
확산 모델을 사용하여 종이 일러스트레이션을 자동으로 생성할 수도 있으며 ICLR에서도 허용됩니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-27 17:46:101645검색
Generative AI는 인공 지능 커뮤니티를 휩쓸었습니다. 개인과 기업 모두 Vincent 사진, Vincent 비디오, Vincent 음악 등과 같은 관련 모달 변환 응용 프로그램을 만드는 데 열중하기 시작했습니다.
최근 ServiceNow Research, LIVIA 등 과학 연구 기관의 여러 연구자들이 텍스트 설명을 기반으로 논문에서 차트를 생성하려고 시도했습니다. 이를 위해 그들은 FigGen의 새로운 방법을 제안했고, 관련 논문도 ICLR 2023에 Tiny Paper로 포함됐다.
 Pictures
Pictures
문서 주소: https://arxiv.org/pdf/2306.00800.pdf
어떤 사람들은 질문할 수도 있습니다. 종이에 차트를 생성하는 것이 무엇이 그렇게 어려운가요? 이것이 과학 연구에 어떻게 도움이 됩니까?
과학 연구 차트 생성은 간결하고 이해하기 쉬운 방식으로 연구 결과를 전파하는 데 도움이 되며, 차트 자동 생성은 차트를 처음부터 디자인하는 데 많은 노력을 들이지 않고도 시간과 에너지를 절약하는 등 연구자에게 많은 이점을 제공할 수 있습니다. . 또한, 시각적으로 매력적이고 이해하기 쉬운 그림을 디자인하면 더 많은 사람들이 논문에 접근할 수 있습니다.
다이어그램을 생성하는 데에는 상자, 화살표, 텍스트 등과 같은 개별 구성요소 간의 복잡한 관계를 표현해야 하는 경우도 있습니다. 자연스러운 이미지를 생성하는 것과 달리 종이 그래프의 개념은 다르게 표현될 수 있으며 세밀한 이해가 필요할 수 있습니다. 예를 들어 신경망 그래프를 생성하려면 분산이 높은 잘못된 문제가 포함됩니다.
따라서 이 논문의 연구자들은 다이어그램 구성 요소와 논문의 해당 텍스트 간의 관계를 포착하기 위해 종이 다이어그램 쌍의 데이터 세트에 대한 생성 모델을 훈련했습니다. 이를 위해서는 다양한 길이와 고도로 기술적인 텍스트 설명, 다양한 차트 스타일, 이미지 종횡비, 텍스트 렌더링 글꼴, 크기 및 방향 문제를 처리해야 합니다.
특정 구현 과정에서 연구원들은 최근의 텍스트-이미지 결과에서 영감을 얻어 확산 모델을 사용하여 차트를 생성했습니다. 그들은 텍스트 설명에서 과학 연구 차트를 생성하기 위한 잠재적인 확산 모델인 FigGen을 제안했습니다.
이 확산 모델의 독특한 특징은 무엇입니까? 세부 사항으로 넘어 갑시다.
모델 및 방법
연구원들은 잠재 확산 모델을 처음부터 훈련했습니다.
