
집 >데이터 베이스 >MySQL 튜토리얼 >Mysql 잠금의 내부 구현 메커니즘은 무엇입니까?
Mysql 잠금의 내부 구현 메커니즘은 무엇입니까?

- 王林앞으로
- 2023-06-03 18:04:481280검색
개요
최신 관계형 데이터베이스는 점점 유사해지고 있지만 구현 이면에는 완전히 다른 메커니즘이 있을 수 있습니다. 실제 사용 측면에서는 SQL 구문 사양이 존재하기 때문에 여러 관계형 데이터베이스에 익숙해지는 것이 어렵지 않지만 데이터베이스 수만큼 잠금 구현 방법이 있을 수 있습니다.
Microsoft SQL Server는 2005년 이전에만 페이지 잠금을 제공했습니다. 낙관적 동시성과 비관적 동시성을 지원하기 시작한 것은 2005년이 되어서야 SQL Server 설계에서 잠금이 허용됩니다. 잠금 수가 많을수록 오버헤드도 커집니다. 잠금 수의 급격한 증가로 인한 성능 저하를 방지하기 위해 잠금 업그레이드라는 메커니즘을 지원합니다. 행 잠금이 페이지 잠금으로 업그레이드되면 동시성 성능이 원래 수준으로 돌아갑니다.
실제로 동일한 데이터베이스 내에서 서로 다른 실행 엔진의 잠금 기능 해석에 대해 여전히 많은 논란이 있습니다. MyISAM은 동시 읽기에는 적합한 테이블 수준 잠금만 지원하지만 동시 수정에는 특정 제한 사항이 있습니다. Innodb는 비잠금 일관성 읽기 및 행 잠금 지원을 제공한다는 점에서 Oracle과 매우 유사합니다. Sql Server와의 명백한 차이점은 총 잠금 수가 증가함에 따라 Innodb가 약간의 비용만 지불하면 된다는 것입니다.
행 잠금 구조
Innodb는 행 잠금을 지원하며 잠금 설명에 특별히 큰 오버헤드가 없습니다. 따라서 많은 수의 잠금으로 인해 성능 저하가 발생한 경우를 대비해 잠금 업그레이드 메커니즘이 필요하지 않습니다.
lock0priv.h 파일에서 발췌, Innodb의 행 잠금 정의는 다음과 같습니다.
/** Record lock for a page */
struct lock_rec_t {
/* space id */
ulint space;
/* page number */
ulint page_no;
/**
* number of bits in the lock bitmap;
* NOTE: the lock bitmap is placed immediately after the lock struct
*/
ulint n_bits;
};동시성 제어는 행 수준에서 세분화할 수 있지만 잠금 관리는 페이지 단위로 구성됩니다. Innodb 설계에서는 공간 ID와 페이지 번호라는 두 가지 필수 조건을 통해 유일한 데이터 페이지를 결정할 수 있습니다. n_bits는 페이지의 행 잠금 정보를 설명하는 데 필요한 비트 수를 나타냅니다.
동일한 데이터 페이지의 각 레코드에는 고유한 연속 증가 시퀀스 번호인 heap_no가 할당됩니다. 특정 레코드 행이 잠겨 있는지 알고 싶다면 비트맵의 heap_no 위치에 있는 숫자가 잠겨 있는지 확인하기만 하면 됩니다. 하나. 잠금 비트맵은 데이터 페이지의 레코드 수를 기준으로 메모리 공간을 할당하므로 명시적으로 정의되지 않으며, 페이지 레코드가 계속 증가할 수 있으므로 LOCK_PAGE_BITMAP_MARGIN 크기의 공간을 예약해 둔다.
/** * Safety margin when creating a new record lock: this many extra records * can be inserted to the page without need to create a lock with * a bigger bitmap */ #define LOCK_PAGE_BITMAP_MARGIN 64
공간 ID = 20, 페이지 번호 = 100인 데이터 페이지에 현재 160개의 레코드가 있고 heap_no 2, 3, 4인 레코드가 잠겨 있다고 가정하면 해당 lock_rec_t 구조와 데이터 페이지는 다음과 같이 설명되어야 합니다. this:
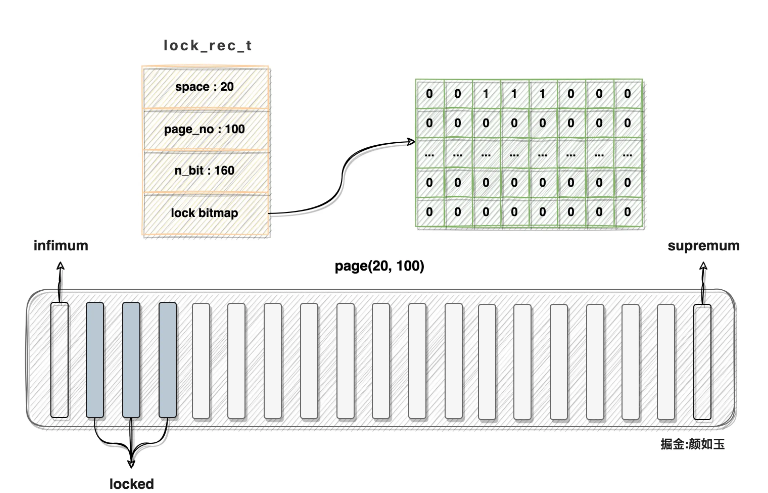
Note:
메모리의 잠금 비트맵은 선형적으로 분포되어야 합니다. 그림에 표시된 2차원 구조는 설명의 편의를 위한 것입니다.
