
Pandas 작업을 효율적으로 완료하려면 이 8가지 ChatGPT 지침을 잘 활용하세요.

- PHPz앞으로
- 2023-06-07 17:39:561835검색
우리 모두 ChatGPT에 대해 들어봤습니다. 이는 기술 업계의 주목을 받았을 뿐만 아니라 다양한 매체에서 헤드라인을 장식하기도 했습니다.
간단한 작업에 대한 성능과 안정성에 대한 일부 비판에도 불구하고 ChatGPT는 다른 LLM(대형 언어 모델)에 비해 다양한 작업에서 우수한 성능을 발휘하며 생산성의 중요한 동인이 되었습니다.
Pandas 데이터를 정리하고 분석하기 위해 ChatGPT를 적용하면 작업 효율성이 크게 향상될 수 있습니다. 이 기사에서는 ChatGPT에 요청하여 Pandas 작업을 완료하는 방법을 알려주는 8가지 프롬프트 예제를 소개합니다.
첫 번째 팁: 역할 정의
역할 정의를 위한 첫 번째 팁:
팁: 당신은 나에게 Pandas 라이브러리 사용법을 가르쳐준 Python 교사입니다. Pandas를 사용하여 특정 작업을 수행하는 방법을 설명해 주시기를 기대합니다. 또한 설명에 코드를 보여주세요.
질문을 시작하기 전에 열 이름과 데이터 유형을 포함한 DataFrame의 구조를 알려 드렸습니다.
두 번째 팁
팁: 먼저 제가 가지고 있는 DataFrame에 대해 말씀드리겠습니다. 그럼 질문 시작하겠습니다. 다음은 Python 사전 형식으로 제공되는 열 이름과 데이터 유형입니다. 키는 열 이름을 나타내고 값은 데이터 유형을 나타냅니다.
{'store': dtype('O'), 'product_group': dtype('O'), 'product_code': dtype('int64'), 'stock_qty': dtype('int64'), 'cost ': dtype('float64'), 'price': dtype('float64'), 'last_week_sales': dtype('int64'), 'last_month_sales': dtype('int64')}
여기에서는 시뮬레이션된 데이터가 사용되었습니다. 샘플 데이터 세트를 준비했습니다. 데이터 세트 저장소 리포지토리(https://github.com/SonerYldrm/datasets)에서 다운로드할 수 있습니다. 파일 이름은 sales_data_with_stores.csv입니다.
다음은 참조용으로 제공되는 DataFrame입니다.
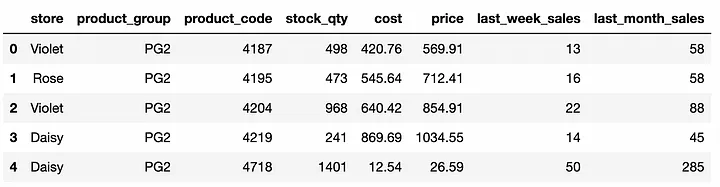
DataFrame의 처음 5개 행
이제 Pandas 작업을 시작할 수 있습니다.
예시 1
힌트: 각 매장의 지난주 매출 평균을 계산하는 방법을 알려주세요.
이것은 단순한 코드 라인이지만 Pandas를 이제 막 배우기 시작한 사람들에게는 이해하는 데 시간이 걸릴 수 있습니다. 다음은 ChatGPT에서 제공한 답변입니다.
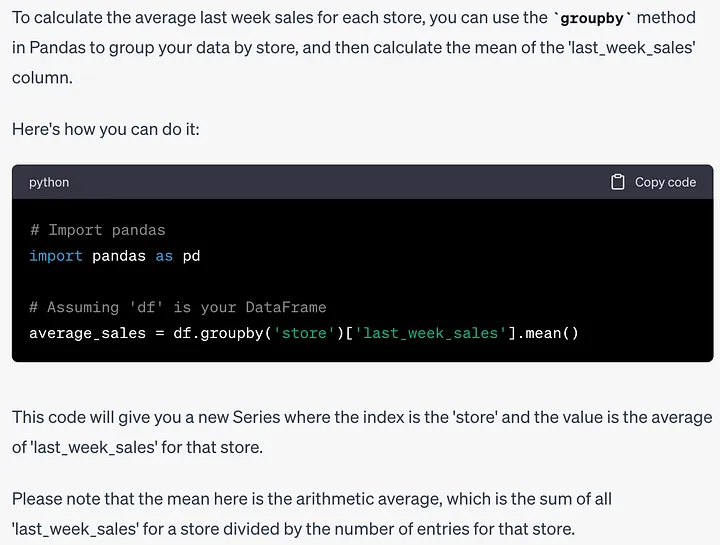
ChatGPT에서 제공한 테스트 코드 조각을 아래와 같이 복사하여 붙여넣습니다.
