
DeepMind는 AI로 정렬 알고리즘을 다시 작성하여 33B 대형 모델을 단일 소비자 GPU에 집어넣습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-12 18:49:571487검색
목차:
- 심층 강화 학습을 사용하여 발견한 더 빠른 정렬 알고리즘
- Video-LLaMA: 비디오 이해를 위한 명령 조정 오디오-비주얼 언어 모델
- 패치- 단일 예제에서 기반 3D 자연 장면 생성
- 시공간 확산점 프로세스
- SpQR: 거의 무손실 LLM 무게 압축을 위한 희소 양자화 표현
- UniControl: 제어 가능한 시각적을 위한 통합 확산 모델 Generation In the Wild
- FrugalGPT: 비용을 절감하고 성능을 향상시키면서 대규모 언어 모델을 사용하는 방법
문서 1: 심층 강화 학습을 사용하여 발견한 더 빠른 정렬 알고리즘
- 저자: Daniel J . Mankowitz 잠깐
- 문서 주소: https://www.nature.com/articles/s41586-023-06004-9
추상: "동작을 교환하고 복사하면 AlphaDev가 건너뜁니다. 잘못된 것처럼 보이지만 사실은 지름길인 방식으로 프로젝트를 연결하는 발걸음. 이 파격적이고 직관에 반하는 생각은 2016년 봄을 연상시킨다.
7년 전 AlphaGo는 바둑에서 인간 세계 챔피언을 이겼고 이제 AI는 우리에게 프로그래밍에 대한 또 다른 교훈을 가르쳐주었습니다. Google DeepMind CEO Hassabis의 두 문장은 컴퓨터 분야를 시작했습니다. "AlphaDev는 새롭고 빠른 정렬 알고리즘을 발견했으며 개발자가 사용할 수 있도록 이를 기본 C++ 라이브러리에 오픈 소스로 제공했습니다. 이것은 코드 효율성을 향상시키는 AI일 뿐입니다. 시작 "
권장사항: AI는 70% 더 빠르게 정렬 알고리즘을 다시 작성합니다. DeepMind AlphaDev는 컴퓨팅 기반을 혁신하고 라이브러리는 하루에 수조 번 업데이트됩니다.
Paper 2: Video-LLaMA: 비디오 이해를 위한 지시 조정 시청각 언어 모델
- 저자: Hang Zhang et al
- 논문 주소: https://arxiv.org/abs/ 2306.02858
요약: 최근에는 대규모 언어 모델이 인상적인 기능을 보여주었습니다. 대형 모델에 "눈"과 "귀"를 장착하여 비디오를 이해하고 사용자와 상호 작용할 수 있습니까?
이 문제에서 출발하여 DAMO 아카데미 연구진은 종합적인 시청각 기능을 갖춘 대형 모델인 Video-LLaMA를 제안했습니다. Video-LLaMA는 영상 속의 영상과 음성 신호를 인지하고 이해할 수 있으며, 사용자가 입력한 지시를 이해할 수 있고, 음성/영상 설명, 작문, 질문 및 설명 등 음성과 영상을 기반으로 일련의 복잡한 작업을 완료할 수 있습니다. 답변 등 현재 논문, 코드, 대화형 데모가 모두 열려 있습니다. 또한 연구팀은 중국 사용자들의 원활한 경험을 위해 Video-LLaMA 프로젝트 홈페이지에서 중국어 버전의 모델도 제공하고 있다.
다음 두 가지 예는 Video-LLaMA의 포괄적인 시청각 인식 기능을 보여줍니다. 이 예의 대화는 오디오 비디오를 중심으로 진행됩니다.

문서 3: 단일 예제에서 패치 기반 3D 자연 장면 생성
- 저자: Weiyu Li et al
- 논문 주소: https://arxiv.org/abs/2304.12670
요약: Peking University Chen Baoquan 팀 산동대학교와 함께 및 Tencent AI Lab 연구원들은 단일 샘플 장면을 기반으로 훈련 없이 다양한 고품질 3D 장면을 생성하는 최초의 방법을 제안했습니다.

권장: CVPR 2023 | 3D 장면 생성: 신경망 훈련 없이 단일 샘플에서 다양한 결과를 생성합니다.
