
OpenAI가 상위 2위를 차지했습니다! 대형 모델 코드 생성 순위 목록이 공개되어 70억 LLaMA가 이를 능가하고 2억 5천만 Codex를 제치고 있습니다.

- 王林앞으로
- 2023-06-07 19:37:44765검색
최근 Matthias Plappert의 트윗이 LLM 서클에서 광범위한 토론을 촉발시켰습니다.
Plappert는 유명한 컴퓨터 과학자입니다. 그는 HumanEval의 AI 서클에서 주류 LLM에 대한 벤치마크 테스트 결과를 발표했습니다.
그의 테스트는 코드 생성에 편향되어 있습니다.
결과는 충격적이기도 하고 충격적이기도 합니다.

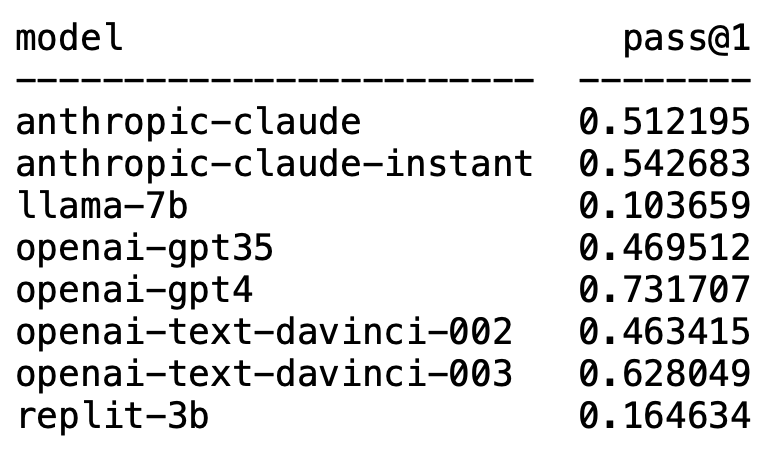
예기치 않게 GPT-4가 의심할 여지없이 목록을 장악하고 1위를 차지했습니다.
뜻밖의 OpenAI의 text-davinci-003이 갑자기 등장해 2위를 차지했습니다.
플래퍼트는 text-davinci-003이 '보물' 모델이라고 할 수 있다고 하더군요.
잘 알려진 LLaMA는 코드 생성에 능숙하지 않습니다.
OpenAI가 목록을 지배합니다
Plappert는 GPT-4의 성능이 문헌의 데이터보다 훨씬 낫다고 말했습니다.
논문에 실린 GPT-4의 1차 테스트 데이터는 합격률이 67%인 반면, Plappert의 테스트는 73%에 달했습니다.

원인을 분석해보면 데이터 차이가 있을 가능성이 많다고 하더군요. 그 중 하나는 그가 GPT-4에 제시한 프롬프트가 논문 작성자가 테스트했을 때보다 약간 더 좋았다는 것입니다.
또 다른 이유는 종이에서 GPT-4를 테스트했을 때 모델의 온도가 0이 아니라고 추측했기 때문입니다.
"온도"는 텍스트 생성 시 모델의 창의성과 다양성을 조정하는 데 사용되는 매개변수입니다. "온도"는 0보다 큰 값, 일반적으로 0과 1 사이입니다. 모델이 텍스트를 생성할 때 샘플링된 예측 단어의 확률 분포에 영향을 미칩니다.
모델의 "온도"가 더 높을 때(예: 0.8, 1 이상) 모델은 더 다양하고 다양한 단어 중에서 선택하려는 경향이 높아지며, 이는 생성된 텍스트를 더욱 위험하고 창의적으로 만듭니다. 하지만 더 많은 오류와 불일치가 발생할 가능성도 있습니다.
그리고 "온도"가 낮은 경우(예: 0.2, 0.3 등) 모델은 주로 확률이 더 높은 단어 중에서 선택하여 더 부드럽고 일관성 있는 텍스트를 생성합니다.
그러나 이 시점에서는 생성된 텍스트가 너무 보수적이고 반복적으로 보일 수 있습니다.
따라서 실제 적용에서는 특정 요구에 따라 적절한 "온도" 값을 계량하고 선택해야 합니다.
다음으로 text-davinci-003에 대해 Plappert는 댓글을 달면서 이 모델도 OpenAI에서 매우 유능한 모델이라고 말했습니다.
GPT-4만큼 좋지는 않지만 한 번의 테스트에서 62%의 합격률로 2위를 확보했습니다.
Plappert는 text-davinci-003의 가장 좋은 점은 사용자가 ChatGPT의 API를 사용할 필요가 없다는 점을 강조했습니다. 이는 프롬프트를 제공하는 것이 더 간단해질 수 있음을 의미합니다.
또한 Plappert는 Anthropic AI의 클로드-순간 모델에도 비교적 높은 평가를 내렸습니다.
그는 이 모델의 성능이 좋고 GPT-3.5를 이길 수 있다고 생각합니다. GPT-3.5의 합격률은 46%, clude-instant의 합격률은 54%입니다.
물론 Anthropic AI의 또 다른 LLM인 claude는 claude-instant로 플레이할 수 없으며 합격률은 51%에 불과합니다.
Plappert는 두 모델을 테스트하는 데 사용된 프롬프트가 작동하지 않으면 작동하지 않는다고 말했습니다.
이러한 친숙한 모델 외에도 Plappert는 많은 오픈 소스 소형 모델도 테스트했습니다.
Plappert는 이러한 모델을 현지에서 운영할 수 있다는 점이 좋다고 말했습니다.
그러나 규모면에서 이러한 모델은 분명히 OpenAI 및 Anthropic AI만큼 크지 않기 때문에 비교하는 것이 다소 압도적입니다.

LLaMA 코드 생성? 물론 Plappert는 LLaMA 테스트 결과에 만족하지 않았습니다.
테스트 결과에 따르면 LLaMA는 코드 생성 성능이 매우 좋지 않습니다. 아마도 GitHub에서 데이터를 수집할 때 언더샘플링을 사용했기 때문일 것입니다.
 Codex 2.5B와 비교해도 LLaMA의 성능은 동일하지 않습니다. (합격률 10% vs. 22%)
Codex 2.5B와 비교해도 LLaMA의 성능은 동일하지 않습니다. (합격률 10% vs. 22%)
 드디어 리플릿의 3B 사이즈 모델을 테스트해봤습니다.
드디어 리플릿의 3B 사이즈 모델을 테스트해봤습니다.
성능이 나쁘지 않다고 했으나 트위터에 홍보된 데이터와 비교했을 때(합격률 16% vs. 22%)
Plappert는 이 모델을 테스트했기 때문일 것이라고 믿습니다. 정량화 방법 사용하면 합격률이 몇 퍼센트 포인트 떨어졌습니다.
 리뷰 말미에 플래퍼트는 흥미로운 점을 언급했습니다.
리뷰 말미에 플래퍼트는 흥미로운 점을 언급했습니다.
A 사용자는 Twitter에서 GPT-3.5-turbo가 Azure 플랫폼의 Completion API(Chat API 대신)를 사용할 때 더 나은 성능을 발휘한다는 사실을 발견했습니다.
Plappert는 Chat API를 통해 프롬프트를 입력하는 것이 상당히 복잡할 수 있기 때문에 이 현상에 어느 정도 정당성이 있다고 믿습니다.
위 내용은 OpenAI가 상위 2위를 차지했습니다! 대형 모델 코드 생성 순위 목록이 공개되어 70억 LLaMA가 이를 능가하고 2억 5천만 Codex를 제치고 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!