
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 데이터베이스의 모니터링 방법은 무엇입니까?
MySQL 데이터베이스의 모니터링 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-03 13:22:131510검색
현재 데이터베이스에는 다양한 모니터링 방법이 있으며 내장 데이터베이스, 상용 데이터베이스, 오픈 소스로 구분됩니다. 각각 고유한 특성을 가지고 있습니다.
mysql 데이터베이스의 경우 커뮤니티 활동이 높기 때문에 방법은 더욱 다양합니다. 어떤 모니터링 방법을 사용하더라도 핵심은 모니터링 데이터입니다. 종합적인 모니터링 데이터를 얻은 후에는 유연한 디스플레이 부분이 됩니다.
1. 연결 수(연결)
1.1. 최대 연결 수
show status like 'Max_used_connections';
1.2. 현재 열려 있는 연결 수
show status like 'Threads_connected';
2. 버퍼에서 읽지 못한 횟수 pool
show status like 'Innodb_buffer_pool_reads';
2.2. 버퍼 풀의 읽기 수
show status like 'Innodb_buffer_pool_read_requests';
2.3. 버퍼 풀의 총 페이지 수
show status like 'Innodb_buffer_pool_pages_total';
2.4. 캐시 적중률 계산
show status like 'Innodb_buffer_pool_pages_free';.
2.6. 캐시 풀 사용률은
(1-Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests)*100%
3. 잠금(lock)
참고: 잠금 대기 통계는 얻을 때마다 이전 데이터에서 빼서 현재 통계를 얻을 수 있습니다. data
3.1. 잠금 대기 횟수
((Innodb_buffer_pool_pages_total-Innodb_buffer_pool_pages_free)/Innodb_buffer_pool_pages_total)*100%
3.2. 각 잠금에 대한 평균 대기 시간
show status like 'Innodb_row_lock_waits';
3.3. 데이터가 있으면 잠금 테이블이 있음을 의미합니다. 비어 있으면 테이블 잠금이 없음을 의미합니다.
show status like 'Innodb_row_lock_time_avg';
4. Slow SQL
참고: mysqldumpslow 명령이 실행되지 않는 경우 느린 로그는 포맷 처리를 위해 로컬에 동기화됩니다.
4.1.mysql 느린 sql 스위치가 켜져 있는지 확인하세요
show open TABLES where in_use>0
4.2. mysql 느린 sql 임계값을 확인하세요
show variables like 'slow_query_log'; --ON 为开启状态,OFF 为关闭状态 set global slow_query_log=1 -- 可进行开启
4.4.느린 SQL 로그를 포맷하세요. 이 명령문은 jdbc 실행을 통과하지 않으며 명령줄 실행에 속합니다.
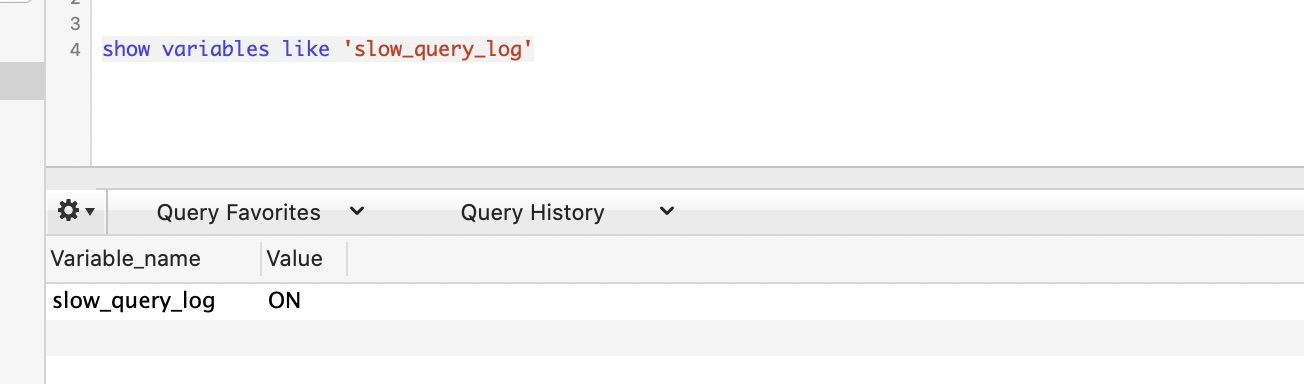
의미: 가장 긴 10개의 SQL 문의 실행 정보를 표시합니다. 10은 TOP 번호로 수정될 수 있습니다. 표시되는 정보는 실행 횟수, 평균 실행 시간, SQL 문show variables like 'long_query_time'; set global long_query_time=0.1 -- 根据页面传递阈值参数,修改阈值5, 문5.1, 삽입 수량
show variables like 'slow_query_log_file';5.2, 삭제 수량
mysqldumpslow -s at -t 10 /export/data/mysql/log/slow.log
5.3, 업데이트 수량
show status like 'Com_insert';
5.4, 수량 선택
show status like 'Com_delete';입니다.
