
집 >데이터 베이스 >MySQL 튜토리얼 >mysql을 작성할 때 Spark SQL 지원 업데이트 작업을 만드는 방법
mysql을 작성할 때 Spark SQL 지원 업데이트 작업을 만드는 방법

- PHPz앞으로
- 2023-06-02 15:19:211969검색
Append, Overwrite, ErrorIfExists, Ignore 지원 외에도 업데이트 작업도 지원합니다
1. 먼저 배경을 이해하세요
spark는 도킹 데이터 소스의 작업 모드를 지원하는 열거형 클래스를 제공합니다
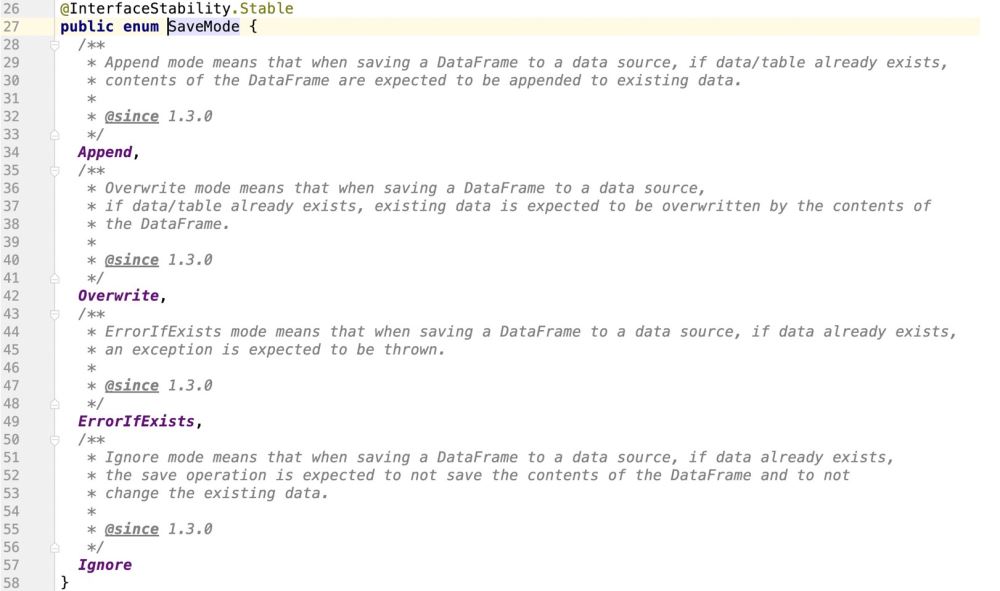
Pass Viewing 소스 코드를 보면 Spark가 업데이트 작업을 지원하지 않는 것이 분명합니다
2. SparkSQL 지원 업데이트를 만드는 방법
핵심 지식 포인트는 다음과 같습니다.
sparkSQL에서 일반적으로 mysql에 데이터를 쓸 때:
대략적인 API는 다음과 같습니다. :
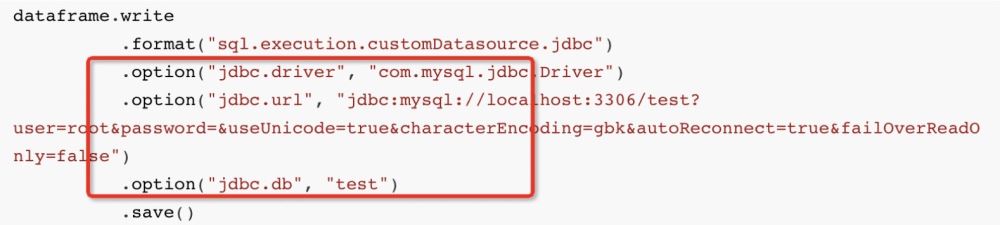
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()그런 다음 맨 아래 수준에서 Spark는 JDBC 방언 JdbcDialect를 사용하여 삽입하려는 데이터를 다음과 같이 변환합니다.