논문 4: 시공간 확산점 과정
- 저자: Yuan Yuan 외
- 논문 주소: https://arxiv.org/abs/2305.12403
요약: 청화대학교 전자공학과 도시과학컴퓨팅연구센터는 최근 제한된 확률형과 모델링을 위한 높은 샘플링 비용 등 기존 방법의 한계를 뛰어넘는 시공간 확산점 프로세스를 제안했습니다. 시공간 점 처리 모델은 유연하고 효율적이며 계산이 용이한 시공간 점 처리 모델을 통해 도시 자연재해, 비상사태, 주민 활동 등 시공간 사건의 모델링 및 예측에 널리 활용될 수 있으며, 도시 계획 및 관리의 지능적인 발전을 촉진합니다. 다음 표는 기존 포인트 프로세스 솔루션에 비해 DSTPP의 장점을 보여줍니다.
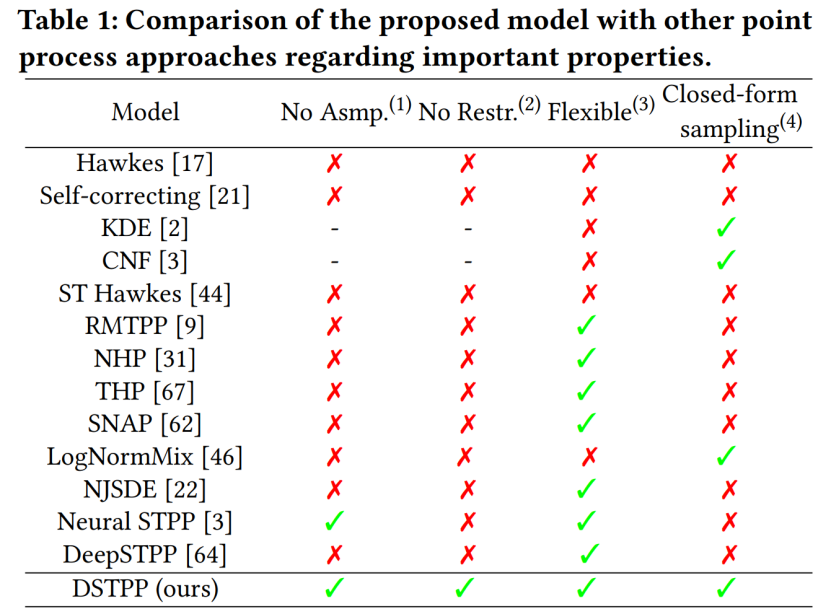
권장: 확산 모델이 지진과 범죄를 예측할 수 있나요? Tsinghua 팀의 최신 연구는 시공간 확산점 프로세스를 제안합니다.
문서 5: SpQR: 거의 손실 없는 LLM 가중치 압축을 위한 희소 양자화 표현
- 저자: Tim Dettmers 외
- 문서 주소: https://arx iv. org /pdf/2306.03078.pdf
Abstract:정확도 문제를 해결하기 위해 워싱턴 대학교, ETH Zurich 및 기타 기관의 연구자들은 새로운 압축 형식 및 양자화 기술인 SpQR(Sparse-Quantitative)을 제안했습니다. 표현), 이전 방법과 유사한 압축 수준을 달성하면서 처음으로 모델 규모 전반에 걸쳐 LLM의 거의 무손실 압축을 달성했습니다.
SpQR은 특히 큰 양자화 오류를 유발하는 비정상적인 가중치를 식별 및 격리하고 LLaMA에서 다른 모든 가중치를 3~4비트로 압축하면서 더 높은 정밀도로 저장하는 방식으로 작동합니다. 그리고 Falcon LLM. 성능 저하 없이 단일 24GB 소비자 GPU에서 33B 매개변수 LLM을 실행하는 동시에 15% 더 빨라졌습니다. 아래 그림 3은 SpQR의 전체 아키텍처를 보여줍니다.
