
Redis 정수 컬렉션을 사용하는 방법은 무엇입니까?

- PHPz앞으로
- 2023-06-03 21:18:541143검색
1. 세트 개요
세트의 경우 기본 구현은 레드-블랙 트리입니다. 삽입, 삭제, 검색에 관계없이 시간 복잡도는 O(log n)입니다. 물론, 해시 테이블을 이용하여 수집을 구현하면 삽입, 삭제, 검색 모두 O(1)에 도달할 수 있다. 그렇다면 컬렉션이 해시 테이블이 아닌 레드-블랙 트리를 사용하는 이유는 무엇일까요? 가장 큰 가능성은 집합 자체의 특성에 있다고 생각합니다. 집합에는 교차, 결합, 차이라는 고유한 작업이 있습니다. 해시 테이블의 경우 세 가지 작업 모두 O(n)입니다. 정렬되지 않은 해시 테이블에 비해 정렬된 레드-블랙 트리를 사용하는 것이 더 적합합니다. 이것이 중요하기 때문입니다.
2. Redis 정수 집합(intset)
오늘 이야기할 정수 집합은 intset이라고도 불리는 Redis의 고유한 데이터 구조입니다. 그 구현은 레드-블랙 트리도 아니고 해시 테이블도 아닙니다. 그것은 단지 단순한 배열에 메모리 인코딩을 더한 것일 뿐입니다. 정수 세트는 저장된 요소가 거의 없고(요소 수의 상한은 server.h의 OBJ_SET_MAX_INTSET_ENTRIES 매크로 정의 값이 512로 정의됨) 모두 정수인 경우에만 사용됩니다. 검색은 O(log n)이고, 삽입과 삭제는 모두 O(n)입니다. 하지만 상대적으로 저장 요소가 적은 경우 O(log n)과 O(n)의 차이는 그리 크지 않습니다. 그러나 Redis의 정수 컬렉션을 사용하면 레드-블랙 트리 및 해시 테이블에 비해 메모리를 크게 줄일 수 있습니다. .
따라서 Redis의 정수 집합 intset의 존재는 주로 메모리 절약을 위한 것입니다.
1. Intset 구조 정의
intset 구조는 intset.h에 정의됩니다.
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
typedef struct intset {
uint32_t encoding; /* a */
uint32_t length; /* b */
int8_t contents[]; /* c */
} intset; a) 인코딩은 인코딩 방법을 지정하며 INTSET_ENC_INT16, INTSET_ENC_INT32 및 INTSET_ENC_INT64의 세 가지 유형이 있습니다. 매크로 정의에서 볼 수 있듯이 이 세 가지 값은 각각 2, 4, 8입니다. 문자 그대로의 의미로 보면 3개가 나타낼 수 있는 범위는 16비트 정수, 32비트 정수, 64비트 정수임을 알 수 있다.
b) 길이는 정수 집합의 요소 수를 저장합니다. T C) 내용은 정수 집합의 유연한 배열입니다. 요소 유형은 반드시 INT8_T 유형일 필요는 없습니다. 내용은 구조의 크기를 차지하지 않으며 정수 컬렉션 데이터의 첫 번째 포인터 역할만 합니다. 정수 컬렉션의 요소는 내용이 오름차순으로 정렬됩니다.
코드의 의미는 정수 V가 32비트 정수로 표현될 수 없다면 INTSET_ENC_INT64로 인코딩해야 한다는 것입니다. INTSET_ENC_INT32 인코딩을 사용해야 합니다. 그렇지 않으면 INTSET_ENC_INT16 인코딩을 사용하세요. 핵심은: 2바이트를 사용하여 표현할 수 있으면 4바이트가 필요하지 않으며, 4바이트를 사용하여 표현할 수 있으면 8바이트가 필요하지 않습니다.
stdint.h에는 다음과 같은 여러 매크로가 정의되어 있습니다.
