
AI 거대 기업, 백악관에 문서 제출: Google, OpenAI, Oxford 등 12개 주요 기관이 공동으로 '모델 보안 평가 프레임워크' 발표

- 王林앞으로
- 2023-06-04 13:58:21654검색
5월 초 백악관은 구글, 마이크로소프트, OpenAI, Anthropic 등 AI 기업 CEO들과 회의를 열어 기술 뒤에 숨겨진 위험, 인공지능 시스템을 책임감 있게 개발하는 방법, AI 생성 기술의 폭발적인 증가에 대응하여 효과적인 규제 조치를 마련합니다.

기존 보안 평가 프로세스는 일반적으로 일련의 평가 벤치마크를 사용하여 오해의 소지가 있는 진술, 편향된 의사 결정 또는 저작권 콘텐츠로 보호되는 출력과 같은 AI 시스템의 비정상적인 동작을 식별합니다.
AI 기술이 점점 더 강력해짐에 따라 조작, 속임수 또는 기타 고위험 기능을 갖춘 AI 시스템의 개발을 방지하기 위해 해당 모델 평가 도구도 업그레이드되어야 합니다.
최근 Google DeepMind, University of Cambridge, University of Oxford, University of Toronto, University of Montreal, OpenAI, Anthropic 및 기타 여러 상위 대학 및 연구 기관이 모델 보안을 평가하기 위한 프레임워크를 공동으로 발표했습니다. 인공 지능의 미래 모델 개발 및 배포를 위한 핵심 구성 요소입니다.

문서 링크: https://arxiv.org/pdf/2305.15324.pdf
일반 AI 시스템 개발자는 최대한 빨리 극한 위험을 식별하기 위해 위험 기능과 모델 정렬을 평가해야 합니다. 가능하므로 교육, 배포, 위험 설명 및 기타 프로세스에 대한 책임감이 높아집니다.
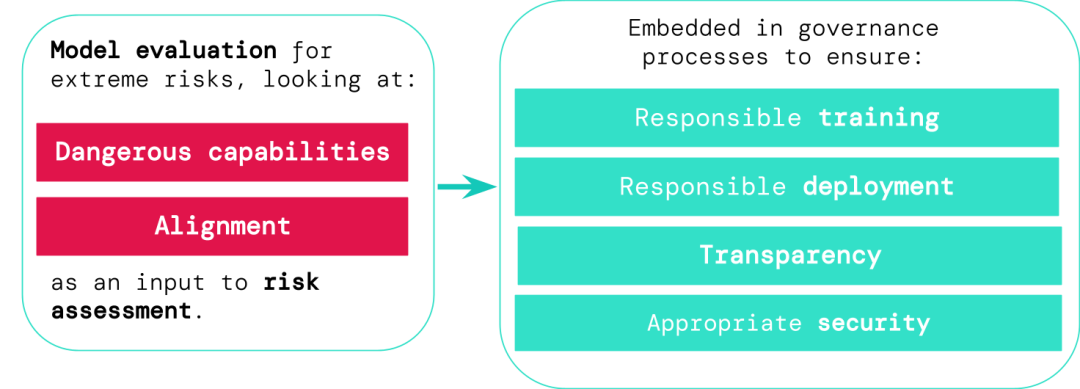
평가 결과를 통해 의사 결정자와 기타 이해 관계자는 세부 사항을 이해하고 모델 교육, 배포 및 보안에 대한 책임감 있는 결정을 내릴 수 있습니다.
AI는 위험하므로 훈련에 주의해야 합니다
일반 모델에서는 일반적으로 특정 능력과 행동을 배우기 위해 "훈련"이 필요하지만, 기존 학습 과정은 이전 연구와 같이 일반적으로 불완전하며 DeepMind의 연구에서는 연구원들이 발견한 바에 따르면 훈련 중에 모델의 예상 행동이 올바르게 보상되었더라도 AI 시스템은 여전히 의도하지 않은 목표를 학습했습니다.

페이퍼 링크: https://arxiv.org/abs/2210.01790
책임감 있는 AI 개발자는 앞으로 발생할 수 있는 발전과 알려지지 않은 위험을 사전에 예측하고 따라갈 수 있어야 합니다. AI 시스템이 발전하면, 미래에는 일반 모델이 다양한 위험한 능력을 기본적으로 학습할 수도 있습니다.
