
데이터에 라벨을 붙일 필요가 없습니다. '3D 이해'가 다중 모달 사전 학습 시대로 들어갑니다! ULIP 시리즈는 완전 오픈 소스이며 SOTA를 새로 고칩니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-20 17:33:061441검색
다중 모드 사전 학습 방법은 3D 모양, 2D 이미지 및 해당 언어 설명을 정렬하여 3D 표현 학습의 개발도 촉진합니다.
그러나 기존 다중 모드 사전 훈련 프레임워크데이터 수집 방법에는 확장성이 부족하여 다중 모드 학습의 잠재력을 크게 제한하는 주요 병목 현상은 언어 양식의 확장성에 있습니다.
최근 Salesforce AI는 스탠포드 대학교 및 오스틴에 있는 텍사스 대학교와 협력하여 3D 이해의 새로운 장을 선도하는 ULIP(CVP R2023) 및 ULIP-2 프로젝트를 출시했습니다.

논문 링크: https://arxiv.org/pdf/2212.05171.pdf
논문 링크: https://arxiv.org/pdf/2305.08275.pdf
코드 링크: https://github.com/salesforce/ULIP
연구원들은 고유한 접근 방식을 사용하여 3D 포인트 클라우드, 이미지 및 텍스트를 사용하여 모델을 사전 학습하고 이를 통합된 기능 공간으로 정렬했습니다. . 이 접근 방식은 3D 분류 작업에서 최첨단 결과를 달성하고 이미지-3D 검색과 같은 도메인 간 작업에 대한 새로운 가능성을 열어줍니다.
그리고 ULIP-2를 사용하면 수동 주석 없이 이러한 다중 모드 사전 훈련이 가능하므로 대규모로 확장할 수 있습니다.
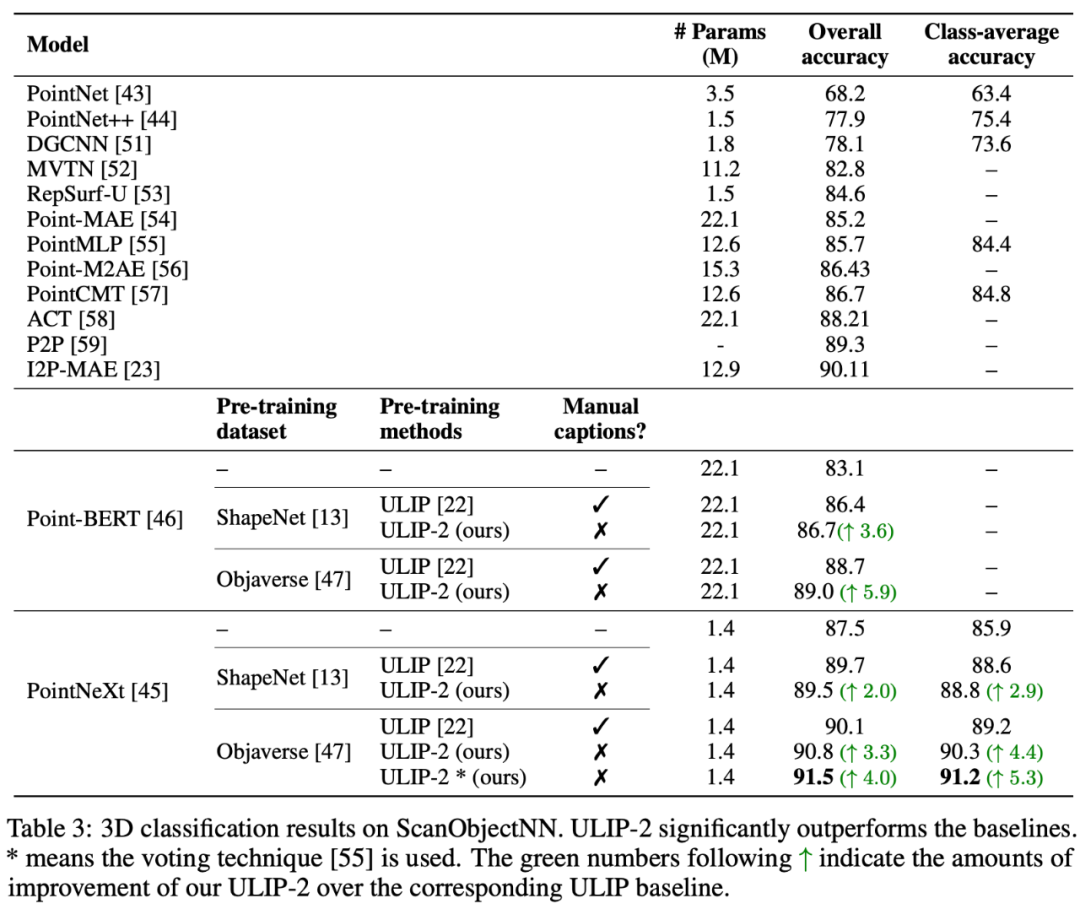
ULIP-2는 ModelNet40의 다운스트림 제로샷 분류에서 상당한 성능 개선을 달성하여 실제 ScanObjectNN 벤치마크에서 74.0%의 최고 정확도를 달성했으며 전체 정확도는 91.5%에 불과했습니다. 사람이 3D 주석을 달 필요 없이 확장 가능한 다중 모드 3D 표현을 학습하는 데 획기적인 발전을 이루었습니다.