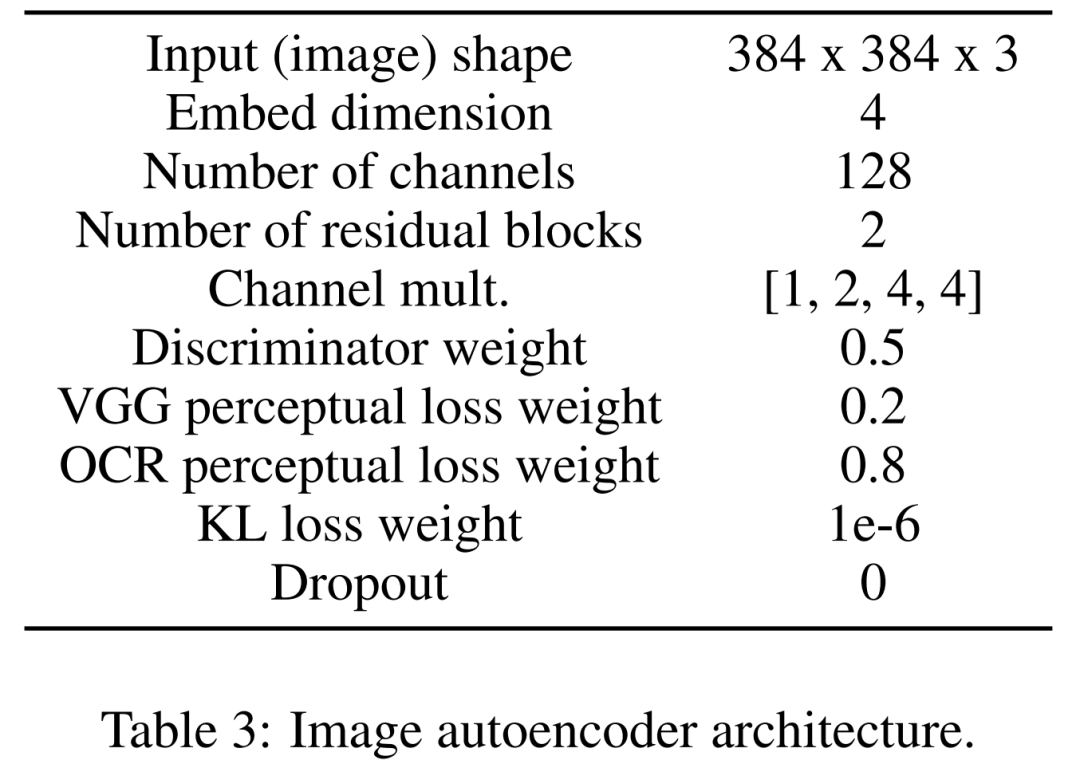
먼저 이미지 자동 인코더를 배워 이미지를 압축된 잠재 표현으로 매핑합니다. 이미지 인코더는 KL 손실과 OCR 지각 손실을 사용합니다. 조건화에 사용되는 텍스트 인코더는 이 확산 모델의 학습에서 처음부터 끝까지 학습됩니다. 아래 표 3은 이미지 오토인코더 아키텍처의 세부 매개변수를 보여줍니다.
그런 다음 확산 모델은 잠재 공간에서 직접 상호 작용하여 데이터가 손상된 순방향 스케줄링을 수행하는 동시에 시간 및 텍스트 조건부 노이즈 제거 U-Net을 활용하여 프로세스를 복구하는 방법을 학습합니다.
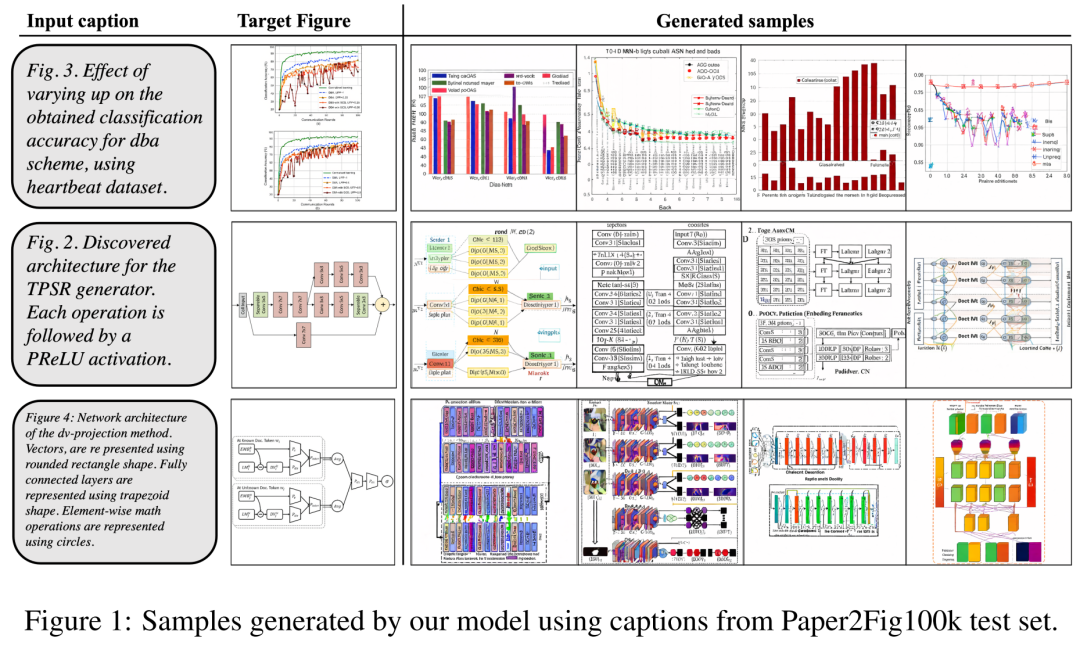
데이터 세트의 경우, 연구원들은 논문의 차트-텍스트 쌍으로 구성되고 81,194개의 훈련 샘플과 21,259개의 검증 샘플을 포함하는 Paper2Fig100k를 사용했습니다. 아래 그림 1은 Paper2Fig100k 테스트 세트의 텍스트 설명을 사용하여 생성된 다이어그램의 예입니다.
모델 세부정보
첫 번째는 이미지 인코더입니다. 첫 번째 단계에서 이미지 자동 인코더는 픽셀 공간에서 압축된 잠재 표현으로의 매핑을 학습하여 확산 모델 학습을 더 빠르게 만듭니다. 또한 이미지 인코더는 다이어그램의 중요한 세부 정보(예: 텍스트 렌더링 품질)를 잃지 않고 잠재 이미지를 픽셀 공간에 다시 매핑하는 방법을 배워야 합니다.
