트 쌍이 시각적 및 언어 임베딩을 정렬하는 데 사용되며, 두 번째 단계에서는 20개의 이미지 또는 비디오가 다중 모달 작업 및 자연어 처리(NLP) 데이터에 사용되어 모델의 명령을 따르는 기능.
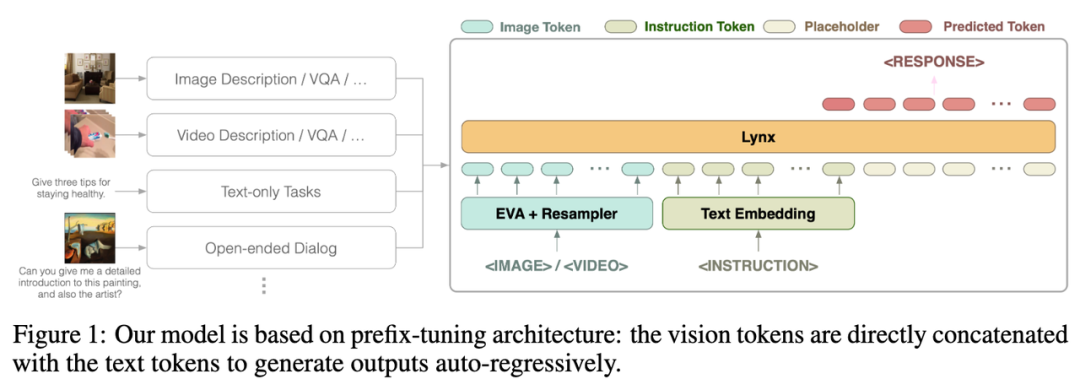 Pictures
Pictures
Lynx 모델의 전체 구조는 위의 그림 1에 나와 있습니다.
시각적 입력은 시각적 토큰(토큰) $$W_v$$을 얻기 위해 시각적 입력을 처리한 후 LLM의 입력으로 명령 토큰 $$W_l$$과 연결됩니다. 이 기사에서는 구조를 Flamingo [3]에서 사용하는 cross-attention 구조와 구별하기 위해 "prefix-finetuning"이라고 합니다.
또한 저자는 고정된 LLM의 특정 레이어 뒤에 Adapter 를 추가하면 교육 비용을 더욱 줄일 수 있다는 사실을 발견했습니다.
모델 효과
저자는 Open-VQA, Mme [4] 및 OwlEval 수동 평가 에서 기존 오픈 소스 다중 모달 LLM 모델의 성능을 평가했습니다. (결과는 아래 차트에 표시되며, 평가 자세한 내용은 종이에 나와 있습니다). Lynx 모델은 Open-VQA 이미지 및 비디오 이해 작업, OwlEval 수동 평가 및 Mme Perception 작업에서 최고의 성능을 달성했음을 알 수 있습니다. 그 중 InstructBLIP도 대부분의 작업에서 높은 성능을 발휘하지만 응답이 너무 짧습니다. 이에 비해 Lynx 모델은 대부분의 경우 정답 제공을 기반으로 응답을 뒷받침하는 간결한 이유를 제공합니다. 친절합니다(경우에 따라 아래 사례 표시 섹션 참조).
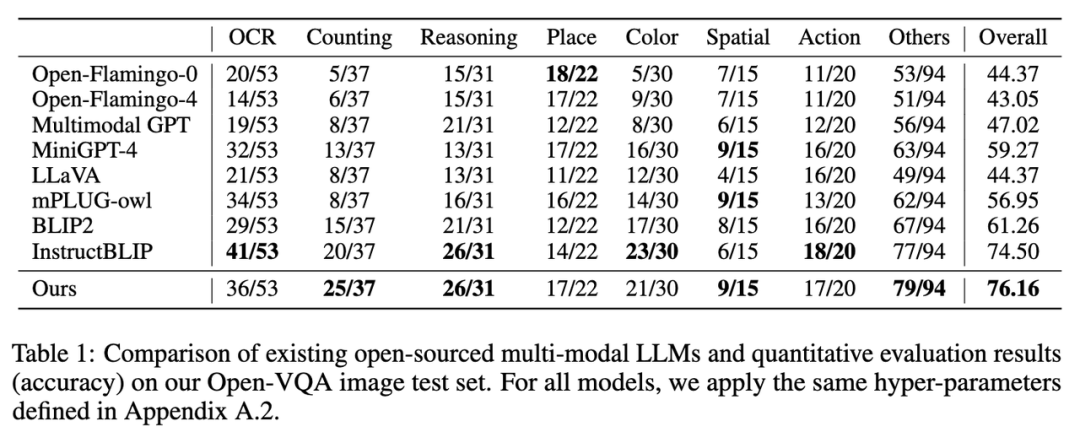
