


220시간에 걸친 미세 조정 훈련이 어제 완료되었습니다. 주요 작업은 데이터베이스 오류 정보를 보다 정확하게 진단할 수 있는 CHATGLM-6B의 대화 모델을 미세 조정하는 것이었습니다.

열흘 가까이 기다려온 이번 훈련의 최종 결과는 이전에 더 적은 샘플 범위로 했던 훈련과 비교하면 실망스러웠습니다.
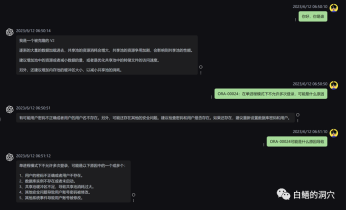
이 결과는 여전히 약간 실망 스럽습니다. 이 모델은 기본적으로 실용적인 가치가 없습니다. 매개변수와 훈련 세트를 다시 조정하고 훈련을 다시 수행해야 할 것 같습니다. 대규모 언어 모델의 훈련은 군비 경쟁이며 좋은 장비 없이는 플레이가 불가능합니다. 실험실 장비도 업그레이드해야 할 것 같습니다. 그렇지 않으면 낭비할 시간이 열흘도 채 남지 않을 것입니다.
최근 실패한 미세 조정 훈련으로 볼 때 미세 조정 훈련은 완료하기 쉬운 길이 아닙니다. 훈련을 위해 서로 다른 작업 목표가 혼합되어 있습니다. 서로 다른 작업 목표에는 서로 다른 훈련 매개변수가 필요할 수 있으므로 최종 훈련 세트는 특정 작업의 요구 사항을 충족할 수 없습니다. 따라서 PTUNING은 매우 특정 작업에만 적합하며 혼합 작업을 목표로 하는 모델에는 반드시 FINETUNE을 사용해야 할 필요가 없습니다. 며칠 전 친구와 통화할 때 다들 했던 말과 비슷하다.
사실 모델 훈련이 상대적으로 어렵기 때문에 스스로 모델 훈련을 포기하고 대신 보다 정확한 검색을 위해 로컬 지식 기반을 벡터화한 다음 AUTOPROMPT를 사용하여 검색 결과에서 자동 프롬프트를 생성하는 사람들도 있습니다. .음성 모델에 대해 물어보세요. 이 목표는 langchain을 사용하여 쉽게 달성할 수 있습니다.
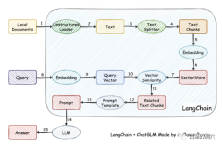
작동 원리는 로더를 통해 로컬 문서를 텍스트로 로드한 다음 텍스트를 텍스트 조각으로 분할하고 쿼리에 사용하기 위해 인코딩한 후 벡터 저장소에 쓰는 것입니다. 쿼리 결과가 나오면 Prompt Template을 통해 질문하기 위한 프롬프트가 자동으로 형성되어 LLM에게 질문하고, LLM이 최종 답변을 생성합니다.
이 작업에서 또 다른 중요한 점은 지역 지식 베이스에서 지식을 보다 정확하게 검색하는 것입니다. 이는 검색에 벡터화 및 중국어 및 검색이 수행됩니다. 영어에는 다양한 솔루션이 있습니다. 귀하의 지식 기반에 더 친숙한 솔루션을 선택할 수 있습니다.
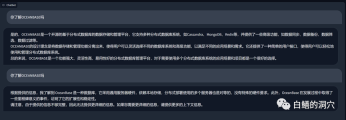
위는 OB에 관한 지식베이스를 통해 vicuna-13b에서 진행한 질문과 답변입니다. 위는 로컬 지식베이스를 사용하지 않고 LLM을 직접 사용할 수 있는 능력에 대한 답변입니다. 다음은 로컬 지식베이스에 접속한 후 로딩된 답변입니다. 성능 향상이 확실히 눈에 띄는 것을 볼 수 있습니다.

로컬 지식 베이스를 사용하기 전에는 LLM이 기본적으로 말도 안 되는 문제를 살펴보겠습니다. 텍스트도 지식 기반의 오류입니다. 실제로 PTUNING에서 사용하는 훈련 세트도 이 로컬 지식 베이스를 통해 생성됩니다.
우리는 최근에 밟은 함정으로부터 약간의 경험을 얻을 수 있습니다. 우선, 피튜닝의 난이도가 생각보다 훨씬 높습니다. 피튜닝에 비해 필요한 장비는 적지만, 훈련 난이도는 전혀 낮지 않습니다. 둘째, LLM 기능을 향상시키기 위해 Langchain과 자동 프롬프트를 통해 로컬 지식 베이스를 사용하는 것이 좋습니다. 대부분의 기업 애플리케이션에서는 로컬 지식 베이스를 정리하고 적합한 벡터화 솔루션을 선택하면 다음과 같은 결과를 얻을 수 있습니다. PTUNING/FINETUNE 효과보다 나쁘지 않습니다. 셋째, 지난번에도 언급했듯이 LLM의 능력이 중요합니다. 사용할 기본 모델로 강력한 LLM을 선택해야 합니다. 모든 임베디드 모델은 기능을 부분적으로만 향상시킬 수 있으며 결정적인 역할을 할 수 없습니다. 넷째, 데이터베이스 관련 지식에 있어서 vicuna-13b는 정말 좋은 능력을 가지고 있습니다.
오늘 아침 일찍 고객님께 연락을 드려야 하는데 오전에는 시간이 부족해서 몇 문장만 쓰겠습니다. 이에 대해 어떻게 생각하시나요? 토론을 위한 메시지를 남겨주세요. (토론 내용은 귀하와 저에게만 표시됩니다.) 저 또한 이 길을 혼자 걷고 있으니 조언을 해줄 수 있는 동료 여행자들이 있기를 바랍니다.
위 내용은 로컬 지식 기반을 사용하여 LLM의 성능을 최적화하는 방법에 대한 기사의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

WebStorm Mac 버전
유용한 JavaScript 개발 도구

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

