
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL에서 느린 SQL을 빠르게 찾는 방법
MySQL에서 느린 SQL을 빠르게 찾는 방법

- PHPz앞으로
- 2023-06-02 19:34:122078검색
느린 쿼리 로그 활성화
프로젝트에서 느린 쿼리를 자주 접하게 되면 일반적으로 느린 쿼리 로그를 활성화하고 느린 쿼리 로그를 분석한 다음 느린 SQL을 찾은 다음 explain을 사용하여 분석해야 합니다.
시스템 변수
MySQL 및 느린 쿼리와 관련된 시스템 변수는 다음과 같습니다
| Parameters | Meaning |
|---|---|
| slow_query_log | 느린 쿼리 로그 활성화 여부를 켜면 활성화, 끄면 활성화하지 않음 활성화하면 기본값은 OFF입니다. |
| log_output | 로그 출력 위치는 기본적으로 FILE로 설정됩니다. 즉, TABLE로 설정하면 로그가 mysql.show_log 테이블에 기록됩니다. |
| slow_query_log_file | 느린 쿼리 로그 파일의 경로와 이름을 지정합니다. |
| long_query_time | 느린 쿼리 로그는 실행 시간이 이 값을 초과하는 경우에만 기록됩니다. 단위는 10초입니다. |
다음 명령문을 실행하여 느린 쿼리 로그가 활성화되었는지 확인합니다. ON은 활성화됨을 의미하고, OFF는 활성화되지 않음을 의미합니다.
show variables like "%slow_query_log%"
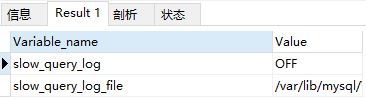
내 로그가 활성화되지 않은 것을 볼 수 있습니다. 다음 두 가지 방법으로 느린 쿼리를 활성화할 수 있습니다
구성 파일을 수정하세요
구성 파일 my.ini를 수정하고 [mysqld] 섹션에 다음 매개변수를 추가하세요
[mysqld] log_output='FILE,TABLE' slow_query_log='ON' long_query_time=0.001
적용하려면 MySQL을 다시 시작해야 합니다. 명령은 service mysqld restart
전역 변수 설정
입니다. 명령줄에서 다음 2문장을 실행하여 느린 로그 쿼리를 열고, 시간 제한을 0.001초로 설정하고, 로그를 파일과 mysql.slow_log 테이블
set global slow_query_log = on; set global log_output = 'FILE,TABLE'; set global long_query_time = 0.001;
에 기록합니다. 영구적으로 만들고 싶다면, 구성 파일에서 구성을 가져오세요. 그렇지 않으면 데이터베이스가 다시 시작된 후 이러한 구성이 유효하지 않게 됩니다
느린 쿼리 로그 분석
mysql 느린 쿼리 로그는 실행 중인 계정과 동일하며 요약 통계 기능이 없기 때문에, 따라서 이를 분석하려면 몇 가지 도구를 사용해야 합니다
mysqldumpslow
mysql에는 느린 쿼리 로그를 분석하는 데 도움이 되는 mysqldumpslow 도구가 내장되어 있습니다.
일반적인 사용법
# 取出使用最多的10条慢查询 mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log # 取出查询时间最慢的3条慢查询 mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log # 得到按照时间排序的前10条里面含有左连接的查询语句 mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log
pt-query-digest
pt-query-digest는 제가 가장 많이 사용하는 도구인데 binlog, 일반 로그, Slowlog를 분석할 수 있고 show를 통해서도 사용할 수 있습니다. processlist 또는 tcpdump에서 캡처한 MySQL 프로토콜 데이터를 분석합니다. pt-query-digest Perl 스크립트를 실행하려면 다운로드하고 인증하세요
다운로드 및 권한 부여
wget www.percona.com/get/pt-query-digest chmod u+x pt-query-digest ln -s /opt/soft/pt-query-digest /usr/bin/pt-query-digest
사용 소개
// 查看具体使用方法 pt-query-digest --help // 使用格式 pt-query-digest [OPTIONS] [FILES] [DSN]
일반적으로 사용되는 OPTIONS
--create-review-table 사용 시-- review 매개변수는 분석 결과를 테이블로 출력하며, 테이블이 없으면 자동으로 생성됩니다.
--create-history-table --history 매개변수를 사용하여 분석 결과를 테이블로 출력할 때 테이블이 없으면 자동으로 생성됩니다.
--filter 입력된 느린 쿼리를 지정된 문자열에 따라 일치 및 필터링한 다음 분석합니다.