1. Open-VQA 이미지 테스트 세트의 지표 결과는 아래 표 1과 같습니다.
 Pictures
Pictures
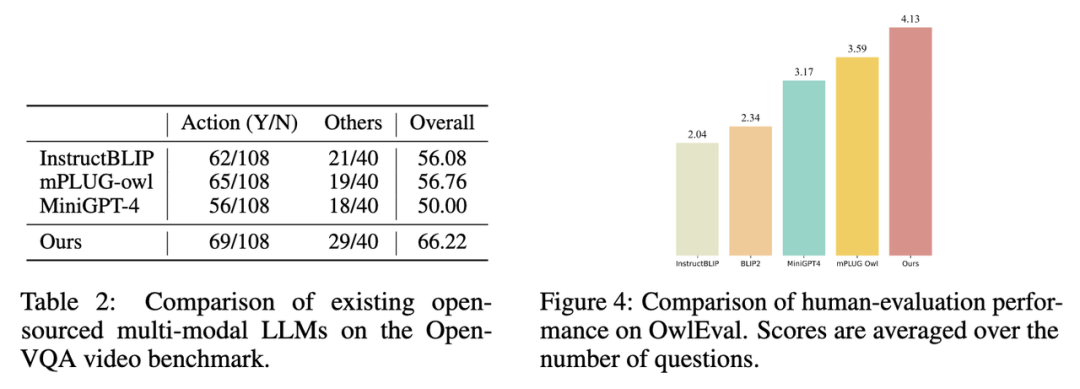
2. Open-VQA 비디오 테스트 세트의 지표 결과는 다음과 같습니다. 아래 표 1에는 2가 나와 있습니다.
 사진
사진
3. Open-VQA에서 가장 높은 점수를 받은 모델을 선택하여 OwlEval 평가 세트에 대한 수동 효과 평가를 수행합니다. 결과는 위의 그림 4에 나와 있습니다. 수동 평가 결과를 보면 Lynx 모델이 가장 좋은 언어 생성 성능을 가지고 있음을 알 수 있습니다.
 Pictures
Pictures
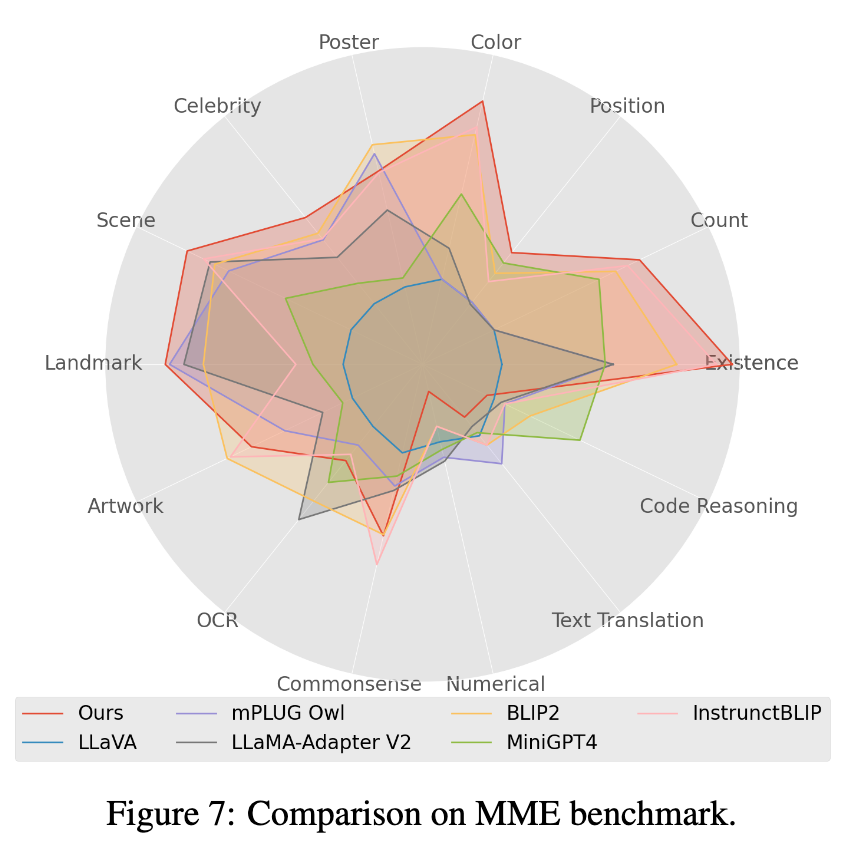
4. Mme 벤치마크 테스트에서 Perception 클래스 작업이 최고의 성능을 달성했으며, 그 중 14개 클래스 하위 작업 중 7개가 가장 좋은 성능을 보였습니다. (자세한 결과는 논문 부록 참조)
보여주는 사례
Open-VQA 사진 사례

OwlEval 사례

Open-V QA 영상 케이스

요약
이 기사에서 저자는 20개 이상의 다중 모드 LLM 변형에 대한 실험을 통해 접두사 미세 조정을 주요 구조로 하는 Lynx 모델을 결정하고 다음과 같은 Open-VQA 평가 계획을 제시했습니다. 답변을 공개하세요. 실험 결과에 따르면 Lynx 모델은 최고의 다중 모드 생성 기능을 유지하면서 가장 정확한 다중 모드 이해 정확도를 수행하는 것으로 나타났습니다.
위 내용은 Byte 팀은 인지 생성 목록 SoTA를 이해하는 다중 모드 LLM인 Lynx 모델을 제안했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!