
서버 장애 인스턴스 분석

- 王林앞으로
- 2023-06-02 15:12:051317검색
1. 문제가 발생했습니다
저희는 IT 업계에 종사하다 보니 매일매일 실패와 문제를 처리해야 하므로 문제를 해결하기 위해 뛰어다니는 소방관이라고 할 수 있습니다. 그러나 이번 오류의 범위가 약간 커서 호스트 시스템을 열 수 없습니다.
다행히 감시 시스템이 증거를 남겼습니다.
모니터링이 정보를 수집할 수 없을 때까지 시스템의 CPU, 메모리 및 파일 핸들이 비즈니스 성장과 함께 계속 증가했다는 증거가 있습니다.
끔찍한 점은 이러한 호스트에 배포된 Java 프로세스가 많다는 것입니다. 비용 절감 외에는 다른 이유 없이 응용 프로그램을 혼합했습니다. 호스트가 전반적으로 이상 징후를 보일 경우, 범인을 찾는 것이 어려울 수 있습니다.
원격 로그인이 만료되었으므로 조급한 운영 및 유지 관리 담당자는 기계를 다시 시작하고 다시 시작한 후에 애플리케이션을 다시 시작하도록 선택할 수 있습니다. 오랜 기다림 끝에 모든 프로세스가 정상 작동으로 돌아왔지만, 잠시 후 호스트 시스템이 갑자기 충돌했습니다.
비즈니스가 교착 상태에 빠져 정말 짜증스럽습니다. 사람을 불안하게 만들기도 합니다. 여러 번 시도한 끝에 운영 및 유지 관리가 무너지고 비상 계획이 시작되었습니다: 롤백!
최근 온라인 기록이 많고 온라인에 가서 비공개로 배포하는 개발자도 있습니다. 롤백해야 하는가? 누군가 갑자기 좋은 아이디어를 떠올렸고 최근에 업데이트된 jar 패키지를 모두 찾아 롤백했습니다.
find /apps/deploy -mtime +3 | grep jar$
find 명령을 모르면 정말 재앙입니다. 다행히 누군가는 알고 있다.
12개 이상의 jar 패키지를 롤백했습니다. 다행히 데이터베이스에는 스키마 변경이 없었고, 마침내 시스템이 정상적으로 실행되었습니다.
2. 원인 찾기
다른 방법은 없으니 로그를 확인하고 코드 리뷰를 해보세요.
코드의 품질을 보장하기 위해 코드 검토 범위는 최근 1~2주 간의 코드 변경으로 제한되어야 합니다. 일부 기능 코드는 온라인에서 빛을 발하기 전에 성숙하는 데 일정 시간이 필요하기 때문입니다.
화면을 가득 채운 제출기록 "OK"를 보며 기술부장의 얼굴이 초록색으로 변했다.
"xjjdog이 "프로그래머의 80%가 커밋 레코드를 작성할 수 없다"고 했는데, 여러분 중 100%가 커밋 레코드를 작성할 수 없다고 생각합니다."
역사적 변화를 확인하기 위해 모두가 조용하고 고통을 견뎌냈습니다. 모두의 끊임없는 노력 끝에 우리는 마침내 똥산더미 속에서 문제가 있는 코드를 발견했습니다. CxO가 직접 만든 그룹으로, 모두가 문제를 일으킬 수 있는 코드를 던집니다.
"시스템 서비스가 한 시간 가까이 중단됐고, 그 영향은 매우 컸습니다." CxO는 "문제는 완전히 해결되어야 합니다. 투자자들은 이 문제에 대해 매우 우려하고 있습니다."라고 말했습니다. 딩톡, 모두의 몸짓이 획일화됩니다.
3. 스레드 풀 매개변수
코드가 많고, 모두가 오랫동안 문제 코드에 대해 논의해 왔습니다. 이 문장은 다음과 같이 다시 작성할 수 있습니다. 우리는 스레드 풀 사용에 특히 주의하면서 병렬 스트림을 사용하고 람다 식 내에 중첩된 일부 복잡한 코드를 검사했습니다.
결국 모두가 스레드 풀 코드를 다시 살펴보기로 결정했습니다. 구절 중 하나는 이렇게 말합니다.
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10), handler);
물론 매개변수도 괜찮고 거부 전략까지 고려됩니다.
Java의 스레드 풀을 사용하면 프로그래밍이 매우 간단해집니다. 이러한 매개변수는 위 이미지와 같이 하나씩 살펴보지 않으면 검토할 수 없습니다.
- corePoolSize: 코어 스레드는 생성된 후에도 유지됩니다.