-limit는 출력 결과의 백분율 또는 수를 제한합니다. 기본값은 가장 느린 20입니다. 50%일 경우 전체 응답 시간에 따라 큰 것부터 작은 것 순으로 출력하고, 전체가 50%에 도달하면 출력을 차단합니다.
--host mysql 서버 주소
--user mysql 사용자 이름
--password mysql 사용자 비밀번호
--history 분석 결과를 테이블에 저장하면 분석 결과가 더욱 상세해집니다. 다음에 --history를 사용할 때 동일한 문이 존재하고 쿼리의 시간 간격이 기록 테이블과 다른 경우 데이터 테이블에 기록됩니다. 특정 유형의 기록 변경 사항을 비교할 수 있습니다. 동일한 CHECKSUM을 쿼리하여 쿼리합니다.
--review 분석 결과를 테이블에 저장합니다. 이 분석은 쿼리 조건만 매개변수화합니다. 쿼리 유형 중 하나는 비교적 간단합니다. 동일한 구문 분석이 발생하면 다음 --review를 사용할 때 데이터 테이블에 기록되지 않습니다.
--분석 결과 출력 유형, 값은 보고서(표준 분석 보고서), Slowlog(Mysql 느린 로그), json, json-anon일 수 있으며 일반적으로 쉽게 읽을 수 있도록 보고서를 사용합니다.
--since는 분석이 시작된 이후의 시간입니다. 값은 "yyyy-mm-dd [hh:mm:ss]" 형식으로 지정된 시점일 수 있습니다. 값은 단순 시간일 수 있습니다. s(초), h(시간), m(분), d(일). 예를 들어 12h는 통계가 12시간 전에 시작되었음을 의미합니다.
--마감일까지 -since와 결합하면 일정 기간 내에 느린 쿼리를 분석할 수 있습니다.
공통 DSN
A 문자 집합 지정
D 연결할 데이터베이스 지정
P 데이터베이스 포트에 연결
S 소켓 파일에 연결
h 데이터베이스 호스트 이름에 연결
p 연결 비밀번호
t --review 또는 -를 사용하십시오. 기록 중에 데이터를 어떤 테이블에 저장해야 합니까?
u 데이터베이스 사용자 이름을 연결합니다.
DSN은 키=값 형식으로 구성됩니다. 별도의
사용예
# 展示slow.log中最慢的查询的报表 pt-query-digest slow.log # 分析最近12小时内的查询 pt-query-digest --since=12h slow.log # 分析指定范围内的查询 pt-query-digest slow.log --since '2020-06-20 00:00:00' --until '2020-06-25 00:00:00' # 把slow.log中查询保存到query_history表 pt-query-digest --user=root --password=root123 --review h=localhost,D=test,t=query_history --create-review-table slow.log # 连上localhost,并读取processlist,输出到slowlog pt-query-digest --processlist h=localhost --user=root --password=root123 --interval=0.01 --output slowlog # 利用tcpdump获取MySQL协议数据,然后产生最慢查询的报表 # tcpdump使用说明:https://blog.csdn.net/chinaltx/article/details/87469933 tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txt pt-query-digest --type tcpdump mysql.tcp.txt # 分析binlog mysqlbinlog mysql-bin.000093 > mysql-bin000093.sql pt-query-digest --type=binlog mysql-bin000093.sql # 分析general log pt-query-digest --type=genlog localhost.log
실용
쓰기 저장 프로세스 일괄 데이터 생성
실제 작업에서는 대규모 배치 데이터를 변환해야 하는 경우가 종종 있습니다. 이때 수동 삽입이 불가능합니다. 저장 프로시저를 사용하려면
CREATE TABLE `kf_user_info` ( `id` int(11) NOT NULL COMMENT '用户id', `gid` int(11) NOT NULL COMMENT '客服组id', `name` varchar(25) NOT NULL COMMENT '客服名字' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='客户信息表';
저장 프로시저를 어떻게 정의하나요?
CREATE PROCEDURE 存储过程名称 ([参数列表])
BEGIN
需要执行的语句
END예를 들어 ID가 1~100000인 데이터 100,000개를 삽입합니다.
