



1. 서문
Redis: 원격 사전 서비스, 즉 Redis의 하위 계층은 C 언어로 작성되었습니다. 오픈 소스, 메모리 기반 NoSql 데이터베이스입니다.
Redis의 성능이 훨씬 뛰어납니다. 다른 데이터베이스와 클러스터를 지원하며, 분산 및 마스터-슬레이브 동기화의 장점을 가지고 있어 데이터 캐싱 및 고속 읽기/쓰기 등의 시나리오에서 자주 사용됩니다
2. 준비
설치를 맡아드립니다. 클라우드 서버 Centos 7.8의 Redis-Server를 예로
먼저 클라우드 서버 Redis 데이터베이스에 설치
# 下载epel仓库 yum install epel-release # 安装redis yum install redis
그런 다음 vim 명령을 통해 Redis 구성 파일을 수정하고 원격 연결을 열고 연결 비밀번호를 설정하세요
구성 파일 디렉터리: /etc/redis.conf
-
bind를 0.0.0.0으로 변경하여 외부 네트워크 접근을 허용합니다
requirepass 접근 비밀번호를 설정하세요
# vim /etc/redis.conf # 1、bing从127.0.0.1修改为:0.0.0.0,开放远程连接 bind 0.0.0.0 # 2、设置密码 requirepass 123456
클라우드 서버 데이터의 보안을 보장하려면 Redis가 원격 액세스를 열 때 비밀번호를 강화해야 합니다
그런 다음 Redis 서비스를 시작하고 방화벽과 포트를 열고 클라우드 서버 보안 그룹을 구성합니다
기본적으로 사용되는 포트 번호는 Redis 서비스는 6379입니다
또한 Redis 데이터베이스가 정상적으로 연결될 수 있도록 클라우드 서버 보안 그룹에서 구성해야 합니다
# 启动Redis服务,默认redis端口号是6379 systemctl start redis # 打开防火墙 systemctl start firewalld.service # 开放6379端口 firewall-cmd --zone=public --add-port=6379/tcp --permanent # 配置立即生效 firewall-cmd --reload
위 작업을 완료한 후 Redis-CLI 또는 Redis 클라이언트 도구를 사용할 수 있습니다 to connect
마지막으로 Python을 사용하여 Redis를 작동하려면 pip를 사용하여 종속성을 설치해야 합니다
# 安装依赖,便于操作redis pip3 install redis
3. 실용적인 전투
Redis에서 데이터를 작동하기 전에 호스트, 포트 번호, 비밀번호 인스턴스화를 사용해야 합니다. Redis 연결 개체
from redis import Redis
class RedisF(object):
def __init__(self):
# 实例化Redis对象
# decode_responses=True,如果不加则写入的为字节类型
# host:远程连接地址
# port:Redis端口号
# password:Redis授权密码
self.redis_obj = Redis(host='139.199.**.**',port=6379,password='123456',decode_responses=True,charset='UTF-8', encoding='UTF-8')다음으로 문자열, 목록, 집합 컬렉션, zset 컬렉션, 해시 테이블 및 트랜잭션의 작업을 예로 들어 Python에서 이러한 데이터를 작업하는 방법에 대해 설명합니다
1 문자열 작업
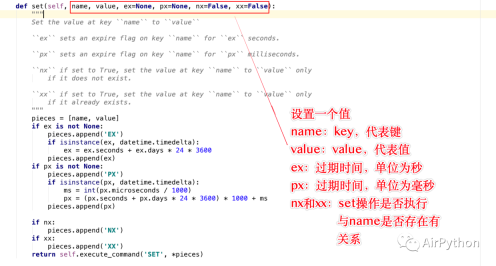
. 문자열을 연산하는 방법에는 두 가지가 있습니다. 연산 방법은 set()과 mset()
그 중 set()은 한 번에 하나의 값만 저장할 수 있습니다. 매개변수의 의미는 다음과 같습니다
이름. : key, 키를 나타냅니다
value: value, 저장할 값
ex: 만료 시간(초), 설정하지 않으면 절대 만료되지 않습니다. 그렇지 않으면 만료될 때 삭제됩니다.
