
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL에서 하위 데이터베이스와 테이블을 만드는 방법은 무엇입니까?
MySQL에서 하위 데이터베이스와 테이블을 만드는 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-02 12:34:143425검색
1. 왜 데이터베이스와 테이블을 나누어야 할까요?
웹사이트의 비즈니스가 빠르게 발전하면 웹사이트의 트래픽도 증가하고 데이터에 대한 압박도 따르게 됩니다. -커머스 시스템, Double Eleven 동시 Tps가 수십만 개로 주문 데이터에 대한 압박이 큽니다. 기존 아키텍처(마스터 1개와 슬레이브 여러 개)를 사용하는 경우 기본 데이터베이스 용량은 확실히 그렇게 높은 Tps를 충족할 수 없습니다. 비즈니스가 점점 커지고 단일 테이블 데이터가 데이터베이스 지원을 초과합니다. 용량, 영구 디스크 IO, 기존 데이터베이스 성능 병목 현상, 제품 관리자 비즈니스 - 해야 할 일, 프로그램 변경, 데이터베이스 나이프 분할 최적화. 데이터베이스 연결 수가 부족하고 테이블에 있는 데이터의 양이 많아 최적화 후에도 쿼리 성능이 여전히 낮기 때문에 분할이 필요합니다.
2. 샤딩 및 샤딩이란?
샤딩 및 샤딩 솔루션은 관계형 데이터베이스의 데이터 저장 및 액세스 메커니즘을 보완합니다.
하위 라이브러리: 한 라이브러리의 데이터를 여러 개의 동일한 라이브러리로 분할하고 액세스 시 하나의 라이브러리에 액세스합니다.
하위 테이블: 한 테이블의 데이터를 여러 테이블에 넣고, 해당 테이블
세 가지. 하위 데이터베이스 및 하위 테이블을 만드는 여러 가지 방법
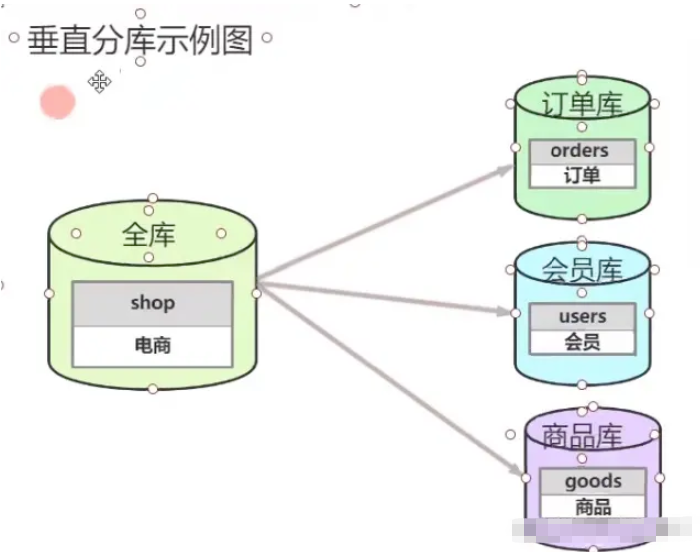
1. 수직 분할
(1) 데이터베이스의 수직 분할
그림과 같이 그림에서 전자상거래 시스템은 주문 데이터베이스, 회원 데이터베이스, 상품 데이터베이스로 분할됩니다.