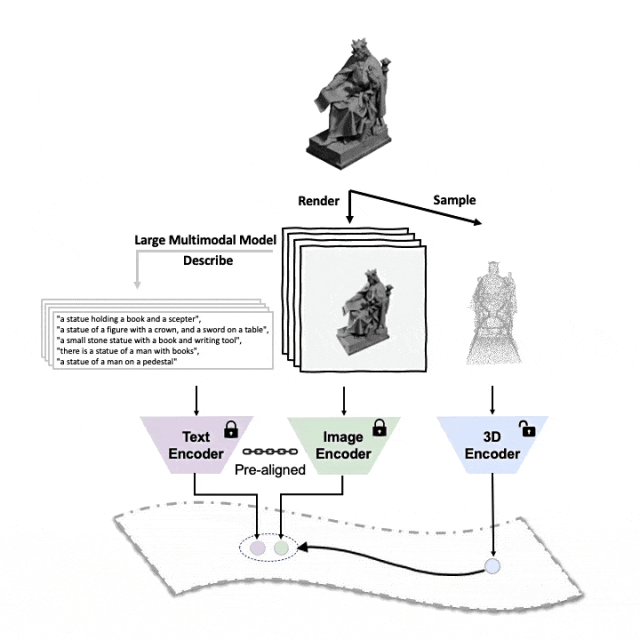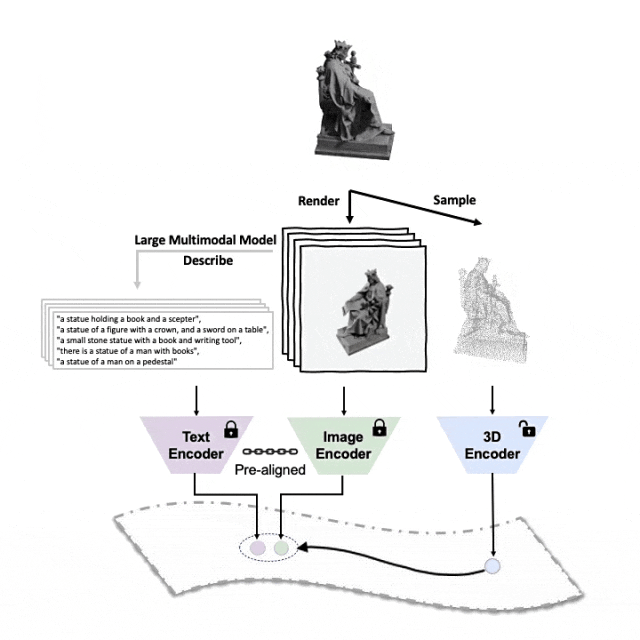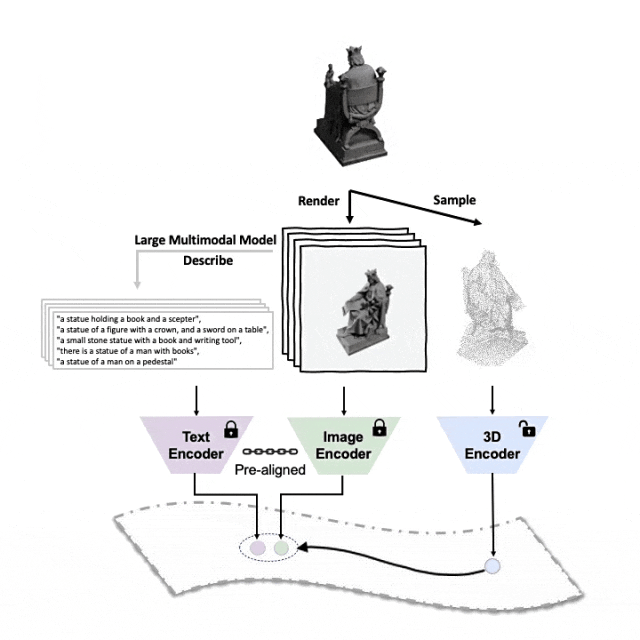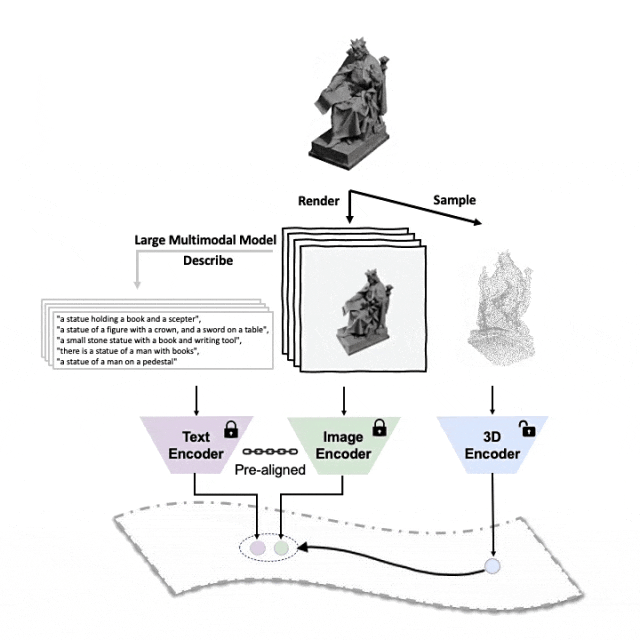
이 세 가지 기능(3D, 이미지, 텍스트)을 정렬하기 위한 사전 학습 프레임워크의 도식 다이어그램
코드와 공개된 대규모 삼중 모달 데이터 세트(" ULIP - Objaverse Triplets" 및 "ULIP - ShapeNet Triplets")가 오픈 소스로 제공되었습니다.
Background
3D 이해는 기계가 인간처럼 3차원 공간에서 인지하고 상호 작용할 수 있게 하는 인공지능 분야의 중요한 부분입니다. 이 기능은 자율주행차, 로봇 공학, 가상 현실, 증강 현실과 같은 분야에서 중요한 응용 분야를 가지고 있습니다.
그러나 3D 이해는 3D 데이터 처리 및 해석의 복잡성과 3D 데이터 수집 및 주석 작성 비용으로 인해 항상 큰 어려움에 직면해 왔습니다.