- px: 만료 시간(밀리초) 단위
- nx/xx: 설정 작업의 실행 여부는 name 키의 존재 여부와 관련됩니다.
# set():单字符串操作 # 添加一个值,并设置超时时间为120s self.redis_obj.set('name', 'airpython', ex=120) # get():获取这个值 print(self.redis_obj.get('name')) # delete():删除一个值或多个值 self.redis_obj.delete('name') print(self.redis_obj.get('name'))다중 값 데이터 설정의 경우 mset() 메서드를 호출하고 키-값 쌍을 사용하여 사전을 삽입할 데이터에 대한 매개변수마찬가지로 Redis는 여러 값을 한 번에 얻을 수 있는 mget() 메서드를 제공합니다. 키 값
# mset():设置多个值
self.redis_obj.mset({"foo": "foo1", "zoo": "zoo1"})
# mget():获取多个值
result = self.redis_obj.mget("foo", "zoo")
print(result)2. 목록 작업Redis는 목록 작업을 위한 다양한 메서드를 제공합니다. , 더 일반적인 것은 다음과 같습니다:
- lpush/rpush: 목록의 헤드 또는 테일에 하나 이상의 값을 삽입합니다. 여기서 lpush는 데이터의 테일 삽입을 나타냅니다. lset: 인덱스를 통해 목록의 해당 위치에 값을 삽입
- linsert: 목록 요소 앞이나 뒤에 데이터 삽입
- lindex : 인덱스를 통해 목록의 요소를 얻습니다. 여기서 0은 첫 번째 요소를 나타냅니다. ; -1은 마지막 요소를 나타냅니다
- lrange: 시작 위치와 끝 위치를 지정하여 목록에서 지정된 영역의 값을 가져옵니다.
- llen: 해당 목록의 길이를 가져옵니다. 키가 존재하지 않으면 0
- lpop: 목록의 첫 번째 요소를 제거하고 반환
- rpop: 목록의 첫 번째 요소를 제거하고 반환 마지막 요소
- 예제 코드는 다음과 같습니다. :
def manage_list(self): """ 操作列表 :return: """ # 1、新增一个列表,并左边插入一个数据 # 注意:可以一次加入多个元素,也可以一个个元素的加入 self.redis_obj.lpush('company', '阿里', '腾讯', '百度') # 2、移除第一个元素 self.redis_obj.lpop("company") # 3、右边插入数据 self.redis_obj.rpush('company', '字节跳动', '小米') # 4、移除最后一个元素 self.redis_obj.rpop("company") # 5、获取列表的长度 self.redis_obj.llen("company") # 6、通过索引,获取列表中的某一个元素(第二个元素) print('列表中第二个元素是:', self.redis_obj.lindex("company", 1)) # 7、根据范围,查看列表中所有的值 print(self.redis_obj.lrange('company', 0, -1))3. 작업 세트 컬렉션
- smembers: 집합의 모든 요소를 반환합니다.
- srem: 집합에서 하나 이상의 요소를 제거하고 요소가 존재하지 않으면 무시합니다.
- sinter: 두 집합의 교집합을 반환합니다. 결과는 다음과 같습니다. still one Set
- sunion: 두 집합의 합집합을 반환합니다.
- sdiff: 첫 번째 집합 매개변수를 기준으로 사용하여 두 집합의 차이 집합을 반환합니다.
- sunionstore: 두 집합의 합집합을 계산합니다. 새 컬렉션에 저장
- sismember: 컬렉션에 요소가 존재하는지 확인
- spop: 컬렉션에서 요소를 무작위로 삭제하고 반환
- 구체적인 예제 코드는 다음과 같습니다.