bitmap과 lock_rec_t 구조는 연속적인 메모리입니다. , 그리고 사진 속 참조 관계도 그림이 필요합니다
해당 페이지에 해당하는 비트맵의 두 번째, 세 번째, 네 번째 위치가 모두 1로 설정되어 있는 것을 볼 수 있습니다. 데이터 페이지 행을 기술하는데 소모되는 메모리 자물쇠는 인식의 관점에서 볼 때 구체적으로 얼마나 많은 부분을 차지합니까? 계산할 수 있습니다:
160 / 8 + 8 + 1 = 29바이트.
160개 레코드는 160bit
+8에 해당합니다. 64bit는 예약해야 하기 때문입니다.
+1은 소스 코드에 1바이트가 예약되어 있기 때문입니다
. 여기에 +1이 추가되었습니다. 이렇게 하면 정수 나누기로 인한 오류를 피할 수 있습니다. 161개의 레코드가 있는 경우 +1이 아니라면 계산된 20바이트는 모든 레코드의 잠금 정보를 설명하기에 충분하지 않습니다(예약된 비트를 사용하지 않음).
lock0priv.h 파일에서 발췌:
/* lock_rec_create函数代码片段 */
n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
n_bytes = 1 + n_bits / 8;
/* 注意这里是分配的连续内存 */
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes)
);
/**
* Gets the number of records in the heap.
* @return number of user records
*/
UNIV_INLINE ulint page_dir_get_n_heap(const page_t* page)
{
return(page_header_get_field(page, PAGE_N_HEAP) & 0x7fff);
}테이블 잠금 구조
Innodb는 테이블 잠금도 지원합니다. 테이블 잠금은 의도 잠금과 자동 증가 잠금의 두 가지 범주로 나눌 수 있습니다.
lock0priv.h 파일에서 발췌
struct lock_table_t {
/* database table in dictionary cache */
dict_table_t* table;
/* list of locks on the same table */
UT_LIST_NODE_T(lock_t) locks;
};ut0lst.h 파일에서 발췌
struct ut_list_node {
/* pointer to the previous node, NULL if start of list */
TYPE* prev;
/* pointer to next node, NULL if end of list */
TYPE* next;
};
#define UT_LIST_NODE_T(TYPE) ut_list_node<TYPE>트랜잭션 내 잠금 설명
위 lock_rec_t 및 lock_table_t 구조는 트랜잭션에서 잠금이 생성되는 별도의 정의일 뿐이므로 각 트랜잭션에는 해당 행 잠금 및 테이블 잠금 잠금 구조는 다음과 같이 정의됩니다.
lock0priv.h 파일에서 추출
/** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};lock_t는 각 트랜잭션의 각 페이지(또는 테이블)를 기반으로 정의되지만 트랜잭션에는 여러 페이지가 포함되는 경우가 많습니다. 따라서 연결된 목록 trx_locks가 필요합니다. 트랜잭션과 관련된 모든 잠금 정보를 연결합니다. 실제 시나리오에서는 트랜잭션을 기반으로 모든 잠금 정보를 쿼리하는 것 외에도 시스템이 행 레코드가 잠겨 있는지 여부를 빠르고 효율적으로 감지할 수 있어야 합니다. 따라서 행 레코드에 대한 잠금 정보 쿼리를 지원하는 전역 변수가 있어야 합니다. Innodb는 다음과 같이 정의된 해시 테이블을 선택했습니다.
lock0lock.h 파일에서 추출됨
/** The lock system struct */
struct lock_sys_t {
/* Mutex protecting the locks */
ib_mutex_t mutex;
/* 就是这里: hash table of the record locks */
hash_table_t* rec_hash;
/* Mutex protecting the next two fields */
ib_mutex_t wait_mutex;
/**
* Array of user threads suspended while waiting forlocks within InnoDB,
* protected by the lock_sys->wait_mutex
*/
srv_slot_t* waiting_threads;
/*
* highest slot ever used in the waiting_threads array,
* protected by lock_sys->wait_mutex
*/
srv_slot_t* last_slot;
/**
* TRUE if rollback of all recovered transactions is complete.
* Protected by lock_sys->mutex
*/
ibool rollback_complete;
/* Max wait time */
ulint n_lock_max_wait_time;
/**
* Set to the event that is created in the lock wait monitor thread.