# 导入pandasimport pandas as pd# 假设'df'是你的DataFrameaverage_sales = df.groupby('store')['last_week_sales'].mean()
ChatGPT에서는 코드가 어떻게 실행되는지, 출력 유형에 대해 코드와 함께 자세한 설명도 제공합니다.
예시 2
힌트: 지난달 매장별 총 수익 구하는 방법을 알려주세요.
이 작업을 위해 ChatGPT는 먼저 이익을 계산하는 방법을 파악해야 합니다. 응답을 살펴보겠습니다.
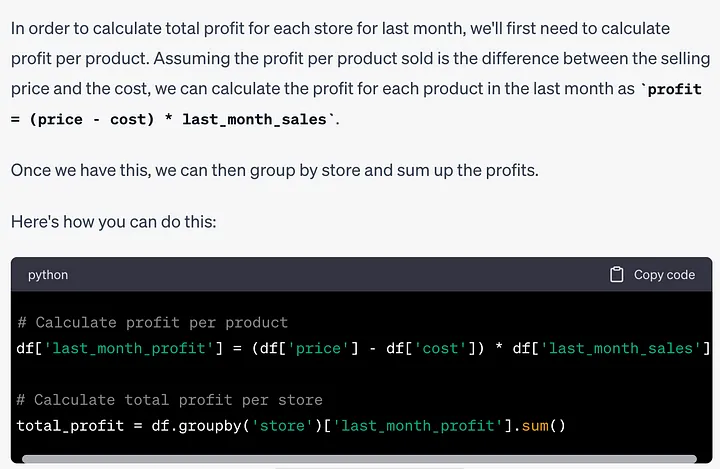
# 计算每个产品的利润df['last_month_profit'] = (df['price'] - df['cost']) * df['last_month_sales']# 计算每个商店的总利润total_profit = df.groupby('store')['last_month_profit'].sum()
예 3
실제 데이터를 처리할 때 누락된 값 문제에 자주 직면합니다. ChatGPT가 덜 간단한 작업을 어떻게 처리하는지 테스트해 보세요.
팁: 재고 수량 열에 누락된 값이 있습니다. 누락된 값을 해당 매장의 평균 재고 수량으로 바꾸고 싶습니다. 이 작업을 수행하는 방법을 알려주십시오.
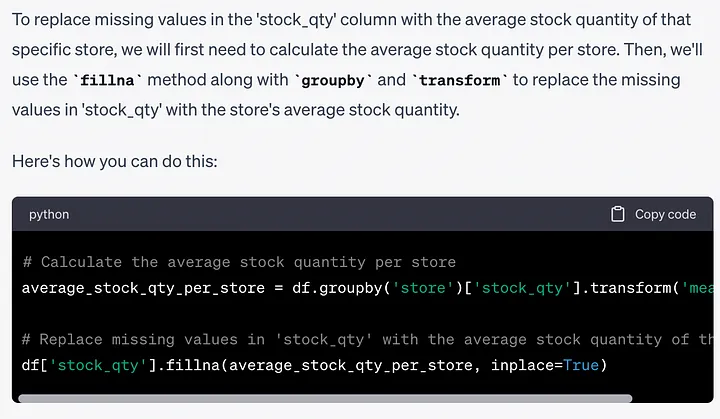
# 计算每个商店的平均库存数量average_stock_qty_per_store = df.groupby('store')['stock_qty'].transform('mean')# 用该商店的平均库存数量替换'stock_qty'中的缺失值df['stock_qty'].fillna(average_stock_qty_per_store, inplace=True)
이 작업을 해결하는 방법은 여러 가지가 있으며, 변환 기능을 사용하는 것이 가장 효과적인 방법 중 하나입니다.
변환 함수를 사용하여 이 작업을 완료하는 이유는 다음과 같습니다.
변환 함수는 적용 함수와 유사하지만 적용 함수와 달리 변환 함수는 다음과 같은 시리즈를 반환할 수 있습니다. 입력과 동일한 크기로 인해 벡터를 수행하게 됩니다. 작업 및 브로드캐스트를 수행할 때, 특히 그룹별 개체와 함께 사용할 때 유용합니다.
예시 4
힌트: 지난달 각 매장별 판매량이 가장 높은 상위 3개 제품을 찾는 방법을 알려주세요.