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
}3. 인코딩 업그레이드
그런 다음 숫자를 삽입합니다. 해당 값은 INT16_MAX보다 1 큰 32768이므로 INTSET_ENC_INT32로 인코딩해야 하며 정수 세트의 모든 숫자 인코딩은 일관되어야 합니다. 따라서 모든 숫자의 인코딩은 INTSET_ENC_INT32 인코딩으로 변환됩니다. 이것이 바로 "업그레이드"입니다. 그림과 같이: 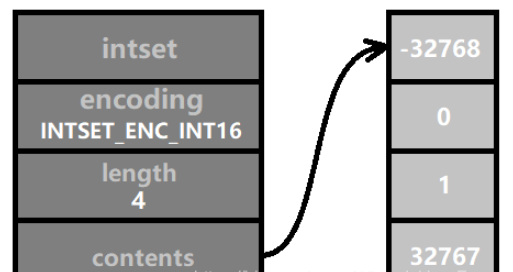
업그레이드 후 내용 배열의 길이는 sizeof(int32_t) * 5 = 4 * 5 = 20바이트(즉, 160바이너리 비트)가 됩니다. 게다가, 각 요소가 차지하는 메모리는 두 배로 늘어났고, 상대적인 위치도 바뀌었기 때문에 모든 요소를 높은 메모리로 마이그레이션해야 했습니다. 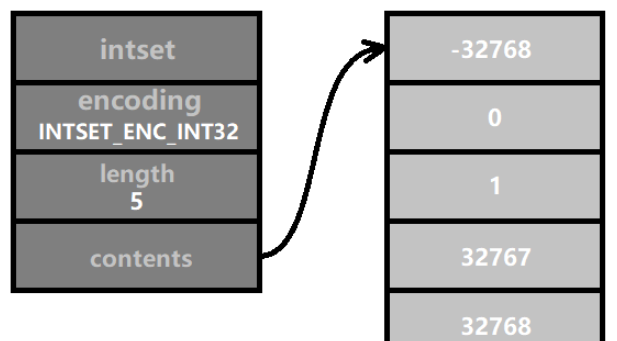 모든 정수 집합을 처음부터 INTSET_ENC_INT64로 인코딩하여 수고를 덜면 참 좋겠습니다. 그 이유는 Redis가 intset을 설계하는 원래 의도는 메모리를 절약하는 것이기 때문입니다. 집합의 요소는 16비트 정수를 초과하지 않을 것이라고 가정합니다. 64비트 정수를 사용하면 3번을 낭비하는 것과 같습니다. 기억.
모든 정수 집합을 처음부터 INTSET_ENC_INT64로 인코딩하여 수고를 덜면 참 좋겠습니다. 그 이유는 Redis가 intset을 설계하는 원래 의도는 메모리를 절약하는 것이기 때문입니다. 집합의 요소는 16비트 정수를 초과하지 않을 것이라고 가정합니다. 64비트 정수를 사용하면 3번을 낭비하는 것과 같습니다. 기억.
三、整数集合常用操作
1、创建集合
创建一个整数集合 intsetNew,实现在 intset.c 中:
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
} 初始创建的整数集合为空集合,用 zmalloc 进行内存分配后,定义编码为 INTSET_ENC_INT16,这样可以使内存尽量小。这里需要注意的是,intset 的存储直接涉及到内存编码,所以需要考虑主机的字节序问题(相关资料请参阅:字节序)。
intrev32ifbe 的意思是 int32 reversal if big endian。即 如果当前主机字节序为大端序,那么将它的内存存储进行翻转操作。简言之,intset 的所有成员存储方式都采用小端序。所以创建一个空的整数集合,内存分布如下:

了解了整数集合的内存编码以后,我们来看看它的 设置 (set)和 获取(get)。
2、元素设置
设置 的含义就是给定整数集合以及一个位置和值,将值设置到这个整数集合的对应位置上。_intsetSet 实现如下:
static void _intsetSet(intset *is, int pos, int64_t value) {
uint32_t encoding = intrev32ifbe(is->encoding); /* a */
if (encoding == INTSET_ENC_INT64) {
((int64_t*)is->contents)[pos] = value; /* b */
memrev64ifbe(((int64_t*)is->contents)+pos); /* c */
} else if (encoding == INTSET_ENC_INT32) {
((int32_t*)is->contents)[pos] = value;
memrev32ifbe(((int32_t*)is->contents)+pos);
} else {
((int16_t*)is->contents)[pos] = value;
memrev16ifbe(((int16_t*)is->contents)+pos);
}
} a) 大端序和小端序只是存储方式,encoding 在存储的时候进行了一次 intrev32ifbe 转换,取出来用的时候需要再进行一次 intrev32ifbe 转换(其实就是序列化和反序列化)。
b) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,然后将 value 的值设置到对应的内存中。
c) memrev64ifbe 的实现参见 字节序 的 memrev64 函数,即将对应内存的值转换成小端序存储。
3、元素获取
获取 的含义就是给定整数集合以及一个位置,返回给定位置的元素的值。_intsetGet 实现如下:
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {
int64_t v64;
int32_t v32;
int16_t v16;
if (enc == INTSET_ENC_INT64) {
memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64)); /* a */