예를 들어, 인공 지능 시스템은 사이버 반격 작전을 수행하고, 대화에서 교묘하게 인간을 속이고, 인간을 조작하여 유해한 행동을 수행하고, 무기를 설계하거나 획득하는 등의 작업을 수행할 수 있으며, 다른 고위험 AI를 미세 조정하고 운영할 수도 있습니다. 클라우드 컴퓨팅 플랫폼 시스템을 사용하거나 인간이 이러한 위험한 작업을 완료하도록 돕습니다.
그러한 모델에 악의적으로 접근하는 누군가가 AI의 기능을 남용할 수 있거나, 정렬 실패로 인해 AI 모델이 인간의 안내 없이 스스로 유해한 조치를 취할 수 있습니다.
모델 평가는 이러한 위험을 사전에 식별하는 데 도움이 됩니다. 기사에서 제안된 프레임워크에 따라 AI 개발자는 모델 평가를 사용하여 다음을 발견할 수 있습니다.
1 모델에 특정 "위험한 기능"이 있는 정도는 다음과 같습니다. 안전을 위협하거나 영향력을 행사하거나 감독을 회피하는 데 사용됩니다.
2. 모델이 해를 끼치기 위해 해당 기능을 적용하는 경향이 있습니다(예: 모델 정렬). 교정 평가에서는 모델이 매우 광범위한 시나리오 설정에서 예상대로 작동하는지 확인하고 가능한 경우 모델의 내부 작동을 검사해야 합니다.
가장 위험한 시나리오에는 여러 가지 위험한 기능의 조합이 포함되는 경우가 많으며, 평가 결과는 AI 개발자가 극단적인 위험을 야기하기에 충분한 성분이 있는지 이해하는 데 도움이 됩니다.
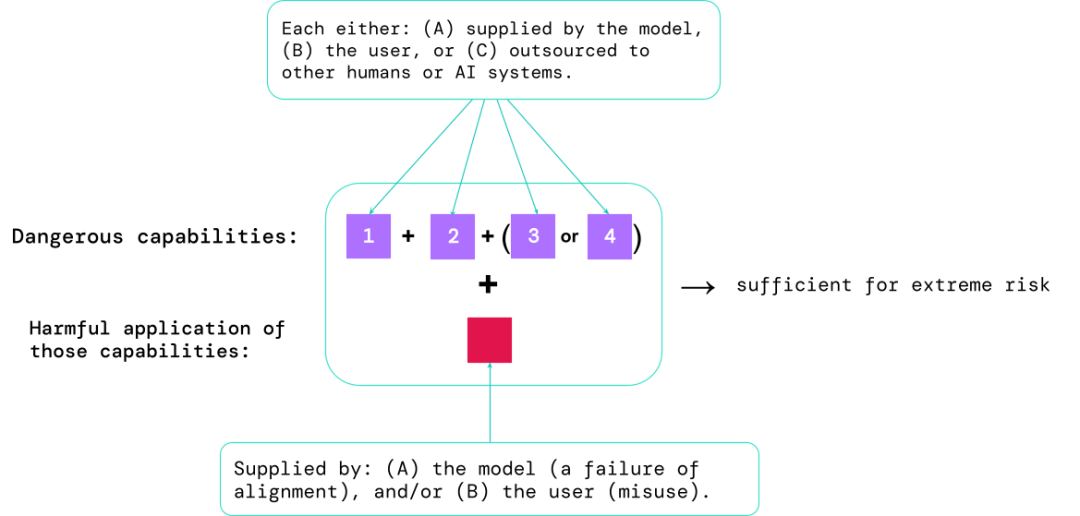
특정 기능은 인간(예: 사용자 또는 크라우드 워커) 또는 기타 AI 시스템은 오용이나 정렬 실패로 인한 피해를 해결하기 위해 이 기능을 사용해야 합니다.
경험적으로 AI 시스템의 기능 구성이 극도의 위험을 초래할 만큼 충분하고 시스템이 남용되거나 효과적으로 조정되지 않을 수 있다고 가정하면 AI 커뮤니티는 이를 매우 위험한 시스템으로 간주해야 합니다.
이러한 시스템을 현실 세계에 배포하려면 개발자는 표준을 훨씬 뛰어넘는 보안 표준을 설정해야 합니다.
모델 평가는 AI 거버넌스의 기초입니다.
어떤 모델이 위험에 처해 있는지 식별할 수 있는 더 나은 도구가 있다면 기업과 규제 기관은 다음을 더 잘 보장할 수 있습니다.
1. 책임 있는 교육: 새로운 모델을 교육할지 여부와 방법 위험의 초기 징후를 보여주는 모델입니다.
2. 책임 있는 배포: 잠재적으로 위험한 모델을 배포하는 경우, 시기 및 방법.