Navicat을 사용하여 실행
-- 删除之前定义的 DROP PROCEDURE IF EXISTS create_kf; -- 开始定义 CREATE PROCEDURE create_kf(IN loop_times INT) BEGIN DECLARE var INT; SET var = 1; WHILE var < loop_times DO INSERT INTO kf_user_info (`id`,`gid`,`name`) VALUES (var, 1000, var); SET var = var + 1; END WHILE; END; -- 调用 call create_kf(100000);
3가지 매개변수 유형의 저장 프로시저
| 매개변수 유형 | 반환 여부 | 함수 |
|---|---|---|
| IN | No | 저장 프로시저에 매개 변수를 입력합니다. 매개 변수의 값은 저장 프로시저 중에 수정되어 반환될 수 없습니다. |
| OUT | Yes | 저장 프로시저에서 계산한 결과를 이 매개 변수에 넣습니다. 호출자는 반환 값을 얻을 수 있습니다 |
| INOUT | 은 | IN과 OUT의 조합으로, 프로시저의 들어오는 매개 변수를 저장하는 데 사용됩니다. 동시에 계산 구조를 매개 변수에 넣을 수 있습니다. , 호출자는 반환 값을 얻을 수 있습니다 |
用MySQL执行
得用DELIMITER 定义新的结束符,因为默认情况下SQL采用(;)作为结束符,这样当存储过程中的每一句SQL结束之后,采用(;)作为结束符,就相当于告诉MySQL可以执行这一句了。但是存储过程是一个整体,我们不希望SQL逐条执行,而是采用存储过程整段执行的方式,因此我们就需要定义新的DELIMITER ,新的结束符可以用(//)或者($$)
因为上面的代码应该就改为如下这种方式
DELIMITER // CREATE PROCEDURE create_kf_kfGroup(IN loop_times INT) BEGIN DECLARE var INT; SET var = 1; WHILE var <= loop_times DO INSERT INTO kf_user_info (`id`,`gid`,`name`) VALUES (var, 1000, var); SET var = var + 1; END WHILE; END // DELIMITER ;
查询已经定义的存储过程
show procedure status;
开始执行慢sql