- maxPoolSize: 최대 스레드 수
- keepAliveTime: 스레드 유휴 시간
- workQueue: 차단 대기열
- threadFactory: thread Create Factory
- handler: Rejection strategy
- 그들의 관계를 소개하겠습니다.
스레드 수가 코어 스레드 수보다 적고 새 작업이 도착하면 시스템은 작업을 처리하기 위해 새 스레드를 생성합니다. 현재 스레드 수가 코어 스레드 수를 초과하고 차단 대기열이 가득 차지 않은 경우 해당 작업은 차단 대기열에 배치됩니다. 스레드 수가 코어 스레드 수보다 많고 차단 대기열이 가득 차면 스레드 수가 maximumPoolSize 크기에 도달할 때까지 서비스를 제공하기 위해 새 스레드가 생성됩니다. 이때, 새로운 작업이 있으면 거부 정책이 실행됩니다.
거절 전략에 대해 다시 이야기해 보겠습니다. JDK에는 4개의 기본 제공 정책이 있으며, 기본값은 예외를 직접 발생시키는 AbortPolicy입니다. 아래에는 다른 여러 가지가 소개되어 있습니다.
- DiscardPolicy는 abort보다 더 급진적이며, 예외 정보도 없이 작업을 직접 삭제합니다.
- 작업 처리는 CallerRunsPolicy의 구현인 호출 스레드에 의해 실행됩니다. 웹 애플리케이션의 스레드 풀 리소스가 가득 차면 실행을 위해 Tomcat 스레드에 새 작업이 할당됩니다. 경우에 따라 이 메서드는 일부 작업의 실행 부담을 줄일 수 있지만 더 많은 경우에는 메인 스레드의 실행을 직접 차단합니다
- DiscardOldestPolicy는 대기열 맨 앞에 있는 작업을 삭제한 다음 해당 작업을 실행하려고 시도합니다. task again
- 이 스레드 풀 코드는 새로 추가된 것이고, 매개변수 설정도 비교적 합리적이므로 큰 문제는 없습니다. DiscardOldestPolicy 거부 정책을 사용하는 것이 유일한 위험입니다. 작업이 많은 경우 이 거부 정책으로 인해 작업이 대기열에 추가되고 요청 시간이 초과됩니다.
물론 이 리스크를 버릴 수는 없습니다. 솔직히 지금까지 발견된 리스크 코드 중 가장 가능성이 높은 코드입니다.
"DiscardOldestPolicy를 기본 AbortPolicy로 변경하고 다시 패키지한 후 온라인으로 사용해 보세요." 기술 전문가가 그룹에서 말했습니다.
4. 무엇이 문제일까요?
결과적으로 그레이스케일 서비스가 출시된 후 얼마 지나지 않아 호스트가 사망하게 되었습니다. 실행이 안된 이유가 뭔데 왜?
스레드 풀의 크기는 최소 100, 최대 200인데 아무것도 과하지 않습니다. 블로킹 큐의 용량은 10밖에 되지 않으므로 문제가 발생하지 않습니다. 이 스레드 풀 때문이라고 하면 죽더라도 못 믿겠다.
그런데 사업부에서는 이 코드를 추가하면 죽지만, 추가하지 않으면 괜찮을 것이라고 보고했습니다. 기술 전문가들은 머리를 긁적이며 그녀의 여동생에 대해 궁금해하고 있습니다.
결국 누군가는 더 이상 참지 못하고 비즈니스 코드를 다운로드하여 디버깅했습니다.
아이디어를 열었을 때 그는 혼란스러웠고 즉시 이해했습니다. 그는 마침내 이 코드가 왜 문제를 일으키는지 이해했습니다.
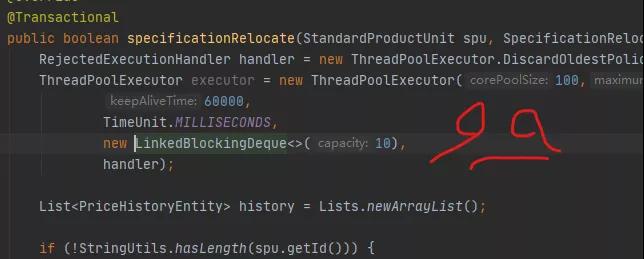
스레드 풀은 실제로 메서드에서 생성됩니다!
모든 요청이 오면 시스템이 더 이상 리소스를 할당할 수 없을 때까지 스레드 풀을 생성합니다.
정말 횡포하는군요.
스레드 풀의 매개변수가 어떻게 설정되는지 다들 주목하고 있지만, 이 코드의 위치를 의심한 사람은 아무도 없습니다.
위 내용은 서버 장애 인스턴스 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!