이를 위해 연구원들은 f=8 인자에서 이미지를 다운샘플링하는 병목 현상이 있는 컨벌루션 코덱을 정의했습니다. 인코더는 가우시안 분포를 통해 KL 손실, VGG 인식 손실, OCR 인식 손실을 최소화하도록 학습되었습니다.
두 번째는 텍스트 인코더입니다. 연구원들은 범용 텍스트 인코더가 그래프 생성 작업에 적합하지 않다는 사실을 발견했습니다. 따라서 그들은 U-Net의 교차 주의 계층을 조절하는 임베딩 크기이기도 한 크기 512의 임베딩 채널을 사용하는 확산 프로세스에서 처음부터 훈련된 Bert 변환기를 정의합니다. 연구원들은 또한 다양한 설정(8, 32, 128)에서 변압기 레이어 수의 변화를 조사했습니다.
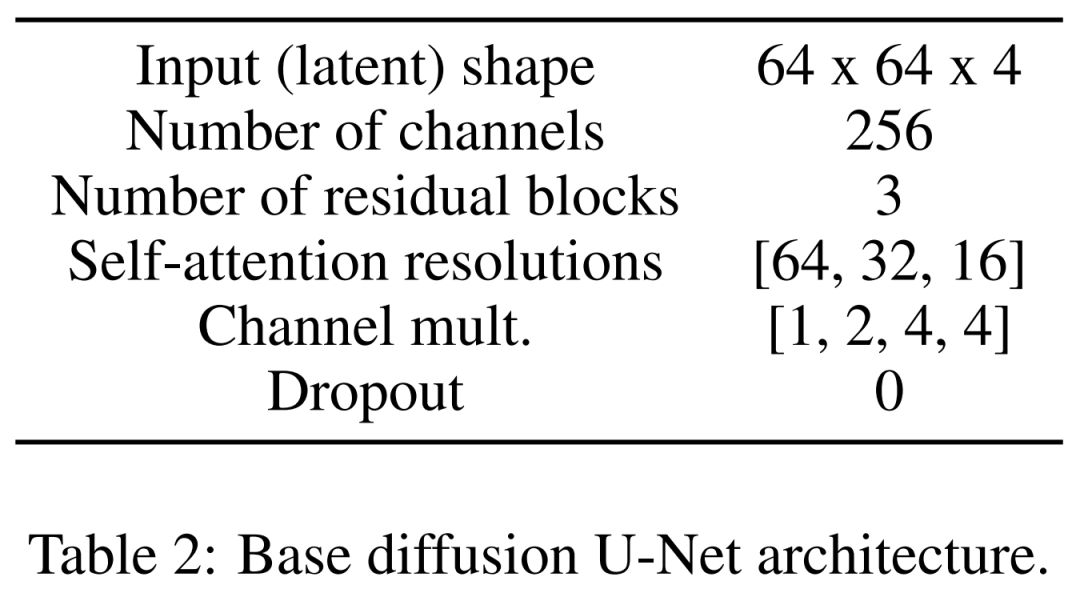
마지막은 잠재 확산 모델입니다. 아래 표 2는 U-Net의 네트워크 아키텍처를 보여준다. 우리는 지각적으로 동등한 이미지의 잠재 표현에 대해 확산 프로세스를 수행합니다. 여기서 이미지의 입력 크기는 64x64x4로 압축되어 확산 모델을 더 빠르게 만듭니다. 그들은 1,000개의 확산 단계와 선형 노이즈 스케줄링을 정의했습니다.