def manage_set(self):
"""
操作set集合
:return:
"""
self.redis_obj.delete("fruit")
# 1、sadd:新增元素到集合中
# 添加一个元素:香蕉
self.redis_obj.sadd('fruit', '香蕉')
# 再添加两个元素
self.redis_obj.sadd('fruit', '苹果', '桔子')
# 2、集合元素的数量
print('集合元素数量:', self.redis_obj.scard('fruit'))
# 3、移除一个元素
self.redis_obj.srem("fruit", "桔子")
# 再定义一个集合
self.redis_obj.sadd("fruit_other", "香蕉", "葡萄", "柚子")
# 4、获取两个集合的交集
result = self.redis_obj.sinter("fruit", "fruit_other")
print(type(result))
print('交集为:', result)
# 5、获取两个集合的并集
result = self.redis_obj.sunion("fruit", "fruit_other")
print(type(result))
print('并集为:', result)
# 6、差集,以第一个集合为标准
result = self.redis_obj.sdiff("fruit", "fruit_other")
print(type(result))
print('差集为:', result)
# 7、合并保存到新的集合中
self.redis_obj.sunionstore("fruit_new", "fruit", "fruit_other")
print('新的集合为:', self.redis_obj.smembers('fruit_new'))
# 8、判断元素是否存在集合中
result = self.redis_obj.sismember("fruit", "苹果")
print('苹果是否存在于集合中', result)
# 9、随机从集合中删除一个元素,然后返回
result = self.redis_obj.spop("fruit")
print('删除的元素是:', result)
# 3、集合中所有元素
result = self.redis_obj.smembers('fruit')
print("最后fruit集合包含的元素是:", result)其中,比较常用的方法如下:
zadd:往集合中新增元素,如果集合不存在,则新建一个集合,然后再插入数据
zrange:通过起始点和结束点,返回集合中的元素值(不包含分数);如果设置withscores=True,则返回结果会带上分数
zscore:获取某一个元素对应的分数
zcard:获取集合中元素个数
zrank:获取元素在集合中的索引
zrem:删除集合中的元素
zcount:通过最小值和最大值,判断分数在这个范围内的元素个数
实践代码如下:
def manage_zset(self):
"""
操作zset集合
:return:
"""
self.redis_obj.delete("fruit")
# 往集合中新增元素:zadd()
# 三个元素分别是:"banana", 1/"apple", 2/"pear", 3
self.redis_obj.zadd("fruit", "banana", 1, "apple", 2, "pear", 3)
# 查看集合中所有元素(不带分数)
result = self.redis_obj.zrange("fruit", 0, -1)
# ['banana', 'apple', 'pear']
print('集合中的元素(不带分数)有:', result)
# 查看集合中所有元素(带分数)
result = self.redis_obj.zrange("fruit", 0, -1, withscores=True)
# [('banana', 1.0), ('apple', 2.0), ('pear', 3.0)]
print('集合中的元素(带分数)有:', result)
# 获取集合中某一个元素的分数
result = self.redis_obj.zscore("fruit", "apple")
print("apple对应的分数为:", result)
# 通过最小值和最大值,判断分数在这个范围内的元素个数
result = self.redis_obj.zcount("fruit", 1, 2)
print("集合中分数大于1,小于2的元素个数有:", result)
# 获取集合中元素个数
count = self.redis_obj.zcard("fruit")
print('集合元素格式:', count)
# 获取元素的值获取索引号
index = self.redis_obj.zrank("fruit", "apple")
print('apple元素的索引为:', index)
# 删除集合中的元素:zrem
self.redis_obj.zrem("fruit", "apple")
print('删除apple元素后,剩余元素为:', self.redis_obj.zrange("fruit", 0, -1))4、操作哈希
哈希表中包含很多键值对,并且每一个键都是唯一的
Redis 操作哈希表,下面这些方法比较常用:
hset:往哈希表中添加一个键值对值
hmset:往哈希表中添加多个键值对值
hget:获取哈希表中单个键的值
hmget:获取哈希表中多个键的值列表
hgetall:获取哈希表中种所有的键值对
hkeys:获取哈希表中所有的键列表
hvals:获取哈表表中所有的值列表
hexists:判断哈希表中,某个键是否存在
hdel:删除哈希表中某一个键值对
