
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL에 저장된 데이터를 쿼리할 때 대문자와 소문자를 구별하는 방법
MySQL에 저장된 데이터를 쿼리할 때 대문자와 소문자를 구별하는 방법

- 王林앞으로
- 2023-05-31 16:26:313717검색
장면 설명
오늘 Hive 테이블을 MySQL에 동기화한 후 열 중 하나가 유일한 열인데 MySQL에서 쿼리할 때 count 및 distinct count 쿼리된 값이 다르다는 점에서 중복된 데이터가 있는 것으로 보입니다(Hive에서는 두 값이 동일하므로 그럴 수 없습니다). 그러면 중복된 데이터를 확인해보세요. 살펴보니 대소문자 문제라는 것을 알았고, 확인한 결과 MySQL 데이터베이스에서 기본적으로 문자열 필드에 대한 모든 관련 작업은 "대소문자를 구분하지 않음"을 발견했습니다. count 与 distinct count 查询出来的数值是不一样的,这么来看的话是有重复的数据(按理说不应该的,因为在 Hive 中,这两个数值是一样的),那么将重复的数据查出来看了一下,发现是大小写的问题,然后查了一下,发现 MySQL 数据库默认情况下,字符串字段的所有相关运算是大小写"不敏感"的。
这一点与其它流行的数据库都不相同。
解决办法
1. 查询时指定大小写敏感
MySQL 允许在查询的时候指定以大小写敏感方式,需要使用关键字 BINARY,查询如下:
SELECT * FROM student WHERE BINARY name = 'ZhangSan'; --或者 SELECT * FROM student WHERE name = BINARY 'ZhangSan';
很多时候当发现 MySQL 数据库存在上述问题时,系统已经运行了一段时间,如果采用方法二或方法三的代价可能会很大。
使用此方法最大的好处便是可以快速实现功能。
但是这个方法也存在很大的限制:如此可能因为无法使用索引导致查询性能下降。
原因很好理解,因为此时针对查询字段的索引也是按照大小写不敏感方式建立的。
除非数据量不大,或者在你的应用中不在乎这点性能上的损失,那么只能选择方法二或方法三了。
2. 定义表结构时指定字段大小写敏感
在创建表时指定具体的字段大小写敏感,示例如下:
CREATE TABLE student ( ... name VARCHAR(64) BINARY NOT NULL, ... )
关键字 BINARY 指定 name 字段大小写敏感。
如此在查询时就算不使用 BINARY 关键字,查询语句也是大小写敏感的。
在此基础上创建的 name 相关的索引也是大小写敏感的,也就能够使用索引来提高性能。
MySQL 允许在大多数字符串类型上使用 BINARY 关键字,用于指明所有针对该字段的运算是大小写敏感的,更多信息请参见 MySQL 官方文档。
这种方法使得设计者可以精确地控制每个字段是否大小写敏感。在许多系统的设计中,通常期望所有字段都是大小写敏感的,甚至大多数字段都是如此。MySQL 也提供了解决方案,这就要用到方法三。
3. 修改排序规则(COLLATE)
在 MySQL 中执行 show create table <tablename></tablename> 指令,可以看到一张表的建表语句,example 如下:
CREATE TABLE `table1` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`field1` text COLLATE utf8_general_ci NOT NULL COMMENT '字段1',
`field2` varchar(128) COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '字段2',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8_unicode_ci;大部分字段我们都能看懂,但是今天要看的是 COLLATE 关键字。这个值后面对应的 utf8_general_ci 是什么意思呢?下面我们就来了解一下。
COLLATE是用来做什么的?
