
Meta, 단 2초 만에 실제 사람의 음성을 시뮬레이션하는 오디오 AI 모델 출시

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-21 15:20:171746검색
최근 Meta는 오디오 시뮬레이션에 상당한 이점을 제공하는 Voicebox AI 모델을 출시했습니다.
Voicebox는 오디오 세부 사항과 음색을 정확하게 식별하고 텍스트 결과를 기반으로 음성 출력으로 변환하기 위해 2초의 오디오 샘플만 필요하다고 보고되었습니다.

Voicebox는 오디오 편집, 샘플링 및 스타일링을 돕는 생성적 AI 모델입니다.
이 기술은 제작자가 나중에 오디오 트랙을 쉽게 편집하는 데 도움이 되는 동시에 성대가 손상된 사람들에게 도움을 제공하고 다시 "소리"를 내는 데 도움이 될 수 있습니다. 시각 장애가 있는 사람들은 친구가 쓴 메시지를 소리로 들을 수 있고, 어떤 외국어라도 자신의 목소리로 말할 수 있습니다.
동시에 음성 클립의 이전 및 다음 콘텐츠를 기반으로 누락된 콘텐츠를 자동으로 채울 수도 있습니다.
Meta에 따르면 Voicebox는 미래의 메타버스에서 AI 비서나 NPC에게 자연스럽고 사실적인 음성 효과를 제공하여 사용자의 몰입감을 크게 향상시킬 수 있다고 합니다.
Voicebox의 다용성은 다음을 포함한 다양한 작업을 지원합니다.
상황에 맞는 텍스트 음성 변환 합성: Voicebox는 2초 정도의 짧은 오디오 샘플을 사용하여 오디오 스타일을 일치시키고 이를 텍스트 음성 변환 생성에 사용할 수 있습니다.
음성 편집 및 소음 감소: Voicebox는 전체 음성을 다시 녹음할 필요 없이 소음으로 인해 중단된 음성 부분을 다시 생성하거나 잘못 말한 단어를 대체할 수 있습니다. 예를 들어 개가 짖는 소리 때문에 중단된 음성 세그먼트를 식별하고 잘라낸 다음 오디오 편집을 위한 지우개처럼 Voicebox에 세그먼트를 재생성하도록 지시할 수 있습니다.
교차 언어 변환: 누군가의 음성 샘플과 영어, 프랑스어, 독일어, 스페인어, 폴란드어 또는 포르투갈어로 된 텍스트가 주어지면 Voicebox는 샘플 음성과 텍스트가 다른 경우에도 이러한 언어 중 하나로 텍스트 읽기를 생성할 수 있습니다. 언어. 앞으로 사람들은 이 기능을 사용하여 언어를 이해하지 못하더라도 보다 자연스럽고 진정성 있는 방식으로 의사소통을 할 수 있게 될 것입니다.
Flow Matching은 Voicebox에서 사용하는 방법으로 확산 모델의 성능을 향상시키는 것으로 나타났습니다. Voicebox는 명료도(5.9% 대 1.9% 단어 오류율)와 오디오 유사성(0.580 대 0.681)에서 현재 최첨단 영어 모델인 VALL-E보다 성능이 뛰어나며 속도는 20배 더 빠릅니다. 언어 간 스타일 전송의 경우 Voicebox는 YourTTS보다 성능이 뛰어나 평균 단어 오류율을 10.9%에서 5.2%로 줄이고 오디오 유사성을 0.335에서 0.481로 향상시킵니다.
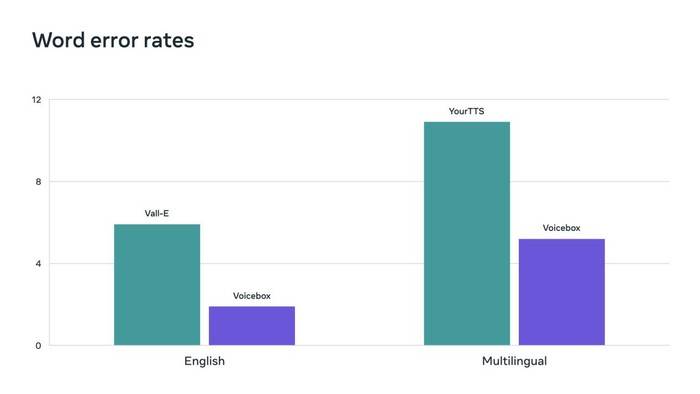
Voicebox는 단어 오류율에서 Vall-E 및 YourTTS를 능가하는 새로운 최첨단 결과를 달성합니다.
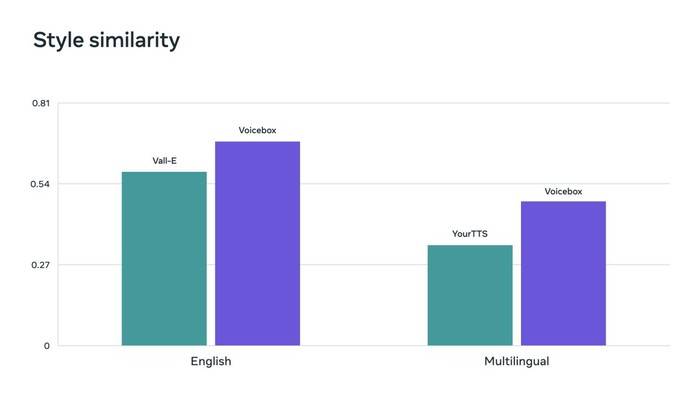
Voicebox는 또한 영어 및 다국어 벤치마크에서 각각 오디오 스타일 유사성 지표에 대한 최첨단 결과를 달성합니다.
메타는 현재 위조 분야에서 Voicebox를 사용할 경우 발생할 수 있는 잠재적인 피해를 인지하고 실제 음성과 Voicebox에서 생성된 음성을 구별할 수 있는 방법을 찾고 있다는 점을 언급할 가치가 있습니다.
메타는 해결책이 나올 때까지 불필요한 피해를 피하기 위해 보이스박스 AI 모델을 대중에게 공개하지 않을 것입니다.
편집자 코멘트: AI는 이제 다양한 분야에 적용되어 작업 일반화를 성공적으로 수행하는 최초의 다기능 및 효율적인 모델로서 Voicebox가 음성 생성 AI의 새로운 시대를 열 수 있다고 믿습니다. Meta가 오디오 사기에 효과적으로 대처할 수 없는 경우 Voicebox 기술이 비활성화될 수 있습니다.
위 내용은 Meta, 단 2초 만에 실제 사람의 음성을 시뮬레이션하는 오디오 AI 모델 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!