select * from kf_user_info where id = 9999; select * from kf_user_info where id = 99999; update kf_user_info set gid = 2000 where id = 8888; update kf_user_info set gid = 2000 where id = 88888;
可以执行如下sql查看慢sql的相关信息。
SELECT * FROM mysql.slow_log order by start_time desc;
查看一下慢日志存储位置
show variables like "slow_query_log_file"
pt-query-digest /var/lib/mysql/VM-0-14-centos-slow.log
执行后的文件如下
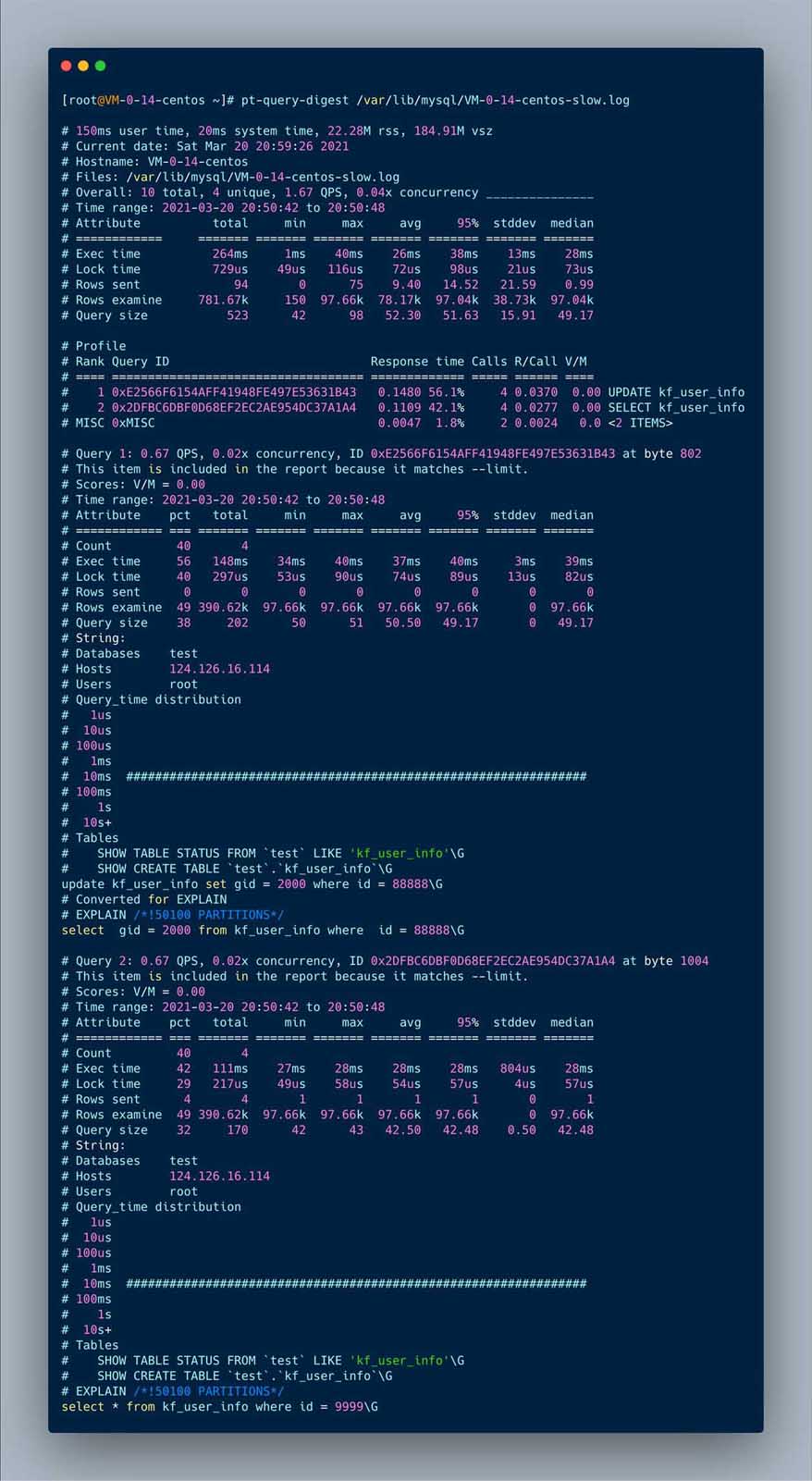
# Profile # Rank Query ID Response time Calls R/Call V/M # ==== =================================== ============= ===== ====== ==== # 1 0xE2566F6154AFF41948FE497E53631B43 0.1480 56.1% 4 0.0370 0.00 UPDATE kf_user_info # 2 0x2DFBC6DBF0D68EF2EC2AE954DC37A1A4 0.1109 42.1% 4 0.0277 0.00 SELECT kf_user_info # MISC 0xMISC 0.0047 1.8% 2 0.0024 0.0 <2 ITEMS>
从最上面的统计sql中就可以看到执行慢的sql
可以看到响应时间,执行次数,每次执行耗时(单位秒),执行的sql
下面就是各个慢sql的详细分析,比如,执行时间,获取锁的时间,执行时间分布,所在的表等信息
不由得感叹一声,真是神器,查看慢sql超级方便
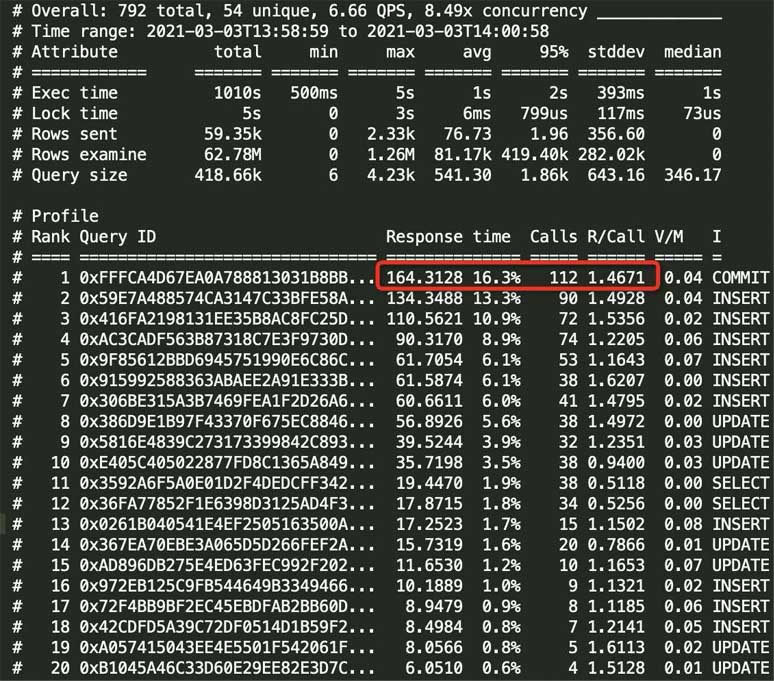
最后说一个我遇到的一个有意思的问题,有一段时间线上的接口特别慢,但是我查日志发现sql执行的很快,难道是网络的问题?
为了确定是否是网络的问题,我就用拦截器看了一下接口的执行时间,发现耗时很长,考虑到方法加了事务,难道是事务提交很慢?
于是我用pt-query-digest统计了一下1分钟左右的慢日志,发现事务提交的次很多,但是每次提交事务的平均时长是1.4s左右,果然是事务提交很慢。
위 내용은 MySQL에서 느린 SQL을 빠르게 찾는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!