
효과는 OpanAI 동급 모델의 96%에 달할 수 있으며, 국내 오픈소스 AI 언어 모델 TigerBot 출시

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-10 13:35:101198검색
6월 8일 뉴스에 따르면 국내 다중 모달 대형 언어 모델인 TigerBot이 최근 공식 출시되었으며, 70억 개의 매개 변수와 1,800억 개의 매개 변수 두 가지 버전이 현재 GitHub에 오픈 소스로 공개되어 있습니다.
▲ 사진 출처 TigerBot의 GitHub 페이지
TigerBot이 가져온 혁신은 주로 다음과 같다고 보고됩니다.
- 모델 학습성을 향상시키기 위해 감독된 미세 조정을 완료하기 위한 지침을 제공하는 혁신적인 알고리즘 제안.
- 통제 가능한 사실과 창의성을 달성하려면 앙상블 및 확률적 모델링 방법을 사용하세요.
- 병렬 훈련의 딥스피드와 같은 주류 프레임워크의 메모리 및 통신 문제를 해결하세요.
또한 이 모델은 중국어의 불규칙한 분포를 위해 토크나이저부터 학습 알고리즘까지 더욱 적합한 최적화를 수행했습니다.
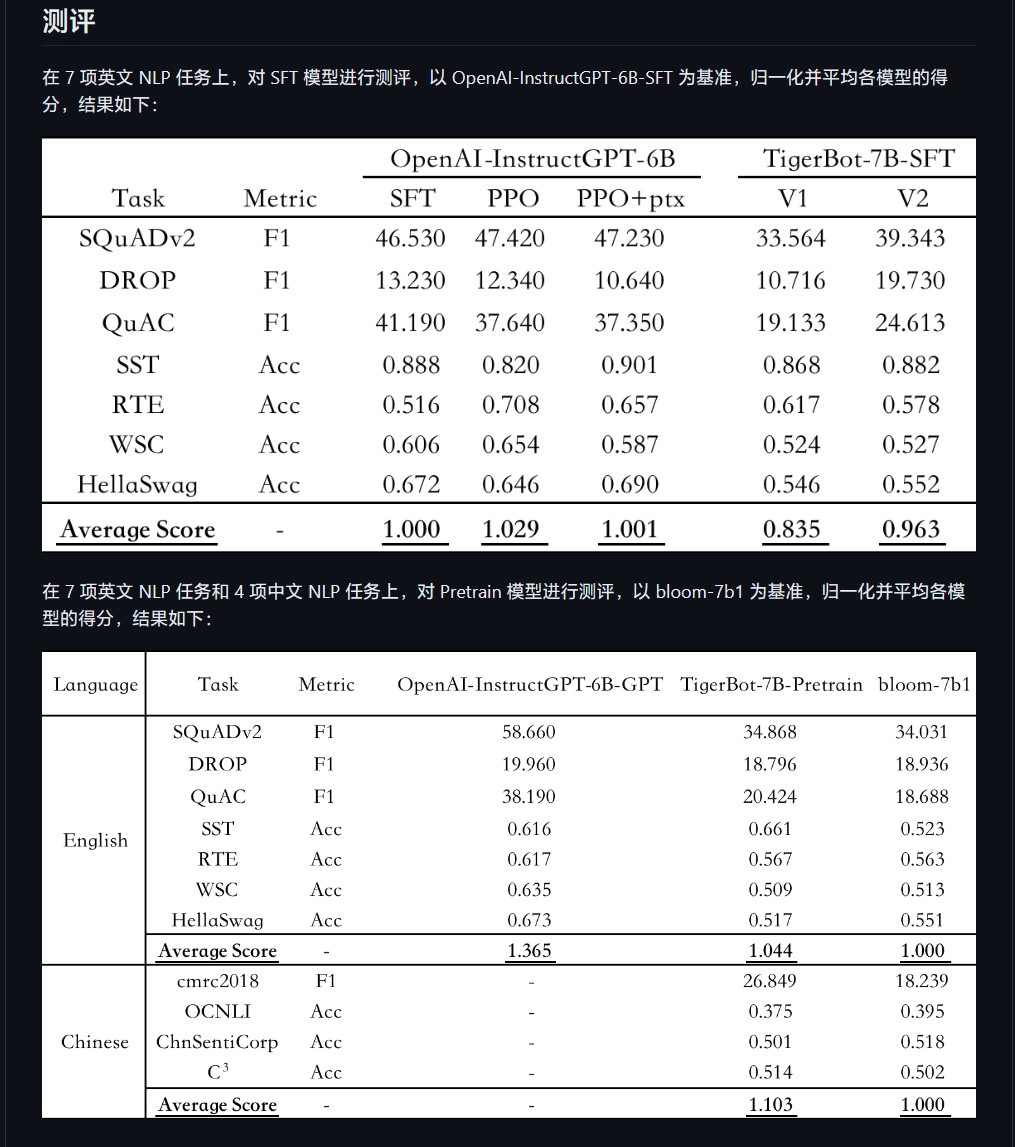
연구원 Chen Ye는 Hubo Technology의 공식 웹사이트에서 다음과 같이 말했습니다. "이 모델은 소수의 매개변수만 사용하여 인간이 어떤 종류의 질문을 하는지 빠르게 이해할 수 있습니다. 공개 NLP 데이터 세트에 대한 OpenAI InstructGPT 논문의 자동 평가에 따르면 , TigerBot-7B는 OpenAI 동일 크기 모델의 전체 성능의 96%에 도달했습니다.”
▲ 사진 출처 TigerBot의 GitHub 페이지
TigerBot-7B 기반의 성능이 “OpenAI보다 낫다”고 합니다. 동등한 비교 모델”, 오픈 소스 코드에는 듀얼 카드 추론 180B 모델에 대한 기본 훈련 및 추론 코드, 양자화 및 추론 코드가 포함되어 있습니다. 데이터에는 100G 사전 훈련 데이터와 감독된 미세 조정을 위한 1G 또는 1백만 개의 데이터가 포함됩니다.
IT House 친구들은 여기에서 GitHub의 오픈 소스 프로젝트를 찾아보세요.
위 내용은 효과는 OpanAI 동급 모델의 96%에 달할 수 있으며, 국내 오픈소스 AI 언어 모델 TigerBot 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!