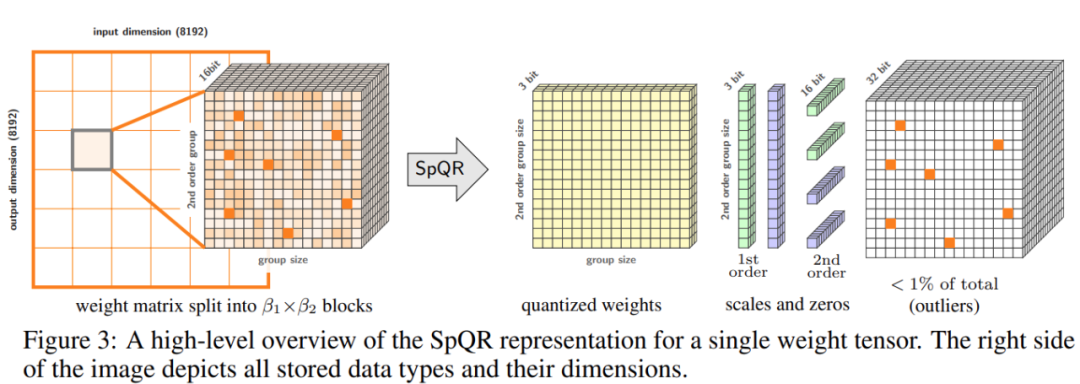
권장: "330억 매개변수의 대형 모델을 단일 소비자급 GPU에 넣어" 성능 저하 없이 15% 속도를 높입니다.
문서 6: UniControl: 야생에서 제어 가능한 시각적 생성을 위한 통합 확산 모델
Author : CAN Qin et alfpaper 주소 : https://arxiv.org/abs/2305.11147 abstract :- 이 기사에서 Salesforce AI, Northeastern University, Stanford University 연구진은 UniControl에서 다중 모드 조건 생성 기능을 실현하기 위해 MOE 스타일 어댑터와 작업 인식 HyperNet을 제안했습니다. UniControl은 9가지 C2I 작업에 대한 교육을 받았으며 강력한 시각적 생성 기능과 제로샷 일반화 기능을 보여줍니다. UniControl 모델은 여러 사전 훈련 작업과 제로샷 작업으로 구성됩니다.
- 추천: 다중 모드로 제어 가능한 이미지 생성을 위한 통합 모델이 출시되었으며 모델 매개변수와 추론 코드는 모두 오픈 소스입니다.
문서 7: FrugalGPT: 비용을 절감하고 성능을 향상시키면서 대규모 언어 모델을 사용하는 방법
 저자: Lingjiao Chen 외
저자: Lingjiao Chen 외
문서 주소: https://arxiv. org /pdf/2305.05176.pdf
요약:
- 비용과 정확성 사이의 균형은 특히 신기술을 채택할 때 의사 결정의 핵심 요소입니다. LLM을 효과적이고 효율적으로 활용하는 방법은 실무자에게 중요한 과제입니다. 작업이 상대적으로 간단한 경우 GPT-J(GPT-3보다 30배 더 작음)의 여러 응답을 집계하면 GPT-3와 유사한 성능을 얻을 수 있습니다. 비용과 환경적 균형을 달성합니다. 그러나 더 어려운 작업에서는 GPT-J의 성능이 크게 저하될 수 있습니다. 따라서 LLM을 비용 효율적으로 사용하려면 새로운 접근 방식이 필요합니다.
- 최근 연구에서 이 비용 문제에 대한 해결책을 제안하려고 시도했습니다. 연구원들은 FrugalGPT가 최대 98%의 비용 절감으로 최고의 개별 LLM(예: GPT-4)의 성능과 경쟁할 수 있음을 실험적으로 보여주었습니다. 또는 동일한 비용으로 최고의 개별 LLM의 정확도를 4% 향상시킵니다. 본 연구에서는 신속한 적응, LLM 근사화, LLM 계단식이라는 세 가지 비용 절감 전략을 논의합니다.
권장: GPT-4 API 대체? 성능은 비슷하고 비용은 98% 절감됐다. 스탠포드는 FrugalGPT를 제안했지만 연구 결과는 논란이 됐다.
위 내용은 DeepMind는 AI로 정렬 알고리즘을 다시 작성하여 33B 대형 모델을 단일 소비자 GPU에 집어넣습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!