6. 처리량(데이터베이스 처리량)
6.1, 전송 처리량
show status like 'Com_update';
6.2, 수신 처리량
show status like 'Com_select';
6.3, 총 처리량
show status like 'Bytes_sent';
7, 데이터베이스 매개변수(serverconfig)
7.1, 변수 표시
8. 느린 SQL 문제 해결 단계
느린 SQL은 MySQL의 느린 쿼리, 특히 실행 시간이 long_query_time 값을 초과하는 SQL을 나타냅니다. MySQL에는 바이너리 로그 binlog, 릴레이 로그 Relaylog, Redo Rollback 로그 redolog, Undolog 등이 있다는 말을 자주 듣습니다. 느린 쿼리의 경우, 응답 시간이 MySQL의 임계값을 초과하는 명령문을 기록하는 데 사용되는 느린 쿼리 로그인 Slowlog도 있습니다. 느린 SQL은 실제 프로덕션 비즈니스에 치명적인 영향을 미치기 때문에 테스터가 성능 테스트 과정에서 데이터베이스 SQL 문 실행을 모니터링하고 개발을 위한 정확한 성능 최적화 제안을 제공하는 것이 특히 중요합니다. 그런 다음 MySQL 데이터베이스에서 제공하는 느린 쿼리 로그를 사용하여 SQL 문 실행을 모니터링하고 사용량이 많은 SQL 문을 찾는 방법은 다음과 같습니다. 느린 쿼리 로그를 사용하는 단계에 대한 자세한 설명입니다.
8.1. Slow_query_log 스위치를 켜세요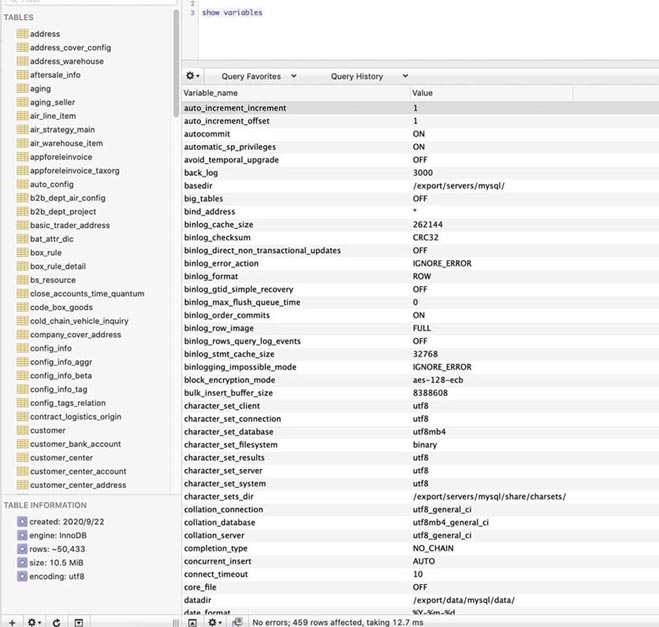
8.2 느린 SQL 도메인 값을 설정하세요. long_query_time
이 long_query_time은 "느린 쿼리"로 간주되는 초 단위를 정의하는 데 사용됩니다. sql 명령어 set long_query_time=1을 실행하여 long_query_time 값을 확인합니다. 1. 즉, 실행하는 데 1초 이상 걸리는 쿼리는 다음과 같이 느린 쿼리로 간주됩니다.
 8.3.
8.3.
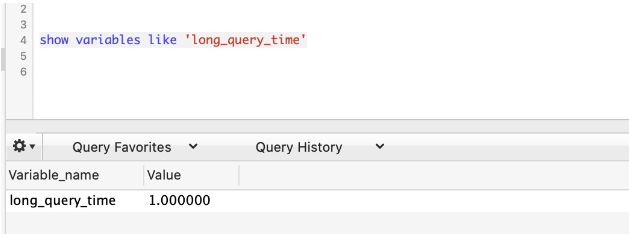 mysqldumpslow는 mysql 설치와 함께 제공되는 느린 쿼리 분석 도구입니다. /mysqldumpslow —help를 통해 사용 매개변수 설명을 확인할 수 있습니다.
mysqldumpslow는 mysql 설치와 함께 제공되는 느린 쿼리 분석 도구입니다. /mysqldumpslow —help를 통해 사용 매개변수 설명을 확인할 수 있습니다.
