
NVIDIA H100은 권위 있는 AI 성능 테스트를 장악하여 11분 만에 GPT-3 기반 대규모 모델 훈련을 완료합니다.

- 王林앞으로
- 2023-06-28 20:00:20908검색
현지 시간 화요일, 기계 학습 및 인공 지능 분야의 개방형 산업 연합인 MLCommons는 두 가지 MLPerf 벤치마크의 최신 데이터를 공개했습니다. 그 중 NVIDIA H100 칩셋은 인공 지능 테스트에서 모든 범주에서 새로운 기록을 세웠습니다. 지능 컴퓨팅 성능을 제공하며 모든 테스트를 실행할 수 있는 유일한 하드웨어 플랫폼이었습니다.
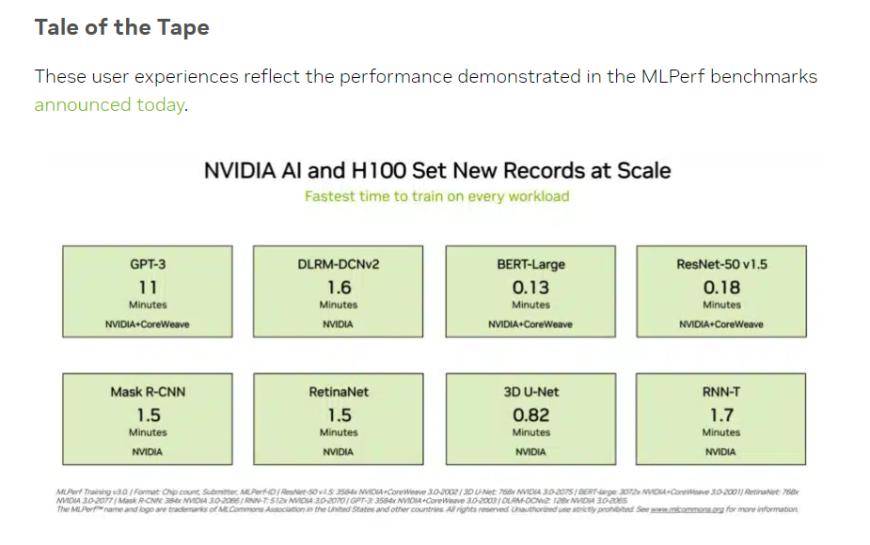
(출처: NVIDIA, MLCommons)
MLPerf는 학계, 연구실, 업계로 구성된 인공지능 리더십 연합으로, 현재 국제적으로 인정받고 권위 있는 AI 성능 평가 벤치마크입니다. Training v3.0에는 비전(이미지 분류, 생체 의학 이미지 분할, 두 가지 로드에 대한 객체 감지), 언어(음성 인식, 대규모 언어 모델, 자연어 처리) 및 추천 시스템을 포함하여 8가지 로드가 포함되어 있습니다. 즉, 장비 공급업체마다 벤치마크 작업을 완료하는 데 소요되는 시간이 다릅니다.
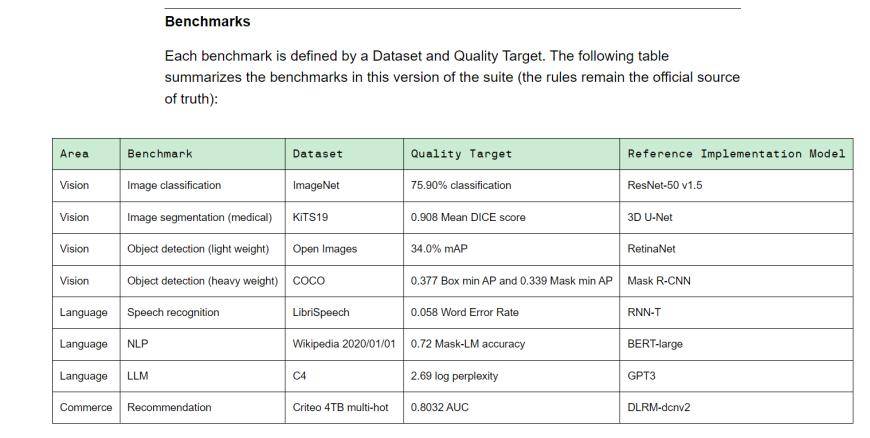
(Training v3.0 교육 벤치마크, 출처: MLCommons)
투자자들이 주목하고 있는 '빅 언어 모델' 트레이닝 테스트에서 NVIDIA와 GPU 클라우드 컴퓨팅 플랫폼 CoreWeave가 제출한 데이터는 이 테스트에 대한 잔인한 업계 표준을 설정했습니다. 896개의 Intel Xeon 8462Y+ 프로세서와 3584개의 NVIDIA H100 칩의 공동 노력으로 GPT-3 기반의 대규모 언어 모델 훈련 작업을 완료하는 데 10.94분 밖에 걸리지 않았습니다.