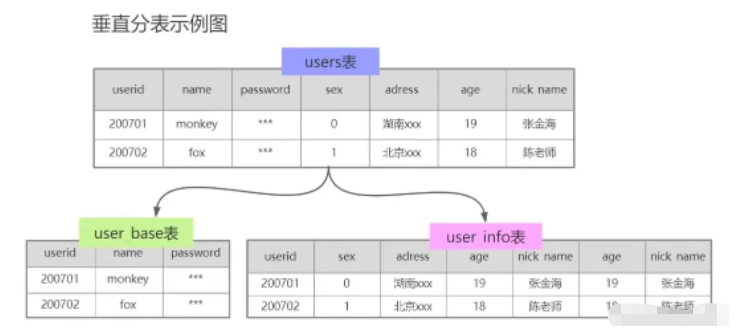
(2) 테이블을 수직으로 분할합니다
그림과 같이 업종에 따라 테이블을 분할합니다. 그림에서 user 테이블을 분할 user_base 테이블과 user_info 테이블로 분할, use_base는 로그인 저장을 담당, user_info는 기본 사용자 정보 저장을 담당
수직 분할 기능:
각 라이브러리의 구조(테이블 )가 다릅니다
각 데이터베이스(테이블)의 데이터는 적어도 하나의 열에서 동일해야 합니다
각 데이터베이스(테이블)의 합집합은 전체 데이터 양입니다
장점 수직 분할의 단점
장점:
분할 후 업무 지우기(업무별로 전용 데이터베이스 분할)
간단한 데이터 관리, 서로 다른 업무가 서로 다른 머신에 배치
단점:
단일 테이블의 데이터 양이 크면 쓰기 및 읽기 압력이 크다
는 특정 비즈니스에 의해 결정되거나 제한됩니다. 즉, 비즈니스가 데이터베이스의 병목 현상에 영향을 미치는 경우가 많습니다(성능 문제, Double Eleven 긴급 판매)
일부 비즈니스는 조인과 연결할 수 없으며 호출할 Java 프로그램 인터페이스만 연결할 수 있으므로 개발 복잡성이 증가합니다
2. 수평 분할
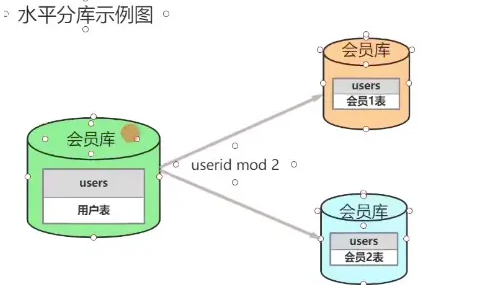
(1) 데이터베이스 가로 분할
그림과 같이 멤버 라이브러리로 분할, 멤버 1 라이브러리, 멤버 2 라이브러리로 분할, userId로 분할, userId 꼬리번호 0~5는 라이브러리 1, 6~9는 라이브러리 2, 모듈로를 취하는 다른 방법도 있는데 짝수는 라이브러리 1에 배치되고 홀수는 라이브러리 2에 배치됩니다
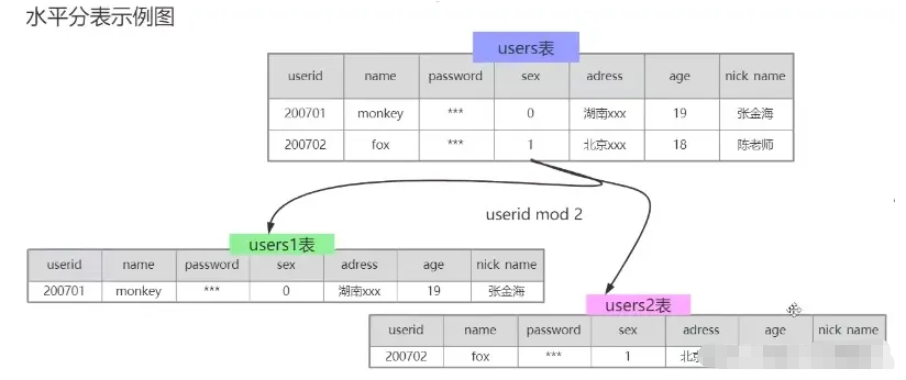
(2) 테이블 수평 분할
그림과 같이 사용자 테이블은 다음과 같이 분할됩니다. users1 테이블과 users2 테이블을 userId로 분할하고 모듈로를 사용하여 users1 테이블에 짝수를 배치하고 users2 테이블에 홀수를 배치합니다
다른 수평 분할 방법:
범위 분할, 각 데이터베이스에는 연속적인 데이터가 있으며 이는 일반적으로 시간 범위를 기반으로 하지만 핫스팟을 생성하기 쉽기 때문에 일반적으로 거의 사용되지 않습니다. 많은 수의 모든 트래픽이 최신 데이터를 기반으로 합니다. 장점: 확장할 때 매달 라이브러리만 준비하면 되기 때문에 매우 쉽습니다. 새 달이 오면 자연스럽게 새로운 라이브러리가 작성됩니다. 단점: 대부분의 요청이 최신 데이터에 액세스합니다. 범위의 실제 생산 사용은 시나리오에 따라 다릅니다. 사용자는 최신 데이터에 액세스할 수 있을 뿐만 아니라 현재 데이터와 과거 데이터
해시 분포에도 균등하게 액세스할 수 있습니다. 요청 압박의 단점: 용량 확장이 번거롭고, 데이터 마이그레이션 과정이 있을 것입니다
(3) 수평 분할 기능
-
각 데이터베이스(테이블)의 구조는 동일합니다
각 데이터베이스(테이블)의 데이터가 다릅니다
각 데이터베이스(테이블)의 합집합은 전체 데이터 양입니다
(4) 수평 분할의 장점과 단점
장점:
단일 데이터베이스/단일 테이블의 데이터를 일정량(축소)으로 유지하여 성능 향상에 도움이 되고
시스템의 안정성과 로드 용량이 향상됩니다
분할 테이블의 구조는 동일하며, 프로그램 수정이 적습니다.