ULIP
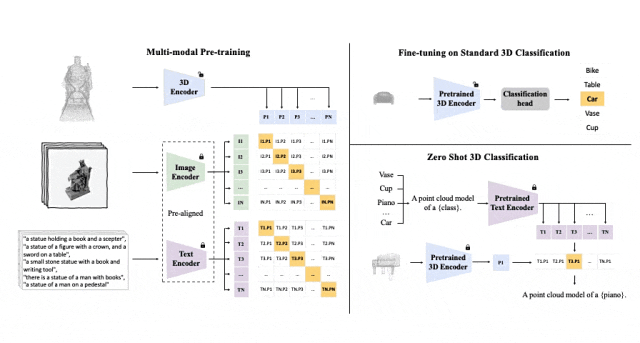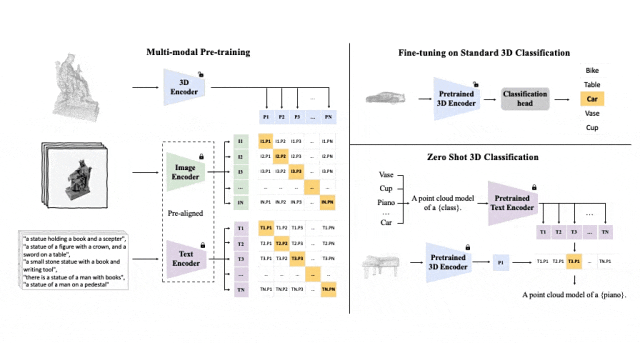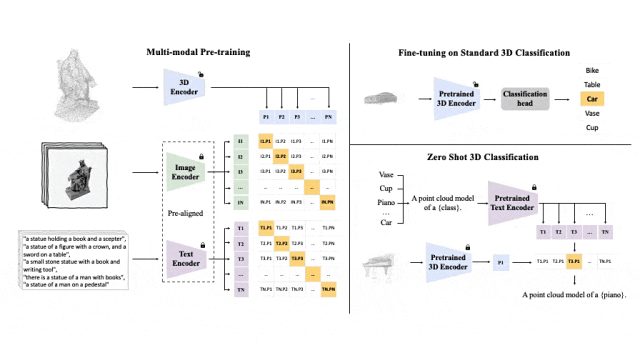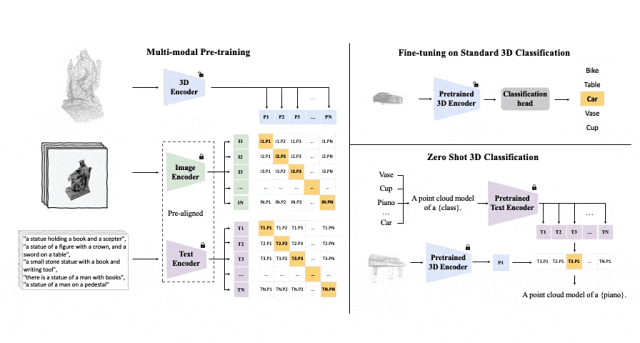
Tri-modal 사전 훈련 프레임워크 및 해당 다운스트림 작업
ULIP(CVPR2023에서 이미 승인됨)은 3D 포인트 클라우드, 이미지 및 텍스트를 사용하는 고유한 접근 방식을 채택했습니다. - 모델을 통일된 표현 공간으로 정렬하기 위해 훈련되었습니다.
이 접근 방식은 3D 분류 작업에서 최첨단 결과를 달성하고 이미지-3D 검색과 같은 도메인 간 작업에 대한 새로운 가능성을 열어줍니다.
ULIP 성공의 열쇠는 수많은 이미지-텍스트 쌍에 대해 사전 훈련된 CLIP과 같은 사전 정렬된 이미지 및 텍스트 인코더를 사용하는 것입니다.