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
그런 다음 방언을 통해 구문 분석된 sql 문은 prepareStatement의 excuteBatch()를 통해 mysql에 제출됩니다.
그러면 위의 SQL 문은 명백합니다. 코드를 완전히 삽입하고 다음과 유사한 업데이트 작업이 없습니다.
UPDATE table_name SET field1=new-value1, field2=new-value2
그러나 mysql은 다음과 같은 SQL 문을 독점적으로 지원합니다.
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
대략적인 의미 즉, 데이터가 없으면 삽입합니다.
그래서 우리는 JdbcDialect
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
3와 내부적으로 연결될 때 Spark SQL이 이러한 SQL 문을 생성할 수 있도록 하는 데 중점을 둡니다. 소스 코드를 변환하려면 전반적인 코드 설계 및 실행 프로세스를 이해해야 합니다.
우선:
dataframe.write
write 메서드를 호출하면 클래스가 반환됩니다: DataFrameWriter
주로 DataFrameWriter는 SparkSQL이 연결할 클래스를 전달하는 항목이기 때문입니다. 외부 데이터 소스에 다음 내용이 등록됩니다. 정보 전달
그런 다음 save() 작업을 시작한 후 데이터 쓰기를 시작합니다.
다음으로 save() 소스 코드를 살펴보세요.
위 소스 코드에서 가장 중요한 것은 DataSource 인스턴스를 등록한 다음 DataSource의 write 메소드를 사용하여 데이터를 쓰는 것입니다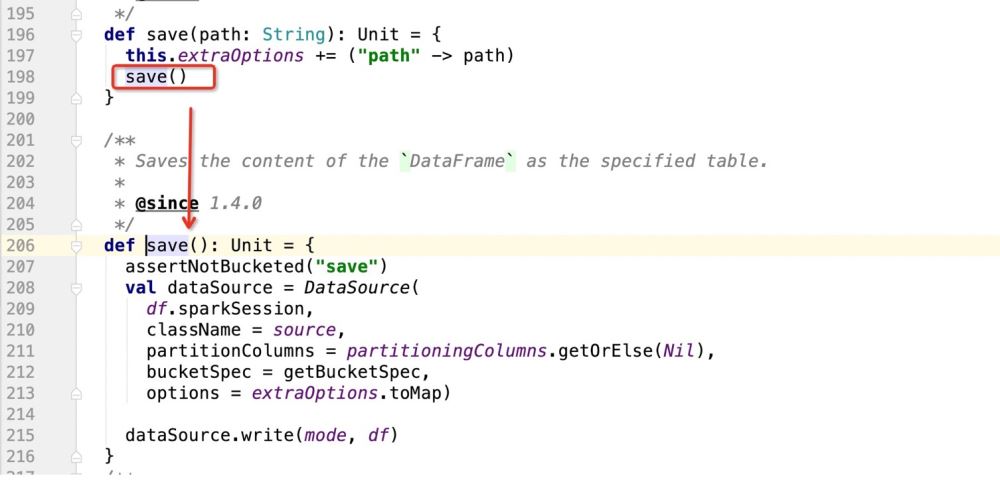
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
}그 다음에는 dataSource.write(mode, df) 전체 논리는 다음과 같습니다.providingClass.newInstance() 일치에 따라 모드를 만든 다음 일치하는 곳마다 코드를 실행합니다.