Nvidia를 제외하고 Intel의 제품 포트폴리오만이 이 프로젝트에 대한 평가 데이터를 받았습니다. 96개의 Xeon 8380 프로세서와 96개의 Habana Gaudi2 AI 칩으로 구축된 시스템에서 동일한 테스트를 완료하는 데 걸리는 시간은 311.94분이었습니다. 768개의 H100 칩이 탑재된 플랫폼을 사용하면 수평 비교 테스트에 45.6분 밖에 걸리지 않습니다.
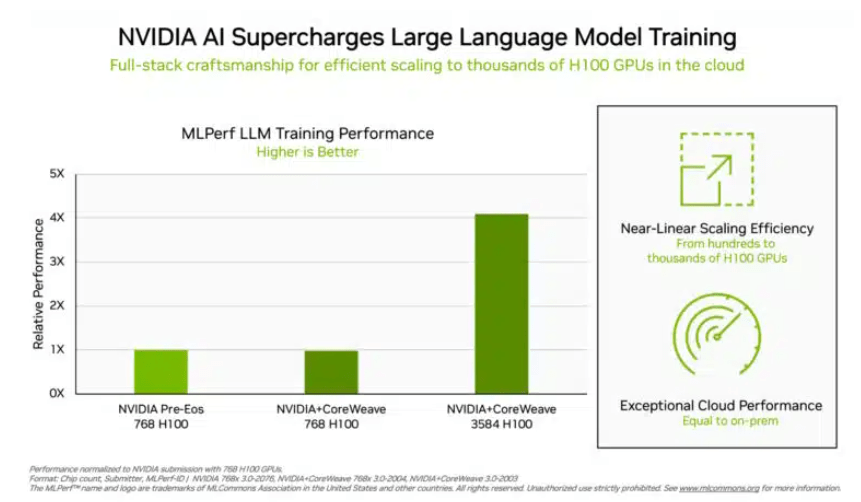
(칩이 많을수록 데이터가 좋아집니다. 출처: NVIDIA)
이번 결과에 대해 인텔도 아직 개선의 여지가 있다고 밝혔습니다. 이론적으로는 더 많은 칩을 쌓을수록 계산 결과는 자연스럽게 빨라집니다. Intel의 AI 제품 담당 수석 이사인 Jordan Plawner는 Habana의 컴퓨팅 결과가 1.5~2배 향상될 것이라고 언론에 말했습니다. Plawner는 업계에서 AI 훈련 칩을 제공하기 위해 두 번째 제조업체가 필요하다고 말하면서 Habana Gaudi2의 구체적인 가격을 공개하는 것을 거부했으며 MLPerf 데이터에 따르면 Intel은 이러한 수요를 충족할 수 있는 능력이 있음을 보여줍니다.
중국 투자자들에게 더욱 친숙한 BERT-Large 모델 트레이닝에서는 NVIDIA와 CoreWeave가 데이터를 64개 카드의 경우 극한까지 0.89분에 도달했습니다. 현재 주류 대형 모델의 인프라는 BERT 모델의 Transformer 구조입니다.
출처: Financial Associated Press
위 내용은 NVIDIA H100은 권위 있는 AI 성능 테스트를 장악하여 11분 만에 GPT-3 기반 대규모 모델 훈련을 완료합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!