이 인코더는 세 가지 양식의 기능을 통합된 표현 공간으로 정렬하여 모델이 3D 객체를 보다 효과적으로 이해하고 분류할 수 있도록 합니다.
이 향상된 3D 표현 학습은 3D 데이터에 대한 모델의 이해를 향상시킬 뿐만 아니라 3D 인코더가 다중 모드 컨텍스트를 획득하므로 제로샷 3D 분류 및 이미지-3D 검색과 같은 교차 모드 응용 프로그램도 가능하게 합니다.
ULIP의 사전 훈련 손실 함수는 다음과 같습니다.
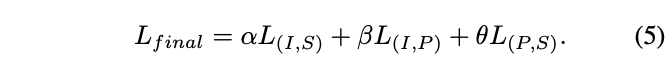
ULIP의 기본 설정에서 α는 0으로 설정되고 β와 θ는 1로 설정되며 각 두 양식 간의 대비는 다음과 같습니다. 학습된 손실 함수의 정의는 다음과 같습니다. 여기서 M1과 M2는 세 가지 모드 중 두 가지 모드를 나타냅니다.
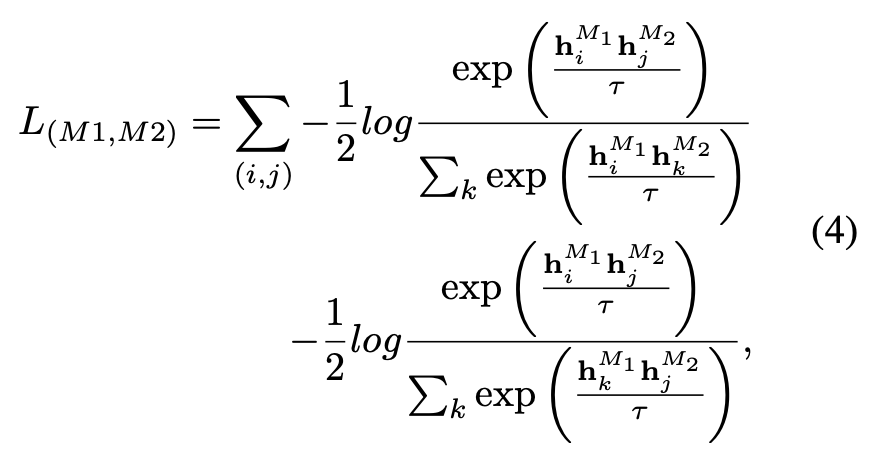
ULIP도 이미지에서 3D로 검색하는 실험을 수행했으며 그 효과는 다음과 같습니다.