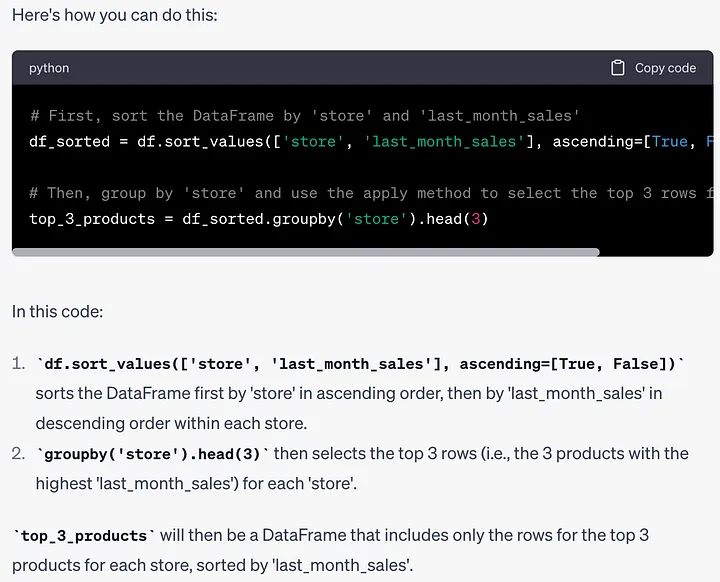
# 首先,按'store'和'last_month_sales'对DataFrame进行排序df_sorted = df.sort_values(['store', 'last_month_sales'], ascending=[True, False])# 然后,按'store'分组,并使用apply方法选择每个组的前3行top_3_products = df_sorted.groupby('store').head(3)
它首先对整个DataFrame进行排序。我们也可以在每个组内进行排序。让我们看看ChatGPT是否知道该如何做到这一点。
示例 5
提示:是否有另一种方法可以在不先对DataFrame进行排序的情况下完成此任务?
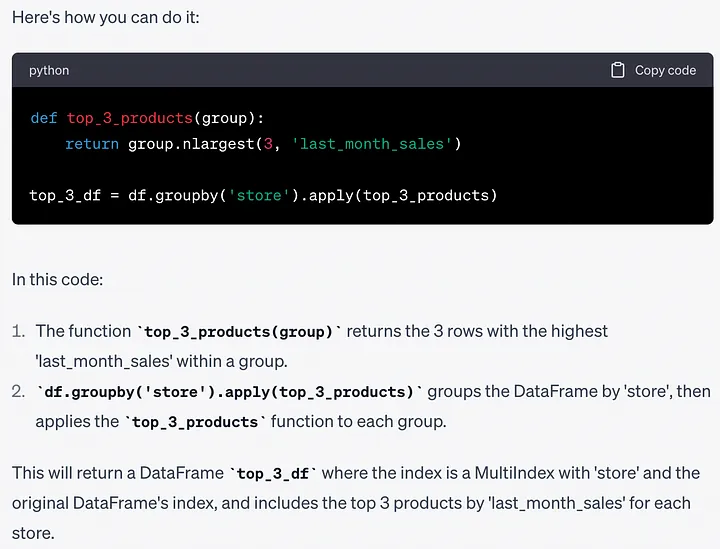
def top_3_products(group):return group.nlargest(3, 'last_month_sales')top_3_df = df.groupby('store').apply(top_3_products)
更高效的方法可能是首先对整个DataFrame进行排序。此示例只是想观察ChatGPT是否能提供不同的解决方案。
示例 6
提示:我想看到每个商店的上周表现与上月表现进行比较。
这是一个简单的任务,但提示并没有直接告诉ChatGPT如何完成。让我们看看它的表现如何。
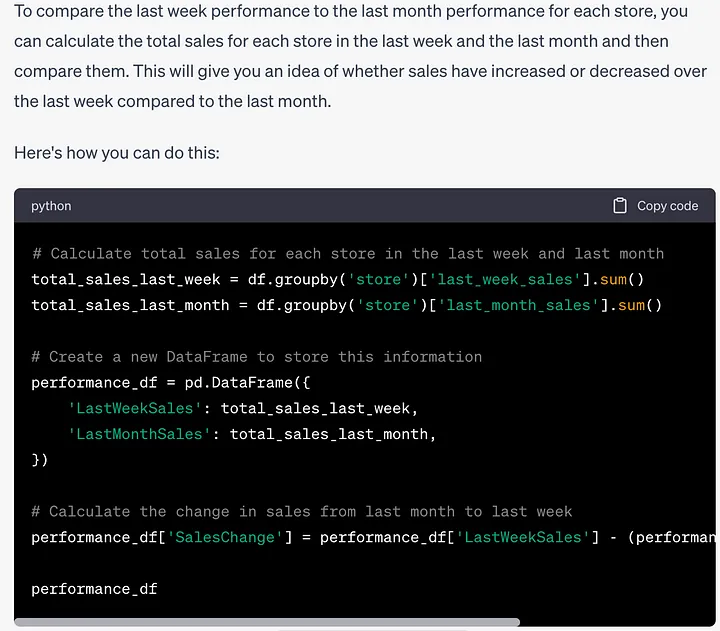
# 计算上周和上个月每个店的总销售额total_sales_last_week = df.groupby('store')['last_week_sales'].sum()total_sales_last_month = df.groupby('store')['last_month_sales'].sum()# 创建一个新的DataFrame来存储这些信息performance_df = pd.DataFrame({'LastWeekSales': total_sales_last_week,'LastMonthSales': total_sales_last_month,})# 计算从上个月到上周销售额的变化performance_df['SalesChange'] = performance_df['LastWeekSales'] - (performance_df['LastMonthSales'] / 4)
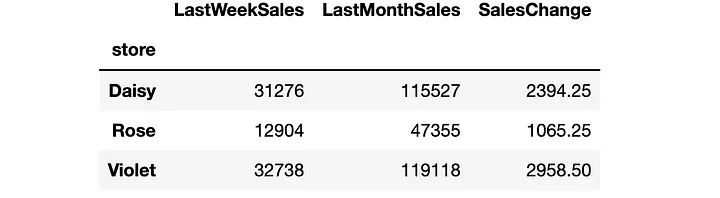