그런 다음 ProvideClass가 무엇인지 살펴보세요. 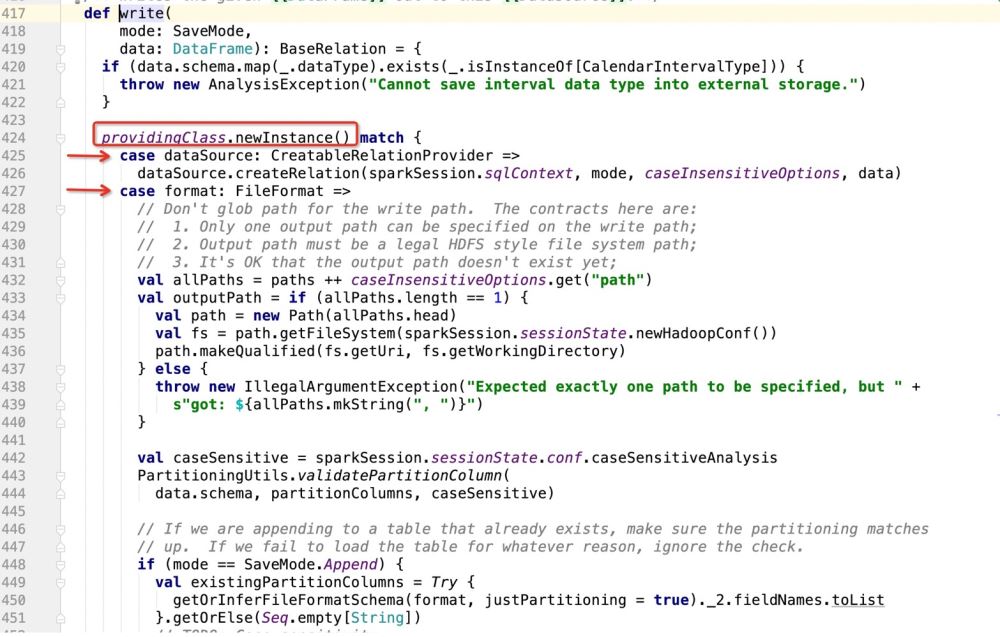
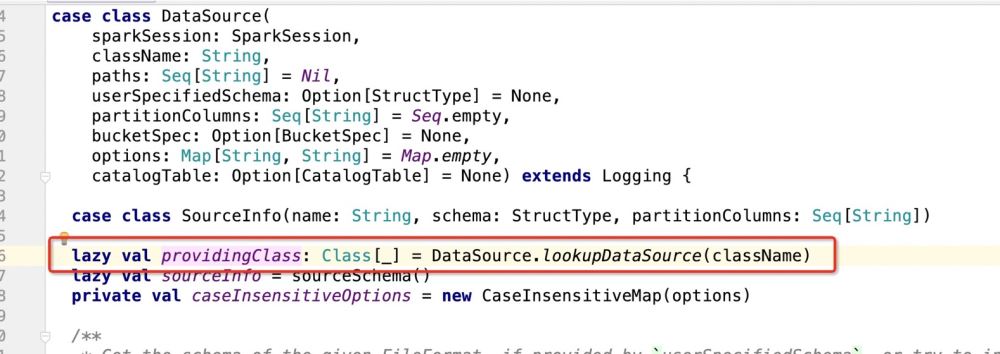
패키지 path.DefaultSource를 가져온 후 프로그램은 다음을 입력합니다. 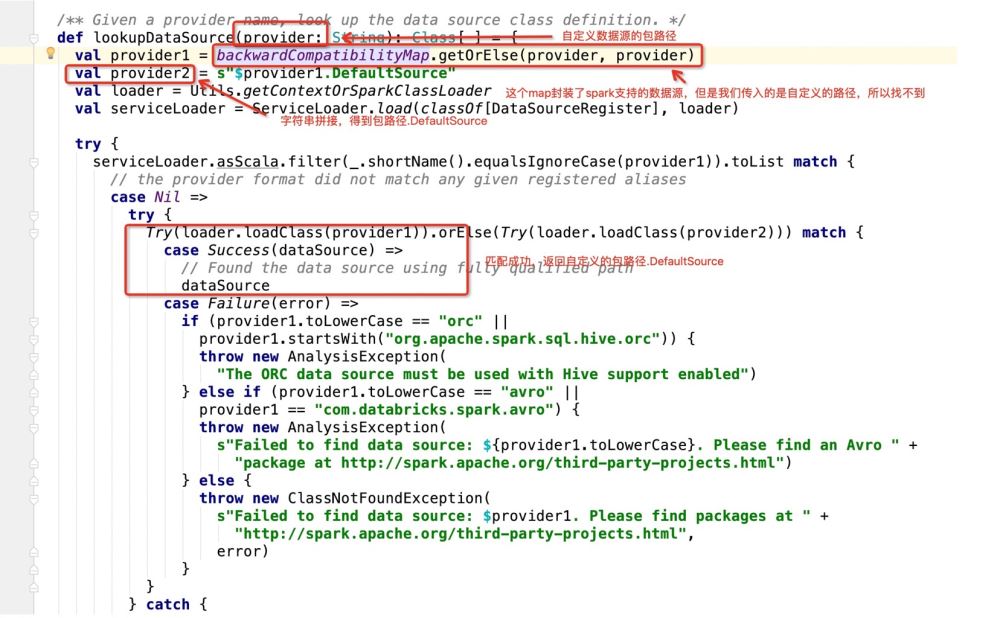
그런 다음 데이터베이스가 쓰기 대상으로 사용되는 경우 dataSource.createRelation으로 이동하고 소스 코드를 직접 따릅니다. 