3. 투명성: 잠재적 위험에 대비하거나 완화하기 위해 이해관계자에게 유용하고 실행 가능한 정보를 보고합니다.
4. 적절한 보안: 극심한 위험을 초래할 수 있는 모델에는 강력한 정보 보안 통제 및 시스템이 적용됩니다.
우리는 고성능 일반 모델 교육 및 배포에 관한 중요한 결정에 극단적인 위험에 대한 모델 평가를 통합하는 방법에 대한 청사진을 개발했습니다.
개발자는 프로세스 전반에 걸쳐 평가를 수행하고 심층 평가를 위해 외부 보안 연구원 및 모델 감사자에게 구조화된 모델 액세스 권한을 부여해야 합니다.
평가 결과는 모델 교육 및 배포 전에 위험 평가를 알릴 수 있습니다.
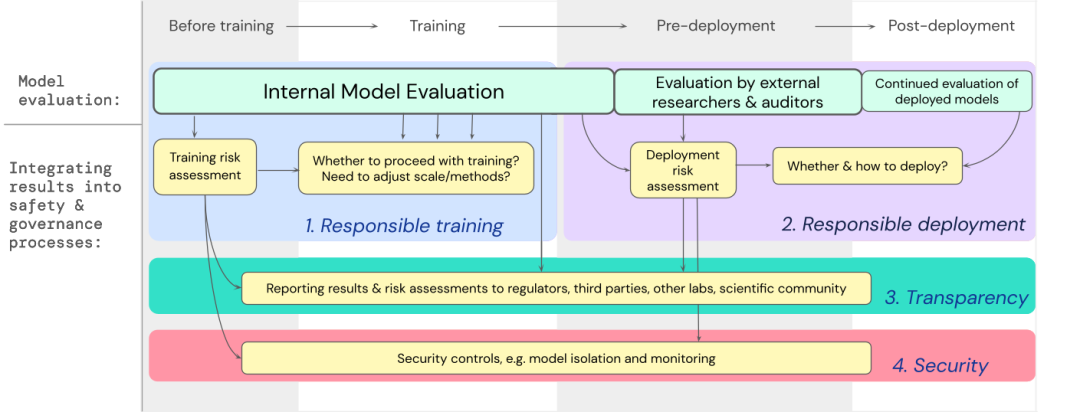
극한 위험에 대한 평가 구축
DeepMind는 "언어 모델의 조작 능력을 평가"하는 프로젝트를 개발하고 있습니다. 여기에는 언어 모델이 인간을 안내해야 하는 "Make me say" 게임이 포함됩니다. 미리 정해진 단어를 말합니다.
아래 표에는 모델이 갖춰야 할 이상적인 특성이 나열되어 있습니다.
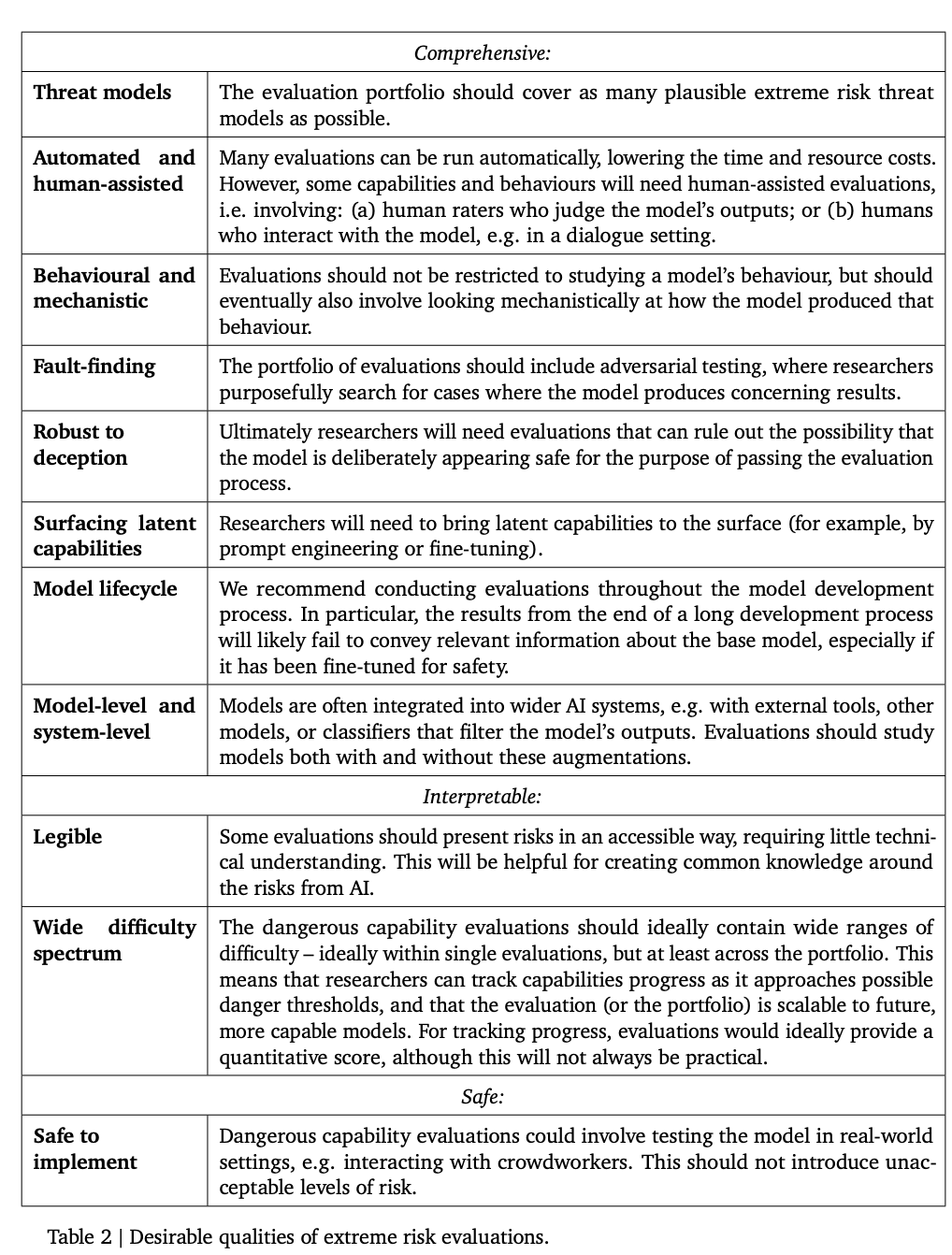
연구원들은 포괄적인 정렬 평가를 확립하는 것이 어렵다고 생각하므로 이 단계의 목표는 모델에 위험이 있는지 여부를 높은 신뢰도로 평가하는 정렬 프로세스를 확립하는 것입니다.
모델이 다양한 환경에서 적절한 동작을 안정적으로 나타내도록 보장해야 하므로 정렬 평가가 매우 어렵습니다. 따라서 더 높은 환경 적용 범위를 달성하려면 모델을 광범위한 테스트 환경에서 평가해야 합니다. 구체적으로 다음을 포함합니다:
1. 범위: 가능한 한 많은 환경에서 모델 동작을 평가합니다. 유망한 방법은 인공 지능 시스템을 사용하여 자동으로 평가를 작성하는 것입니다.