실험 결과는 ULIP 사전 훈련된 모델이 이미지와 3D 포인트 클라우드 간의 의미 있는 다중 모드 특징을 학습할 수 있음을 보여줍니다.
놀랍게도 검색된 다른 3D 모델에 비해 첫 번째 검색된 3D 모델이 쿼리 이미지와 가장 가까운 모습을 보입니다.
예를 들어 검색(두 번째 및 세 번째 행)을 위해 다양한 항공기 유형(전투기 및 여객기)의 이미지를 사용할 때 검색된 가장 가까운 3D 포인트 클라우드는 여전히 쿼리 이미지의 미묘한 차이를 유지합니다.
ULIP-2
다음은 3D 객체의 다각도 텍스트 설명을 생성하는 예입니다. 먼저 3D 개체를 일련의 시점에서 2D 이미지로 렌더링한 다음 대규모 멀티모달 모델을 사용하여 생성된 모든 이미지에 대한 설명을 생성합니다
ULIP-2 ULIP를 기반으로 대규모 멀티모달 모델을 사용합니다. 3D 객체에 대한 모달 모델은 수동 주석 없이 확장 가능한 다중 모달 사전 학습 데이터를 수집하기 위해 만능 해당 언어 설명을 생성하여 사전 학습 프로세스와 학습된 모델을 보다 효율적으로 만들고 적응성을 향상시킵니다.
ULIP-2의 방법에는 각 3D 개체에 대해 다중 각도 및 다양한 언어 설명을 생성한 다음 이러한 설명을 사용하여 3D 개체, 2D 이미지 및 언어 설명이 특징 공간에 정렬되도록 모델을 교육하는 것이 포함됩니다.
이 프레임워크를 사용하면 수동 주석 없이 대규모 삼중 모달 데이터 세트를 생성할 수 있으므로 다중 모달 사전 학습의 잠재력을 완전히 실현할 수 있습니다.
ULIP-2는 또한 생성된 대규모 3개 모달 데이터 세트인 "ULIP - Objaverse Triplets" 및 "ULIP - ShapeNet Triplets"를 출시했습니다.

두 가지 삼중 모드 데이터 세트의 일부 통계
실험 결과
ULIP 시리즈는 다중 모드 다운스트림 작업 및 3D 표현에 대한 미세 조정 실험에서 놀라운 결과를 얻었습니다. - ULIP-2 교육은 수동 주석 없이도 달성할 수 있습니다.
ULIP-2는 실제 ScanObjectNN 벤치마크에서 ModelNet40의 다운스트림 제로샷 분류 작업에서 상당한 개선(74.0% 상위 1 정확도)을 달성했으며 단 1.4M 매개변수만으로 이를 달성했습니다. 전체 정확도 91.5 %는 수동 3D 주석이 필요 없는 확장 가능한 다중 모드 3D 표현 학습의 획기적인 발전을 의미합니다.
절제 실험
두 논문 모두 상세한 절제 실험을 수행했습니다.