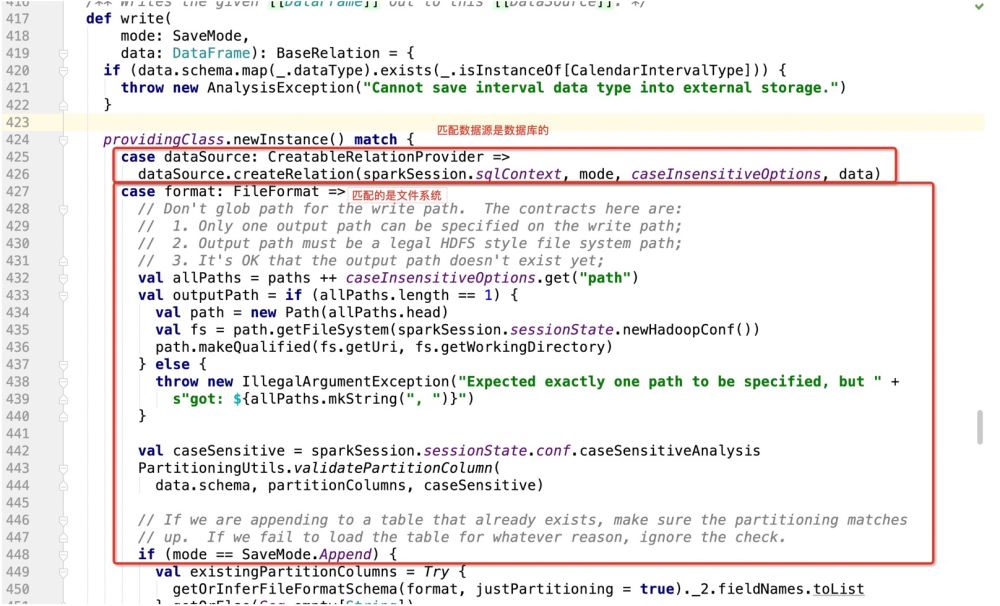
는 분명히 특성이므로 해당 특성이 구현된 곳으로 프로그램이 이동합니다. 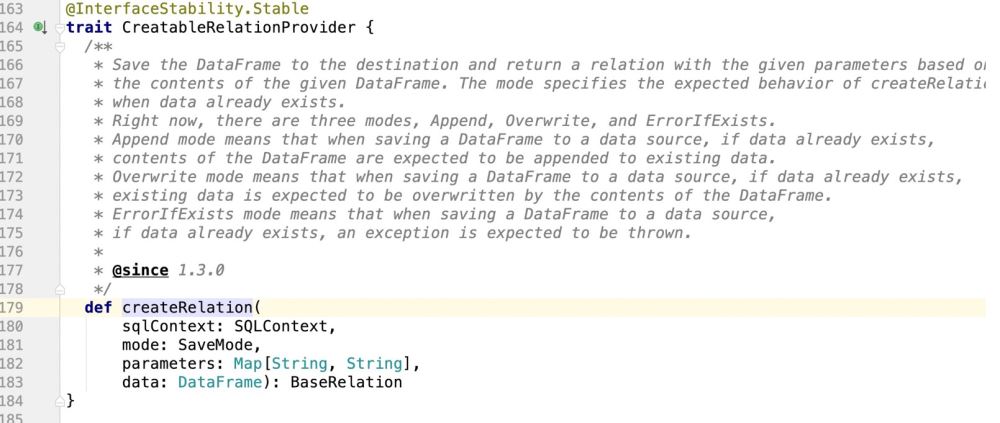
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
} 그러나 Spark 프로덕션 sql 문의 소스 코드에는 다음과 같이 작성되어 있습니다.