作为对上周与上月的表现相比较的反应,它找到了上周销售额与上月销售额四分之一之间存在差异,这是非常合理的。
它创建的DataFrame如下所示:
示例 7
提示:创建一个名为critical_stock的新列,如果stock_qty小于500,则取值为1,否则取值为0。
ChatGPT为这个任务给出了3个选项,以下是我更喜欢的两个:
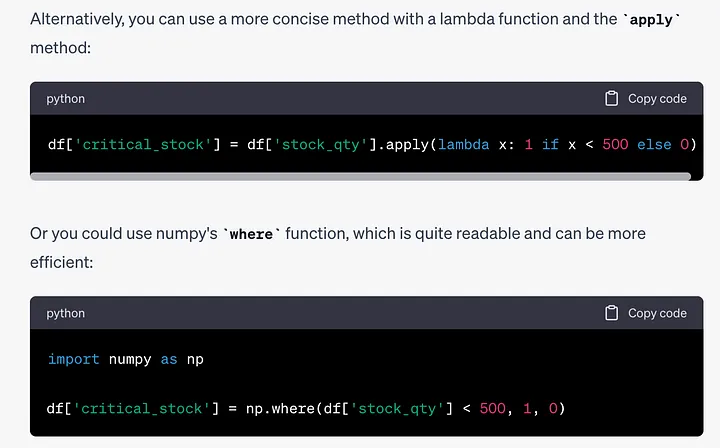
# 第一种选项df['critical_stock'] = df['stock_qty'].apply(lambda x: 1 if x <h2>示例 8</h2><blockquote style="margin-top: 5px; margin-bottom: 5px; padding-left: 1em; margin-left: 0px; border-left: 3px solid rgb(238, 238, 238); opacity: 0.6;"><p>提示:以大小、缺失值、数据类型和列统计信息的形式创建一个DataFrame的摘要。</p></blockquote><p>虽然DataFrame的函数和方法总结起来很简单,但ChatGPT在整理它们时做得非常出色,呈现出整洁清晰的排版。</p><p>如下的是ChatGPT生成的代码:</p><pre class="brush:php;toolbar:false"># 导入必要的库import pandas as pd# DataFrame大小print("DataFrame Size:")print(df.shape)print("\n")# 缺失值print("Missing Values:")print(df.isnull().sum())print("\n")# 数据类型print("Data Types:")print(df.dtypes)print("\n")# 列统计信息print("Column Statistics:")print(df.describe(include='all'))总结
以上示例展示了ChatGPT如何在数据分析中,尤其是在Pandas中,革命性地改变了常见任务的完成方式。我们不仅提高了效率,还对可以在Pandas中完成的复杂操作有了更丰富的理解。
위 내용은 Pandas 작업을 효율적으로 완료하려면 이 8가지 ChatGPT 지침을 잘 활용하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!