hlen:返回哈希表中键值对个数
对应的操作代码如下:
def manage_hash(self):
"""
操作哈希表
哈希:一个键对应一个值,并且键不容许重复
:return:
"""
self.redis_obj.delete("website")
# 1、新建一个key为website的哈希表
# 往里面加入数据:baidu(field),www.baidu.com(value)
self.redis_obj.hset('website', 'baidu', 'www.alibababaidu.com')
self.redis_obj.hset('website', 'google', 'www.google.com')
# 2、往哈希表中添加多个键值对
self.redis_obj.hmset("website", {"tencent": "www.qq.com", "alibaba": "www.taobao.com"})
# 3、获取某一个键的值
result = self.redis_obj.hget("website", 'baidu')
print("键为baidu的值为:", result)
# 4、获取多个键的值
result = self.redis_obj.hmget("website", "baidu", "alibaba")
print("多个键的值为:", result)
# 5、查看hash表中的所有值
result = self.redis_obj.hgetall('website')
print("哈希表中所有的键值对为:", result)
# 6、哈希表中所有键列表
# ['baidu', 'google', 'tencent', 'alibaba']
result = self.redis_obj.hkeys("website")
print("哈希表,所有的键(列表)为:", result)
# 7、哈希表中所有的值列表
# ['www.alibababaidu.com', 'www.google.com', 'www.qq.com', 'www.taobao.com']
result = self.redis_obj.hvals("website")
print("哈希表,所有的值(列表)为:", result)
# 8、判断某一个键是否存在
result = self.redis_obj.hexists("website", "alibaba")
print('alibaba这个键是否存在:', result)
# 9、删除某一个键值对
self.redis_obj.hdel("website", 'baidu')
print('删除baidu键值对后,哈希表的数据包含:', self.redis_obj.hgetall('website'))
# 10、哈希表中键值对个数
count = self.redis_obj.hlen("website")
print('哈希表键值对一共有:', count)5、操作事务管道
Redis 支持事务管道操作,能够将几个操作统一提交执行
操作步骤是:
首先,定义一个事务管道
然后通过事务对象去执行一系列操作
提交事务操作,结束事务操作
下面通过一个简单的例子来说明:
def manage_steps(self):
"""
执行事务操作
:return:
"""
# 1、定义一个事务管道
self.pip = self.redis_obj.pipeline()
# 定义一系列操作
self.pip.set('age', 18)
# 增加一岁
self.pip.incr('age')
# 减少一岁
self.pip.decr('age')
# 执行上面定义3个步骤的事务操作
self.pip.execute()
# 判断
print('通过上面一些列操作,年龄变成:', self.redis_obj.get('age'))위 내용은 Python Redis 데이터 처리 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 REDIS : 건축과 목적을 이해합니다Apr 26, 2025 am 12:11 AM
REDIS : 건축과 목적을 이해합니다Apr 26, 2025 am 12:11 AMRedis는 주로 데이터베이스, 캐시 및 메시지 중개인으로 사용되는 메모리 데이터 구조 스토리지 시스템입니다. 핵심 기능에는 단일 스레드 모델, I/O 멀티플렉싱, 지속 메커니즘, 복제 및 클러스터링 기능이 포함됩니다. Redis는 일반적으로 캐싱, 세션 저장 및 메시지 대기열을위한 실제 응용 프로그램에 사용됩니다. 올바른 데이터 구조를 선택하고 파이프 라인 및 트랜잭션을 사용하여 모니터링 및 튜닝을 통해 성능을 크게 향상시킬 수 있습니다.
 Redis vs. SQL 데이터베이스 : 주요 차이점Apr 25, 2025 am 12:02 AM
Redis vs. SQL 데이터베이스 : 주요 차이점Apr 25, 2025 am 12:02 AMRedis와 SQL 데이터베이스의 주요 차이점은 Redis가 고성능 및 유연성 요구 사항에 적합한 메모리 데이터베이스라는 것입니다. SQL 데이터베이스는 관계형 데이터베이스로 복잡한 쿼리 및 데이터 일관성 요구 사항에 적합합니다. 구체적으로, 1) Redis는 고속 데이터 액세스 및 캐싱 서비스를 제공하고 캐싱 및 실시간 데이터 처리에 적합한 여러 데이터 유형을 지원합니다. 2) SQL 데이터베이스는 테이블 구조를 통한 데이터를 관리하고 복잡한 쿼리 및 트랜잭션 처리를 지원하며 데이터 일관성이 필요한 전자 상거래 및 금융 시스템과 같은 시나리오에 적합합니다.