최종적으로 하나를 생성하는 판단 논리가 없습니다.
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)
첫 번째 작업은 만드는 방법입니다. 현재 코드는 다음을 지원합니다. ON DUPLICATE KEY UPDATE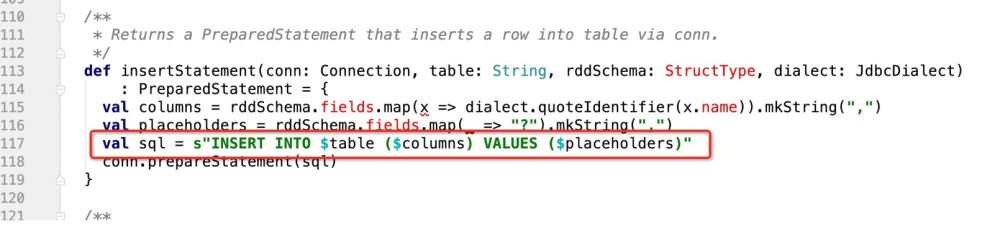
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect)
: PreparedStatement = {
val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
if(savemode == CustomSaveMode.update){
//TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting"
}esle{
val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)"
conn.prepareStatement(sql)
}
}이런 식으로 사용자가 전달한 savemode 모드에서 검증을 수행하고 업데이트 작업이면 해당 SQL 문을 반환합니다! 위의 논리에 따라 코드는 다음과 같이 작성됩니다.
이러한 방식으로 해당 SQL 문을 얻습니다.