교육 세부 정보
연구원들은 4개 샘플의 유효 배치 크기와 4.5e −6의 학습률을 갖춘 Adam 최적화 프로그램을 사용했습니다. 4개의 12GB NVIDIA V100 그래픽 카드가 사용되었습니다. 훈련 안정성을 달성하기 위해 판별자를 사용하지 않고 50,000번의 반복으로 모델을 준비합니다.
잠재 확산 모델을 훈련하기 위해 연구원들은 유효 배치 크기가 32이고 학습률이 1e−4인 Adam 최적화 프로그램도 사용했습니다. Paper2Fig100k 데이터 세트에서 모델을 훈련할 때 80GB NVIDIA A100 그래픽 카드 8개를 사용했습니다.
실험 결과
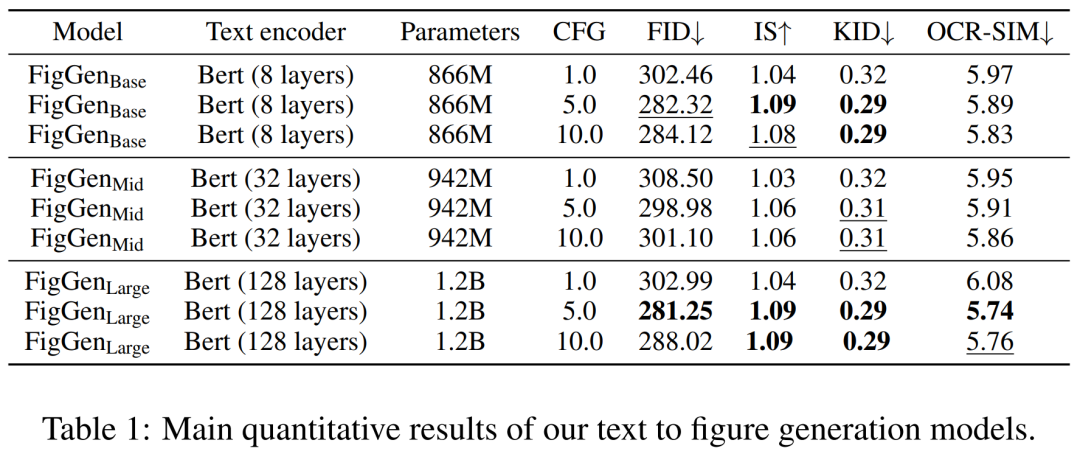
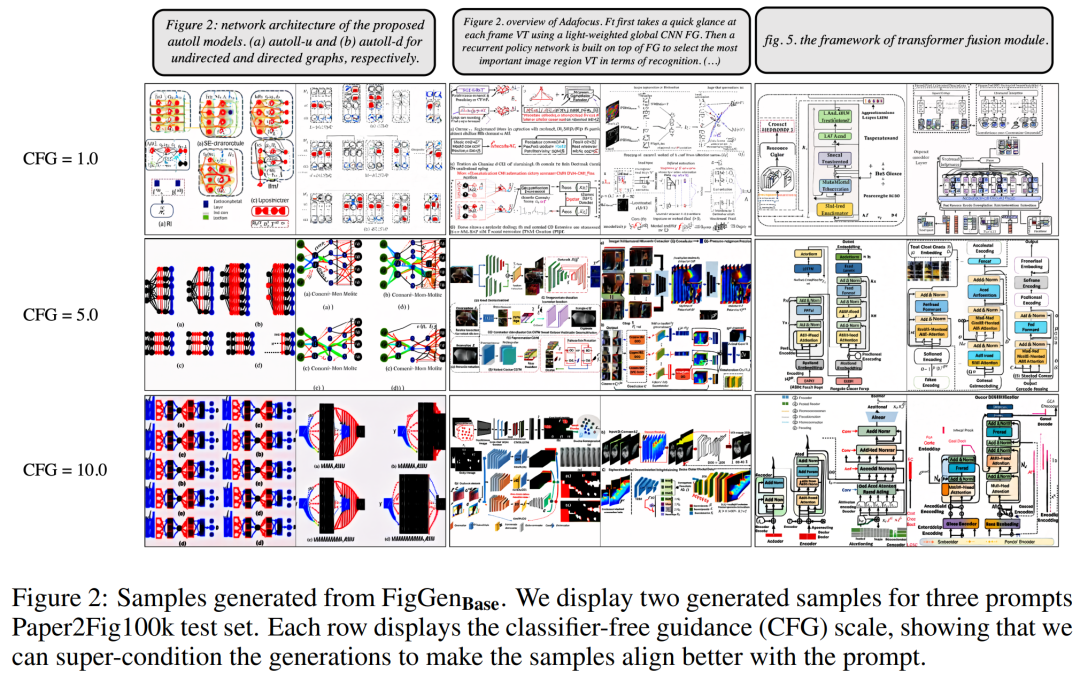
생성 과정에서 연구진은 200단계의 DDIM 샘플러를 채택하고 각 모델별로 12,000개의 샘플을 생성하여 FID, IS, KID 및 OCR-SIM1을 계산했습니다. 하이퍼컨디셔닝을 테스트하기 위해 CFG(분류 없는 지침)를 강력하게 사용합니다.