memrev64ifbe(&v64); /* b */
return v64;
} else if (enc == INTSET_ENC_INT32) {
memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32));
memrev32ifbe(&v32);
return v32;
} else {
memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16));
memrev16ifbe(&v16);
return v16;
}
}
static int64_t _intsetGet(intset *is, int pos) {
return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
} a) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,将内存位置上的值拷贝到临时变量中;
b) 由于是直接的内存拷贝,所以取出来的值还是小端序的,那么在大端序的主机上得到的值是不对的,所以需要再做一次 memrev64ifbe 转换将值还原。
4、元素查找
由于整数集合是有序集合,所以查找某个元素是否在整数集合中,Redis 采用的是二分查找。intsetSearch 实现如下:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0; /* a */
return 0;
} else { /* b */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1; /* c */
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) { /* d */
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
} a) 整数集合为空,返回0表示查找失败;
b) value 的值比整数集合中的最大值还大,或者比最小值还小,则返回0表示查找失败;
c) 执行二分查找,将找到的值存在 cur 中;
d) 如果找到则返回1,表示查找成功,并且将 pos 设置为 mid 并返回;如果没找到则返回一个需要插入的位置。
5、内存重分配
由于 contents 的内存是动态分配的,所以每次进行元素插入或者删除的时候,都需要重新分配内存,这个实现放在 intsetResize 中,实现如下:
static intset *intsetResize(intset *is, uint32_t len) {
uint32_t size = len*intrev32ifbe(is->encoding);
is = zrealloc(is,sizeof(intset)+size);
return is;
} encoding 本身表示字节个数,所以乘上集合个数 len 就是 contents 数组需要的总字节数了,调用 zrealloc 进行内存重分配,然后返回重新分配后的地址。
注意:zrealloc 的返回值必须返回出去,因为 intset 在进行内存重分配以后,地址可能就变了。即 is = zrealloc(is, ...) 中,此 is 非彼 is。所以,所有调用 intsetResize 的函数都需要连带的返回新的 intset 指针。
6、编码升级
编码升级一定发生在元素插入,并且插入的元素的绝对值比整数集合中的元素都大的时候,所以我们把升级后的元素插入和编码升级放在一个函数实现,名曰 intsetUpgradeAndAdd,实现如下:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0; /* a */
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1); /* b */
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); /* c */
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value); /* d */
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
} a) curenc 记录升级前的编码,newenc 记录升级后的编码;
b) 将整数集合 is 的编码设置成新的编码后,进行内存重分配;
c) 获取原先内存中的数据,设置到新内存中(注意:由于两段内存空间是重叠的,而且新内存的长度一定大于原先内存,所以需要从后往前进行拷贝);
d) 当插入的值 value 为负数的时候,为了保证集合的有序性,需要插入到 contents 的头部;反之,插入到尾部;当 value 为负数时 prepend 为1,这样就可以保证在内存拷贝的时候将第 0 个位置留空。
如图展示了一个 (-32768, 0, 1, 32767) 的整数集合在插入数字 32768 后的升级的完整过程:
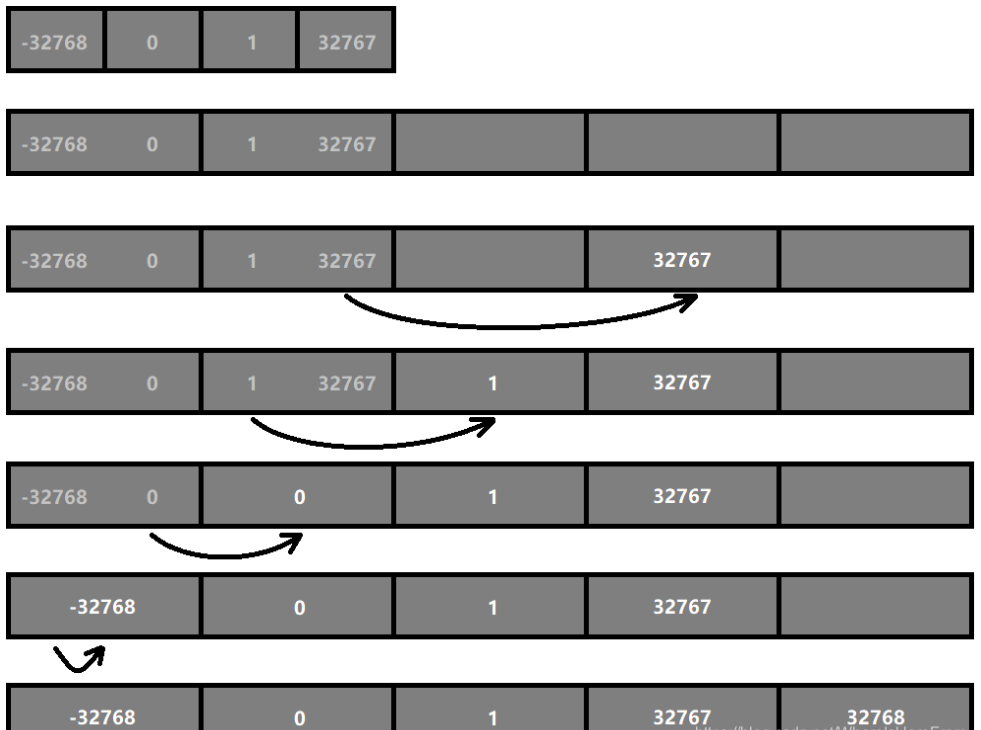
整数集合升级的时间复杂度是 O(n) 的,但是在整数集合的生命期内,升级最多发生两次(从 INTSET_ENC_INT16 到 INTSET_ENC_INT32 以及 从 INTSET_ENC_INT32 到 INTSET_ENC_INT64)。
7、内存迁移
绝大多数情况都是在执行 插入 、删除 、查找 操作。插入 和 删除 会涉及到连续内存的移动。为了实现内存移动,Redis内部实现包括intsetMoveTail函数。
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from; /* a */
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t); /* b */
} else if (encoding == INTSET_ENC_INT32) {
src = (int32_t*)is->contents+from;
dst = (int32_t*)is->contents+to;
bytes *= sizeof(int32_t);
} else {
src = (int16_t*)is->contents+from;
dst = (int16_t*)is->contents+to;
bytes *= sizeof(int16_t);
}
memmove(dst,src,bytes); /* c */
} a) 统计从 from 到结尾,有多少个元素;
b) 根据不同的编码,计算出需要拷贝的内存字节数 bytes,以及拷贝源位置 src,拷贝目标位置 dst;
c) memmove 是 string.h 中的函数:src指向的内存区域拷贝 bytes 个字节到 dst 所指向的内存区域,这个函数是支持内存重叠的;
8、元素插入
最后,讲整数集合的插入和删除,插入调用的是 intsetAdd,在 intset.c 中实现:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
if (valenc > intrev32ifbe(is->encoding)) { /* a */
return intsetUpgradeAndAdd(is,value);
} else {
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0; /* b */
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1); /* c */
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); /* d */
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1); /* e */
return is;
} a) 插入的数值 value 的内存编码大于现有集合的编码,直接调用 intsetUpgradeAndAdd 进行编码升级;
b) 集合元素是不重复的,如果 intsetSearch 能够找到,则将 success 置为0,表示此次插入失败;
c) 如果 intsetSearch 找不到,将 intset 进行内存重分配,即 长度 加 1。
d) pos 为 intsetSearch 过程中找到的 value 将要插入的位置,我们将 pos 以后的内存向后移动1个单位 (这里的1个单位可能是2个字节、4个字节或者8个字节,取决于当前整数集合的内存编码)。
e) 调用 _intsetSet 将 value 的值设置到 pos 的位置上,然后给成员变量 length 加 1。最后返回 intset 指针首地址,因为其间进行了 intsetResize,传入的 intset 指针和返回的有可能不是同一个了。
9、元素删除
删除元素调用的是 intsetRemove ,实现如下:
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) { /* a */
uint32_t len = intrev32ifbe(is->length);
if (success) *success = 1;
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos); /* b */
is = intsetResize(is,len-1); /* c */
is->length = intrev32ifbe(len-1);
}
return is;
} a) 当整数集合中存在 value 这个元素时才能执行删除操作;
b) 如果能通过 intsetSearch 找到元素,那么它的位置就在 pos 上,这是通过 intsetMoveTail 将内存往前挪;
c) intsetResize 重新分配内存,并且将集合长度减1;
위 내용은 Redis 정수 컬렉션을 사용하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!