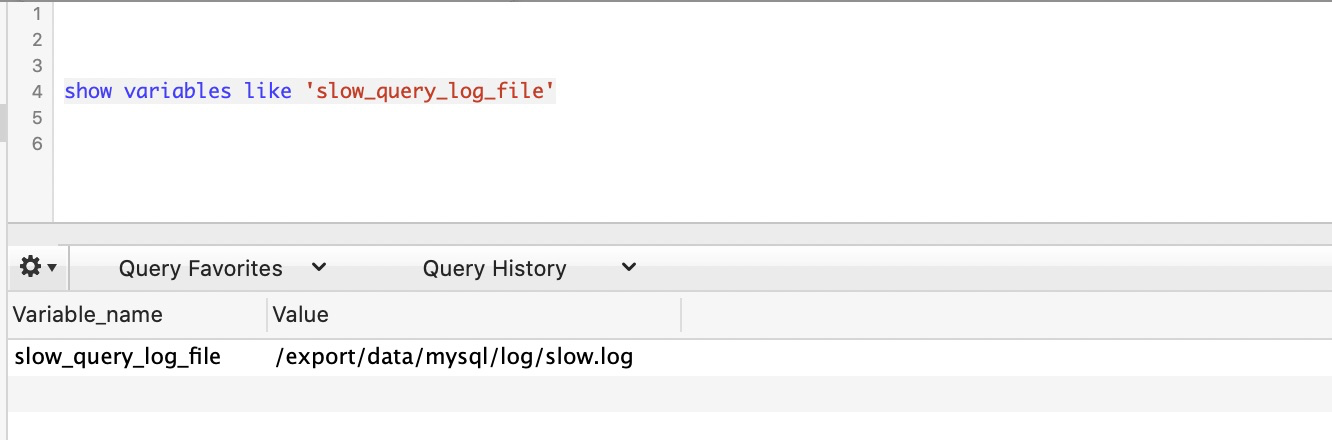 8.4.1.가장 많이 사용되는 느린 쿼리 10개를 추출하는 일반적인 사용법
8.4.1.가장 많이 사용되는 느린 쿼리 10개를 추출하는 일반적인 사용법
show status like 'Bytes_received';
쿼리 추출 시간이 가장 느린 가장 느린 쿼리 3개
Bytes_sent+Bytes_received
참고: mysqldumpslow를 사용한 분석 결과는 구체적이고 완전한 쿼리를 표시하지 않습니다.
If: SELECT FROM sms_send WHERE service_id=10 GROUP BY content LIMIT 0 , 1000;mysqldumpslow 명령 실행은 다음을 표시합니다: 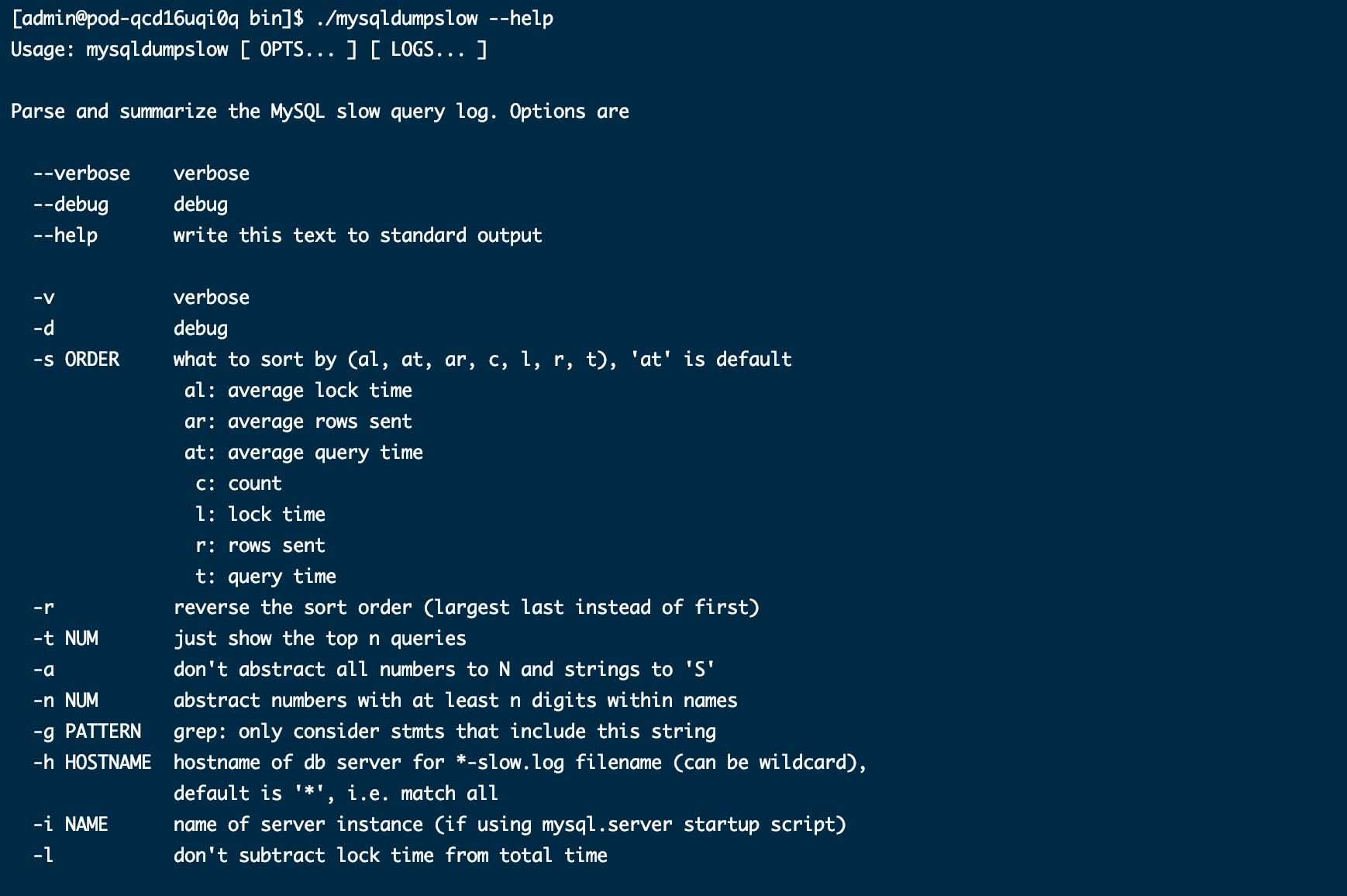 Count: 2 Time=1.5s (3s) Lock=0.00s ( 0s) Rows=1000.0 (2000), vgos_dba[vgos_dba]@[10.130.229.196]SELECT FROM sms_send WHERE service_id =N GROUP BY content LIMIT N, N
Count: 2 Time=1.5s (3s) Lock=0.00s ( 0s) Rows=1000.0 (2000), vgos_dba[vgos_dba]@[10.130.229.196]SELECT FROM sms_send WHERE service_id =N GROUP BY content LIMIT N, N
8.4.2 mysqldumpslow
분석 결과에 대한 자세한 설명.Count: 이 유형의 문의 실행 횟수를 나타냅니다. 위 그림은 select 문이 2번 실행되었음을 나타냅니다.
- Lock: 잠금 시간 0초.
Rows:单次返回的结果数是 1000 条记录,2 次总共返回 2000 条记录。
通过这个工具就可以查询出来哪些 sql 语句是慢 SQL,从而反馈研发进行优化,比如加索引,该应用的实现方式等。
8.5、常见慢 SQL 排查
8.5.1、不使用子查询
SELECT FROM t1 WHERE id (SELECT id FROM t2 WHERE name='hechunyang');
子查询在 MySQL5.5 版本里,内部执行计划器是这样执行的:先查外表再匹配内表,而不是先查内表 t2,当外表的数据很大时,查询速度会非常慢。