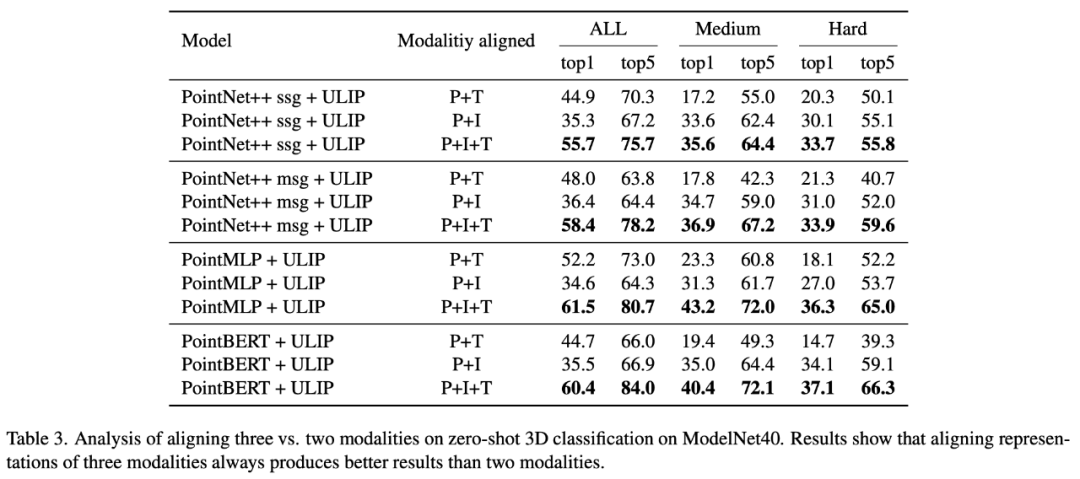
"ULIP: 3D 이해를 위한 언어, 이미지 및 포인트 클라우드의 통합 표현 학습"에서 ULIP의 사전 훈련 프레임워크는 세 가지 양식의 참여를 포함하므로 저자는 실험을 사용하여 두 가지 양식만 정렬할지 여부를 탐색했습니다. 하나의 모드를 정렬하는 것이 더 낫습니까, 아니면 세 가지 모드를 모두 정렬하는 것이 더 낫습니까? 이 방식은 훌륭하며, 이는 ULIP 사전 훈련 프레임워크의 합리성을 입증하기도 합니다.
 "ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding"에서 저자는 사전 훈련된 프레임워크에 대한 다양한 대규모 다중 모드 모델의 영향을 탐색했습니다.
"ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding"에서 저자는 사전 훈련된 프레임워크에 대한 다양한 대규모 다중 모드 모델의 영향을 탐색했습니다.
실험 결과는 사용된 대규모 다중 모드 모델의 업그레이드를 통해 ULIP-2 프레임워크 사전 훈련의 효과가 향상될 수 있으며 확실한 성장 잠재력을 가지고 있음을 보여줍니다.
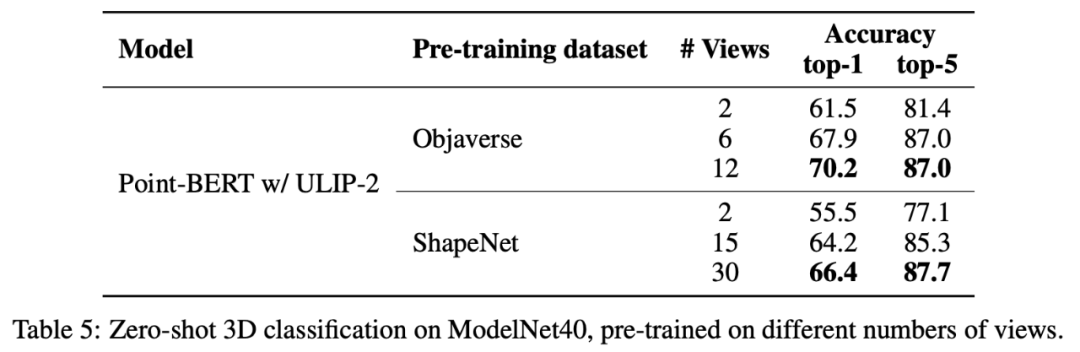
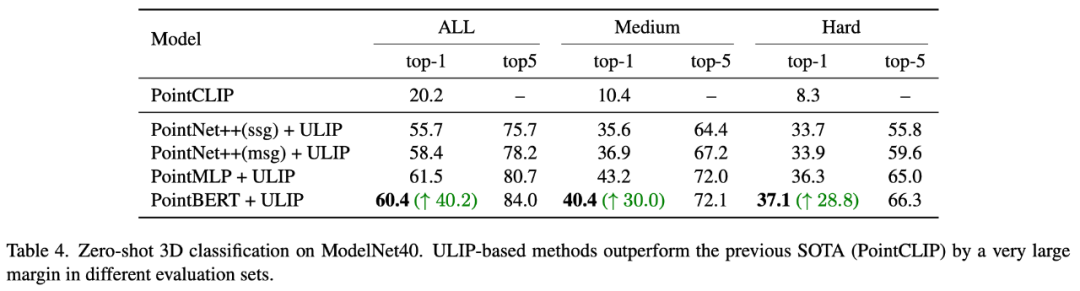 ULIP-2에서 저자는 다양한 수의 뷰를 사용하여 삼중 모달 데이터 세트를 생성하는 것이 전체 사전 훈련 성능에 어떤 영향을 미치는지 조사했습니다. 실험 결과는 다음과 같습니다.