* A value of 0 means the thread is not active
*/
os_event_t timeout_event;
/* True if the timeout thread is running */
bool timeout_thread_active;
};lock_sys_create 함수는 데이터베이스가 시작될 때 lock_sys_t 구조를 초기화하는 역할을 합니다. srv_lock_table_size 변수는 rec_hash의 해시 슬롯 수 크기를 결정합니다. Rec_hash 해시 테이블의 키 값은 해당 페이지의 공간 ID와 페이지 번호를 이용하여 계산됩니다.
lock0lock.ic, ut0rnd.ic 파일에서 발췌
/**
* Calculates the fold value of a page file address: used in inserting or
* searching for a lock in the hash table.
*
* @return folded value
*/
UNIV_INLINE ulint lock_rec_fold(ulint space, ulint page_no)
{
return(ut_fold_ulint_pair(space, page_no));
}
/**
* Folds a pair of ulints.
*
* @return folded value
*/
UNIV_INLINE ulint ut_fold_ulint_pair(ulint n1, ulint n2)
{
return (
(
(((n1 ^ n2 ^ UT_HASH_RANDOM_MASK2) << 8) + n1)
^ UT_HASH_RANDOM_MASK
)
+ n2
);
}이는 특정 행이 잠겨 있는지 직접 알 수 있는 방법을 제공할 방법이 없음을 의미합니다. 대신 해당 공간이 위치한 페이지를 통해 먼저 공간 ID와 페이지 번호를 얻고, lock_rec_fold 함수를 통해 키 값을 얻은 후, 해시 쿼리를 통해 lock_rec_t를 얻은 후, heap_no에 따라 비트맵을 스캔하여 최종적으로 결정해야 합니다. 잠금 정보. lock_rec_get_first 함수는 위의 논리를 구현합니다:
这里返回的其实是lock_t对象,摘自lock0lock.cc文件
/**
* Gets the first explicit lock request on a record.
*
* @param block : block containing the record
* @param heap_no : heap number of the record
*
* @return first lock, NULL if none exists
*/
UNIV_INLINE lock_t* lock_rec_get_first(const buf_block_t* block, ulint heap_no)
{
lock_t* lock;
ut_ad(lock_mutex_own());
for (lock = lock_rec_get_first_on_page(block); lock;
lock = lock_rec_get_next_on_page(lock)
) {
if (lock_rec_get_nth_bit(lock, heap_no)) {
break;
}
}
return(lock);
}以页面为粒度进行锁维护并非最直接有效的方式,它明显是时间换空间,不过这种设计使得锁开销很小。某一事务对任一行上锁的开销都是一样的,锁数量的上升也不会带来额外的内存消耗。
对应每个事务的内存对象trx_t中,包含了该事务的锁信息链表和等待的锁信息。因此存在如下两种途径对锁进行查询:
根据事务: 通过trx_t对象的trx_locks链表,再通过lock_t对象中的trx_locks遍历可得某事务持有、等待的所有锁信息。
根据记录: 根据记录所在的页,通过space id、page number在lock_sys_t结构中定位到lock_t对象,扫描bitmap找到heap_no对应的bit位。
上述各种数据结构,对其整理关系如下图所示:
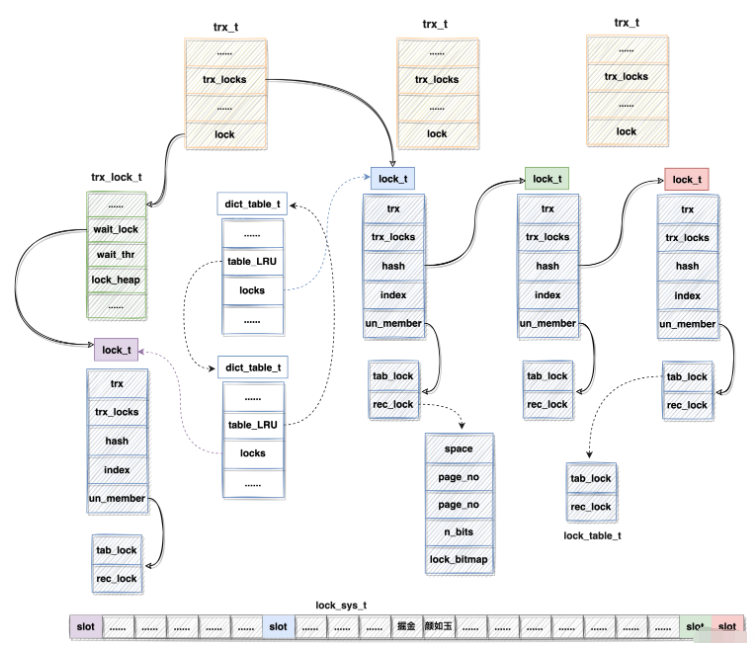
注:
lock_sys_t中的slot颜色与lock_t颜色相同则表明lock_sys_t slot持有lock_t 指针信息,实在是没法连线,不然图很混乱
위 내용은 Mysql 잠금의 내부 구현 메커니즘은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!