아래 표 1은 다양한 텍스트 인코더의 결과를 보여줍니다. 큰 텍스트 인코더가 최상의 정성적 결과를 생성하고 조건 생성이 CFG의 크기를 증가시킴으로써 향상될 수 있음을 알 수 있습니다. 문제를 해결하기에는 정성적 샘플의 품질이 충분하지 않지만 FigGen은 텍스트와 이미지 간의 관계를 파악했습니다.
아래 그림 2는 CFG(Classifier Free Guidance) 매개변수를 조정할 때 생성된 추가 FigGen 샘플을 보여줍니다. 연구진은 정량적으로도 입증된 CFG의 크기를 늘리면 이미지 품질이 향상되는 것을 관찰했습니다.
 Pictures
Pictures
아래 그림 3은 FigGen의 더 많은 세대 예제를 보여줍니다. 샘플 간의 길이 변화와 텍스트 설명의 기술 수준에 주의하세요. 이는 모델이 이해할 수 있는 이미지를 올바르게 생성하는 난이도에 밀접한 영향을 미칩니다.
 Pictures
Pictures
그러나 연구원들은 생성된 차트가 논문 작성자에게 실질적인 도움을 제공할 수는 없지만 여전히 탐색할 수 있는 유망한 방향임을 인정했습니다.
자세한 연구 내용은 원본 논문을 참고해주세요.
위 내용은 확산 모델을 사용하여 종이 일러스트레이션을 자동으로 생성할 수도 있으며 ICLR에서도 허용됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!