 Redis : 데이터 저장소 및 서비스 역할을하는 방법Apr 24, 2025 am 12:08 AM
Redis : 데이터 저장소 및 서비스 역할을하는 방법Apr 24, 2025 am 12:08 AMredisactsasbothadatastoreandaservice.1) asadatastore, itusesin-memorystorageforfastoperations, 지원을 지원합니다
 Redis 대 기타 데이터베이스 : 비교 분석Apr 23, 2025 am 12:16 AM
Redis 대 기타 데이터베이스 : 비교 분석Apr 23, 2025 am 12:16 AMredis 与其他数据库相比 与其他数据库相比, 与其他数据库相比 : 1) 速度极快 速度极快 速度极快, 读写操作通常在微秒级别; 2) 支持丰富的数据结构和操作; 3) 灵活的使用场景 3) 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 灵活的使用场景 3) redis 또는 기타 데이터베이스를 선택할 때 특정 요구 사항과 시나리오에 따라 다릅니다. Redis는 고성능 및 저도가 낮은 응용 프로그램에서 잘 수행됩니다.
 Redis의 역할 : 데이터 저장 및 관리 기능 탐색Apr 22, 2025 am 12:10 AM
Redis의 역할 : 데이터 저장 및 관리 기능 탐색Apr 22, 2025 am 12:10 AMRedis는 데이터 저장 및 관리에서 핵심적인 역할을하며 여러 데이터 구조 및 지속 메커니즘을 통해 현대 애플리케이션의 핵심이되었습니다. 1) Redis는 문자열, 목록, 컬렉션, 주문 컬렉션 및 해시 테이블과 같은 데이터 구조를 지원하며 캐시 및 복잡한 비즈니스 로직에 적합합니다. 2) RDB와 AOF의 두 가지 지속 방법을 통해 Redis는 신뢰할 수있는 스토리지 및 데이터의 빠른 복구를 보장합니다.
 REDIS : NOSQL 개념 이해Apr 21, 2025 am 12:04 AM
REDIS : NOSQL 개념 이해Apr 21, 2025 am 12:04 AMRedis는 대규모 데이터의 효율적인 저장 및 액세스에 적합한 NOSQL 데이터베이스입니다. 1.Redis는 여러 데이터 구조를 지원하는 오픈 소스 메모리 데이터 구조 스토리지 시스템입니다. 2. 캐싱, 세션 관리 등에 적합한 매우 빠른 읽기 및 쓰기 속도를 제공합니다. 3. REDIS는 RDB 및 AOF를 통해 지속성을 지원하고 데이터 보안을 보장합니다. 4. 사용 예제에는 기본 키 값 쌍 작업 및 고급 수집 중복 제거 기능이 포함됩니다. 5. 일반적인 오류에는 연결 문제, 데이터 유형 불일치 및 메모리 오버플로가 포함되므로 디버깅에주의를 기울여야합니다. 6. 성능 최적화 제안에는 적절한 데이터 구조 선택 및 메모리 제거 전략 설정이 포함됩니다.
 REDIS : 실제 사용 사례 및 예제Apr 20, 2025 am 12:06 AM
REDIS : 실제 사용 사례 및 예제Apr 20, 2025 am 12:06 AM실제 세계에서 Redis의 애플리케이션에는 다음이 포함됩니다. 1. 캐시 시스템으로서 데이터베이스 쿼리를 가속화, 2. 웹 응용 프로그램의 세션 데이터를 저장하려면 3. 실시간 순위를 구현하려면 메시지 전달을 메시지 큐로 단순화합니다. Redis의 다목적 성과 고성능은 이러한 시나리오에서 빛을 발합니다.
 Redis : 기능과 기능을 탐색합니다Apr 19, 2025 am 12:04 AM
Redis : 기능과 기능을 탐색합니다Apr 19, 2025 am 12:04 AMRedis는 고속, 다양성 및 풍부한 데이터 구조로 인해 두드러집니다. 1) Redis는 문자열, 목록, 컬렉션, 해시 및 주문 컬렉션과 같은 데이터 구조를 지원합니다. 2) 메모리를 통해 데이터를 저장하고 RDB 및 AOF 지속성을 지원합니다. 3) Redis 6.0에서 시작하여 멀티 스레드 I/O 작업이 도입되어 동시 동시성 시나리오에서 성능이 향상되었습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