在 MariaDB10/MySQL5.6 版本里,采用 join 关联方式对其进行了优化,这条 SQL 会自动转换为
SELECT t1. FROM t1 JOIN t2 ON t1.id = t2.id;
但请注意的是:优化只针对 SELECT 有效,对 UPDATE/DELETE 子 查询无效, 生产环境尽量应避免使用子查询。
8.5.2、避免函数索引
SELECT FROM t WHERE YEAR(d) >= 2016;
由于 MySQL 不像 Oracle 那样⽀持函数索引,即使 d 字段有索引,也会直接全表扫描。
应改为 :
SELECT FROM t WHERE d >= ‘2016-01-01';
8.5.3、用 IN 来替换 OR 低效查询
慢
SELECT FROM t WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30;
高效查询
SELECT FROM t WHERE LOC_IN IN (10,20,30);
8.5.4、LIKE 双百分号无法使用到索引
SELECT FROM t WHERE name LIKE '%de%';
应改为 :
SELECT FROM t WHERE name LIKE 'de%';
8.5.5、分组统计可以禁止排序
SELECT goods_id,count() FROM t GROUP BY goods_id;
默认情况下,MySQL 对所有 GROUP BY col1,col2… 的字段进⾏排序。如果查询包括 GROUP BY,想要避免排序结果的消耗,则可以指定 ORDER BY NULL 禁止排序。
应改为 :
SELECT goods_id,count () FROM t GROUP BY goods_id ORDER BY NULL;
8.5.6、禁止不必要的 ORDER BY 排序
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id WHERE 1 = 1 ORDER BY u.create_time DESC;
应改为 :
SELECT count (1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id;
위 내용은 MySQL 데이터베이스의 모니터링 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!