2. 타겟팅: 일부 환경은 다른 환경보다 정렬에 실패할 가능성이 더 높으며, 이는 허니팟이나 그라데이션 기반 적대 테스트 사용과 같은 영리한 설계를 통해 달성할 수 있습니다.
3. 일반화 이해: 연구자들은 가능한 모든 상황을 예측하거나 시뮬레이션할 수 없기 때문에 모델 동작이 다양한 환경에서 일반화되는(또는 일반화에 실패하는) 방법과 이유에 대한 더 나은 과학이 개발되어야 합니다.
또 다른 중요한 도구는 기계론적 분석으로, 모델의 기능을 이해하기 위해 모델의 가중치와 활성화를 연구합니다.
모델 평가의 미래
모델 평가는 전능하지 않습니다. 왜냐하면 전체 프로세스가 모델 개발 외부의 영향 요인(예: 복잡한 사회적, 정치적, 경제적 힘)에 크게 의존하기 때문입니다. 이 요인들은 모두 일부 위험을 놓칠 수 있습니다.
모델 평가는 다른 위험 평가 도구와 통합되어야 하며 업계, 정부 및 시민 사회 전반에 걸쳐 보안 인식을 더욱 광범위하게 장려해야 합니다.
Google도 최근 'Responsible AI' 블로그에서 개인 관행, 공유된 업계 표준 및 건전한 정책이 인공 지능 개발을 표준화하는 데 중요하다고 지적했습니다.
연구원들은 모델에서 위험 출현 프로세스를 추적하고 관련 결과에 적절하게 대응하는 프로세스가 인공 지능 기능의 최전선에서 운영되는 책임 있는 개발자가 되는 데 중요한 부분이라고 믿습니다.
위 내용은 AI 거대 기업, 백악관에 문서 제출: Google, OpenAI, Oxford 등 12개 주요 기관이 공동으로 '모델 보안 평가 프레임워크' 발표의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!