단점:
데이터 확장이 매우 어렵고 유지 관리 비용이 큽니다.
분할 규칙을 추상화하기 어렵습니다.
샤딩된 트랜잭션의 일관성 문제 일부 비즈니스는 조인과 연결될 수 없습니다. Java 프로그램 인터페이스를 통해 호출
4. 하위 데이터베이스 및 하위 테이블로 인해 발생하는 문제
분산 트랜잭션
데이터베이스 간 조인 쿼리
분산 전역 고유 ID
개발 프로그래머에게는 비용이 많이 듭니다
5. 서브 데이터베이스 및 서브 테이블 기술을 선택하는 방법
(1) 서브 데이터베이스 및 서브 테이블을 위한 오픈 소스 프레임워크
jdbc 직접 연결 레이어: shardingsphere, tddl
proxy 프록시 레이어: mycat, mysql-proxy (360)
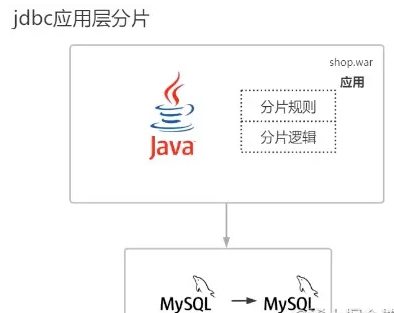
jdbc 직접 연결 레이어
jdbc 직접 연결 레이어라고도 함 BC 애플리케이션 레이어, 모든 샤딩 규칙, 분산 트랜잭션 처리를 포함한 모든 샤딩 슬라이스 로직은 모두 애플리케이션 계층에 있기 때문에 모든 샤드는 jar 패키지로 작성되고 war 패키지에 배치됩니다. 예, 가상 머신이 실행 중이면 classLoder에 의해 war 패키지의 바이트 파일이 jvm 메모리에 로드됩니다. 모든 샤딩 로직은 메모리 측
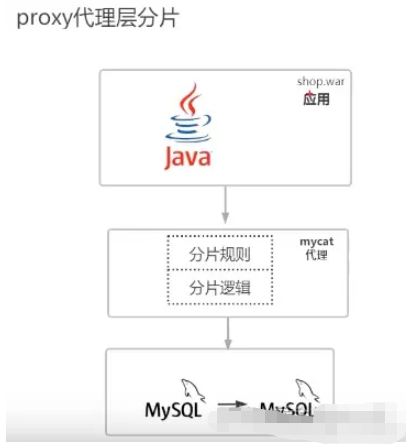
(2) 프록시 레이어를 기반으로 작동됩니다.
 그림과 같이 프록시 레이어, 모든 샤딩 규칙, 분산 트랜잭션 처리를 포함한 모든 샤딩 로직은 모두 mycat 측을 기반으로 작성됩니다
그림과 같이 프록시 레이어, 모든 샤딩 규칙, 분산 트랜잭션 처리를 포함한 모든 샤딩 로직은 모두 mycat 측을 기반으로 작성됩니다
- jdbc 직접 연결 계층은 고성능, Java 언어만 지원, 교차 데이터베이스 지원
- 프록시 프록시 계층은 개발 비용이 저렴하고, 교차 언어를 지원하며, 하지만 교차 데이터베이스
- 는 지원하지 않습니다.
위 내용은 MySQL에서 하위 데이터베이스와 테이블을 만드는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!