ULIP-2에서 저자는 다양한 수의 뷰를 사용하여 삼중 모달 데이터 세트를 생성하는 것이 전체 사전 훈련 성능에 어떤 영향을 미치는지 조사했습니다. 실험 결과는 다음과 같습니다.
실험 결과 사용된 뷰 수가 증가할수록 사전 학습된 모델의 제로샷 분류 효과도 증가하는 것으로 나타났습니다.
 이는 또한 보다 포괄적이고 다양한 언어 설명이 다중 모달 사전 훈련에 긍정적인 영향을 미칠 것이라는 ULIP-2의 요점을 뒷받침합니다.
이는 또한 보다 포괄적이고 다양한 언어 설명이 다중 모달 사전 훈련에 긍정적인 영향을 미칠 것이라는 ULIP-2의 요점을 뒷받침합니다.
또한 ULIP-2는 CLIP으로 정렬된 다양한 topk의 언어 설명을 다중 모달 사전 학습에 적용하는 경우의 영향도 조사했습니다.
실험 결과는 다음과 같습니다. 다음을 보여줍니다: ULIP-2 프레임워크는 다양한 topk에 대해 어느 정도 견고성을 가지고 있으며 Top 5가 논문의 기본 설정으로 사용됩니다.
결론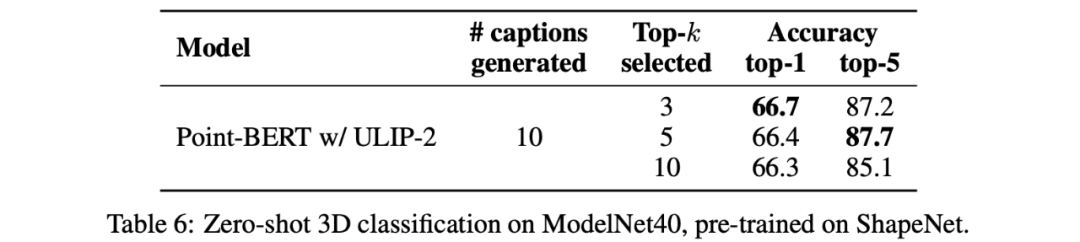
Salesforce AI와 스탠포드 대학교, 텍사스 대학교 오스틴 캠퍼스가 공동으로 발표한 ULIP 프로젝트(CVPR2023)와 ULIP-2가 3D 이해 분야를 바꾸고 있습니다.
ULIP은 다양한 양식을 통합된 공간으로 정렬하여 3D 기능 학습을 향상하고 교차 모드 애플리케이션을 가능하게 합니다.
ULIP-2는 3D 객체에 대한 전반적인 언어 설명을 생성하고, 다수의 3모달 데이터 세트를 생성 및 오픈 소스화하기 위해 추가로 개발되었으며, 이 프로세스에는 수동 주석이 필요하지 않습니다.
이 프로젝트는 3D 이해의 새로운 기준을 설정하여 기계가 3차원 세계를 진정으로 이해하는 미래를 위한 길을 열었습니다.
Team
Salesforce AI:
Le Xue, Mingfei Gao, Chen Xing, Ning Yu, Shu Zhang, Junnan Li(Li Junnan), Caiming Xiong(Xiong Caiming), Ran Xu(Xu Ran), 후안 카를로스 니에블스, 실비오 사바레세.
스탠포드 대학교:
Silvio Savarese 교수, Juan Carlos Niebles 교수, Jiajun Wu(Wu Jiajun) 교수.
UT 오스틴:
Roberto Martín-Martín 교수.
위 내용은 데이터에 라벨을 붙일 필요가 없습니다. '3D 이해'가 다중 모달 사전 학습 시대로 들어갑니다! ULIP 시리즈는 완전 오픈 소스이며 SOTA를 새로 고칩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!