그러나 이 SQL 문만으로는 충분하지 않습니다. 왜냐하면 jdbc의 prepareStatement 작업이 스파크에서 실행됩니다. 여기에는 커서가 포함됩니다. 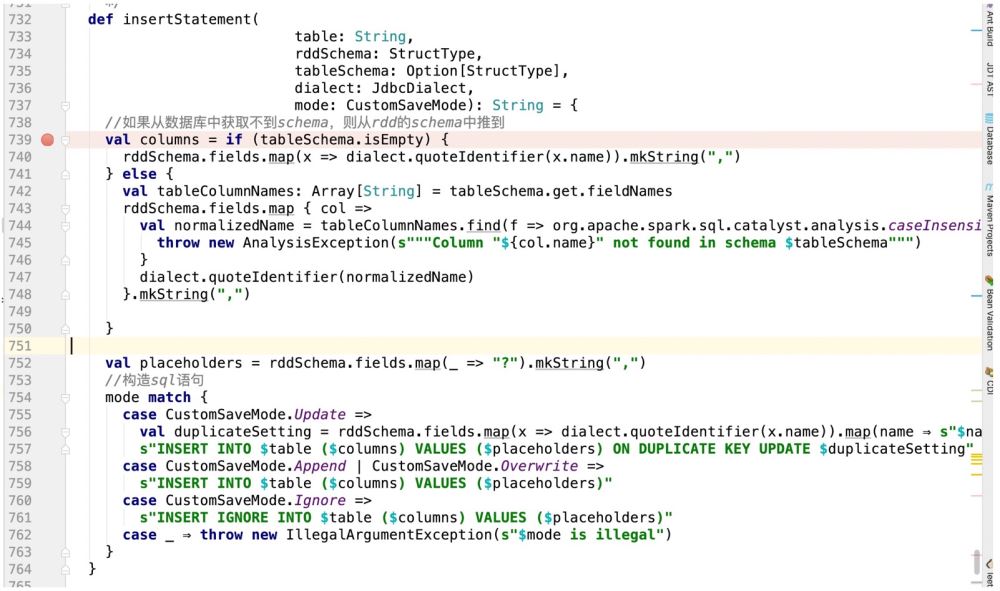
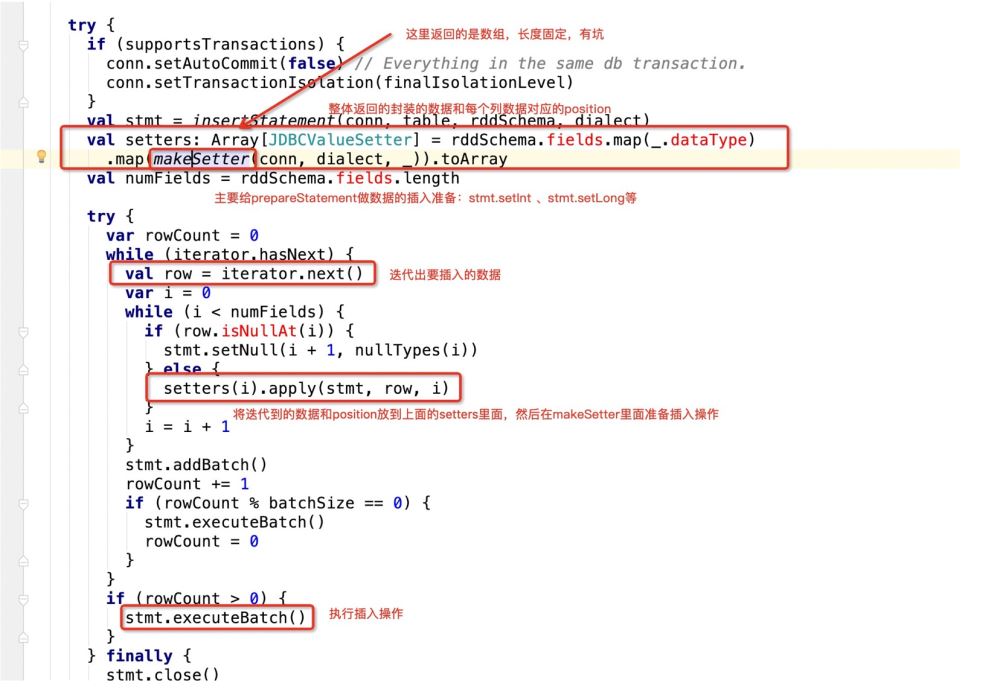
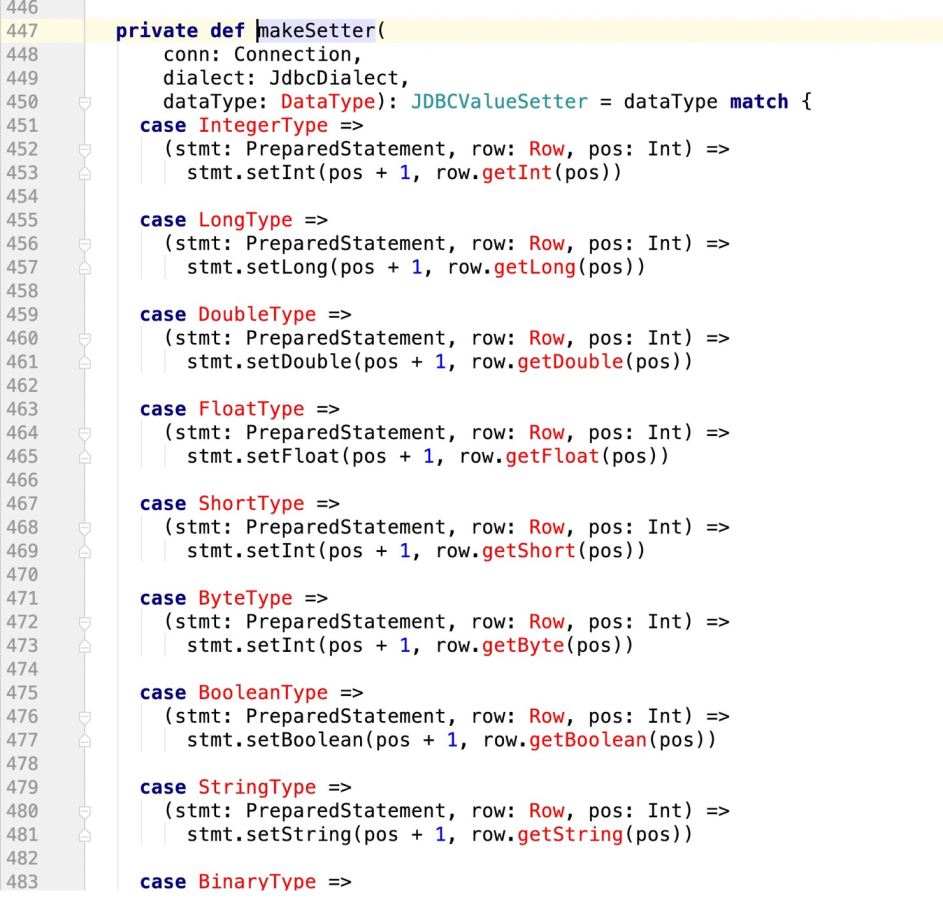
看下makeSetter:

所谓有坑就是:
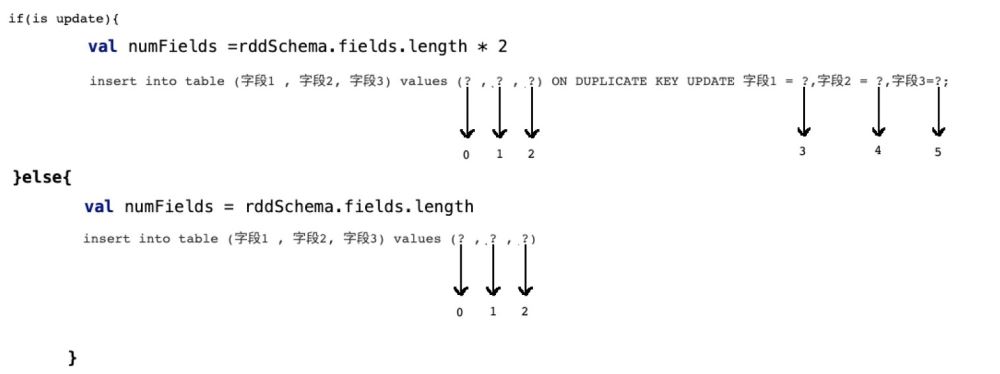
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
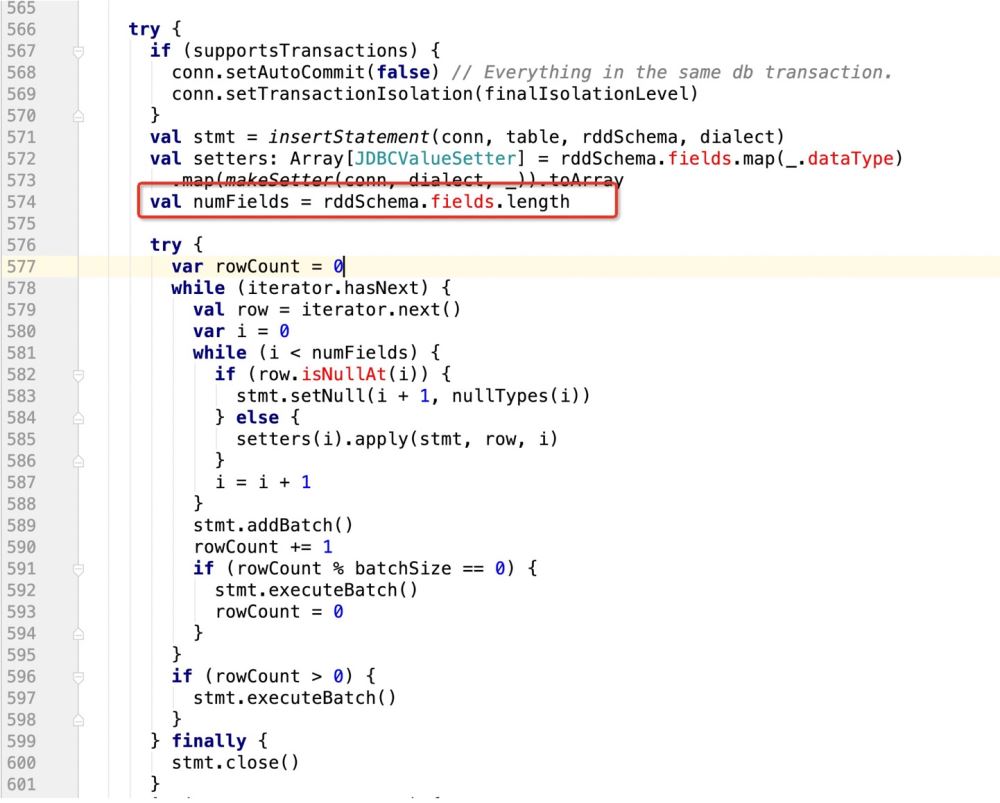
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:
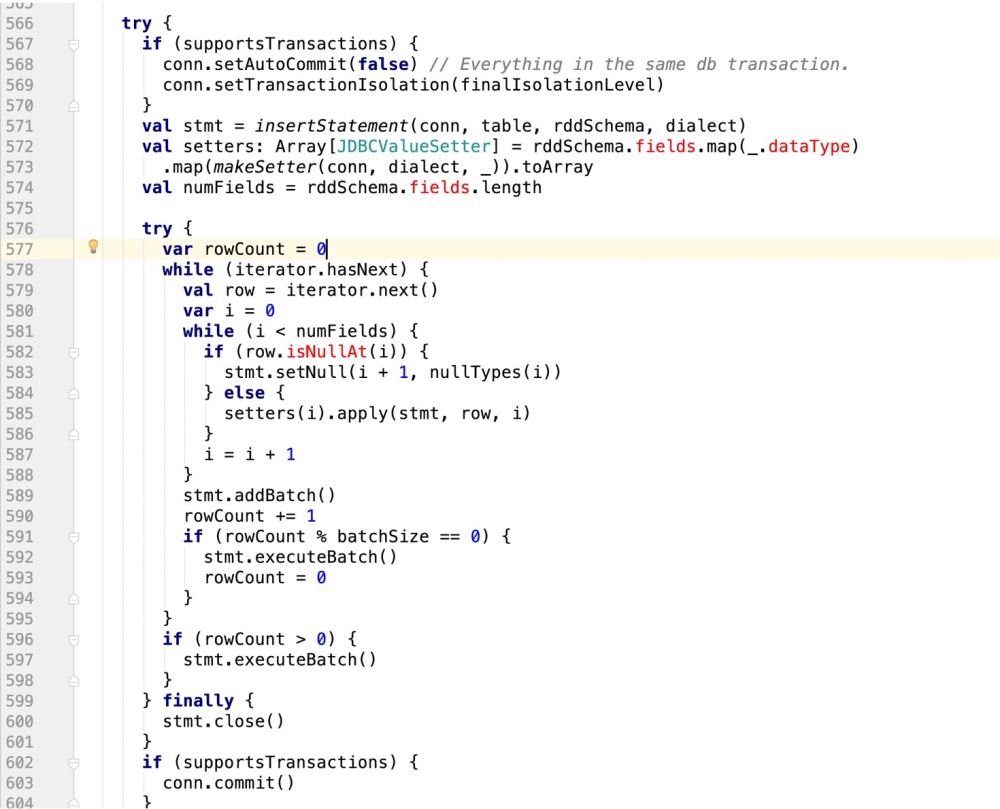
改造后的样子:
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}위 내용은 mysql을 작성할 때 Spark SQL 지원 업데이트 작업을 만드는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!