使用 Navicat 开发的可能会比较眼熟,因为其中的选项中已经给出了答案:
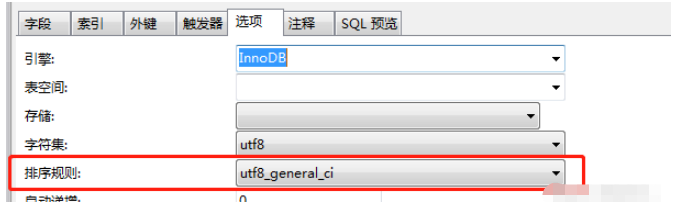
所谓 utf8_general_ci,其实是用来排序的规则。对于 MySQL 中那些字符类型的列,如VARCHAR,CHAR,TEXT 类型的列,都需要有一个 COLLATE 类型来告知 MySQL 如何对该列进行排序和比较。简而言之,COLLATE 会影响到 ORDER BY 语句的顺序,会影响到 WHERE 条件中大于小于号筛选出来的结果,会影响 DISTINCT、GROUP BY、HAVING 语句的查询结果。另外,MySQL 建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都会和 COLLATE 有关。
涉及字符串的各种运算其核心必然涉及到采用何种字符排序规则(COLLATE,也有翻译为"核对")。MySQL的字符串运算是否区分大小写,本质上取决于它所使用的COLLATE排序规则。
utf8_general_ci 是一个具体的 COLLATE 取值。每个具体的 COLLATE 都对应唯一的字符集,可以看出该 COLLATE 对应字符集为 utf8。而与大小写敏感问题相关的是其后缀 _ci,MySQL 官方文档对其的解释是 Case Ignore 的缩写,即大小写不敏感。由于 MySQL 将 utf8_general_ci 指定作为字符集 utf8 的默认 COLLATE,这也就导致文章开头所说的现象。与此同时,MySQL 也提供了其它的 COLLATE 取值选项,utf8_bin 就是大小写敏感的。事实上所有大小写敏感的 COLLATE 都以 _bin或 _cs 为后缀,前者是 Binary 的缩写,后者是 Case Sensitive
1. 쿼리 시 대소문자 구분 지정
🎜MySQL에서는 쿼리 시 대소문자 구분을 지정할 수 있습니다. 쿼리는 다음과 같습니다. 🎜MySQL 데이터베이스에서 위의 문제가 발견되는 경우는 시스템이 일정 기간 동안 실행된 상태이므로 두 번째 또는 세 번째 방법을 사용하는 데 드는 비용이 매우 높을 수 있습니다. 🎜🎜이 방법을 사용하면 가장 큰 장점은 빠르게 기능을 구현할 수 있다는 점입니다. 🎜🎜그러나 이 방법에도 큰 한계가 있습니다. 인덱스를 사용할 수 없기 때문에 쿼리 성능이 저하될 수 있습니다. 🎜🎜이유는 쿼리 필드에 대한 인덱스도 대소문자를 구분하지 않고 설정되기 때문에 이해하기 쉽습니다. 🎜🎜데이터 양이 크지 않거나 애플리케이션의 성능 손실을 신경쓰지 않는 한 방법 2 또는 3만 선택할 수 있습니다. 🎜2. 테이블 구조 정의 시 필드 대소문자 구분 지정
🎜테이블 생성 시 특정 필드 대소문자 구분을 지정합니다. 예는 다음과 같습니다. 🎜CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;🎜키워드
BINARY 이름 지정 필드는 대소문자를 구분합니다. 🎜🎜이렇게 하면 쿼리에 BINARY 키워드를 사용하지 않더라도 쿼리문에서는 대소문자를 구분합니다. 🎜🎜이를 기반으로 생성된 이름 관련 인덱스도 대소문자를 구분하므로 인덱스를 활용하여 성능을 향상시킬 수 있습니다. 🎜🎜MySQL에서는 대부분의 문자열 유형에서 BINARY 키워드를 사용할 수 있습니다. 이는 이 필드의 모든 작업이 대소문자를 구분함을 나타내는 데 사용됩니다. 자세한 내용은 MySQL 공식 문서를 참조하세요. 🎜🎜이 접근 방식을 통해 디자이너는 각 필드가 대소문자를 구분하는지 여부를 정확하게 제어할 수 있습니다. 많은 시스템 설계에서는 모든 필드 또는 대부분의 필드가 대소문자를 구분하는 것이 일반적입니다. MySQL은 세 번째 방법을 사용해야 하는 솔루션도 제공합니다. 🎜3. 대조 규칙 수정(COLLATE)
🎜MySQL에서show create table <tablename></tablename> 명령을 실행하면 테이블의 테이블 생성 문, 예를 볼 수 있습니다. 🎜CREATE TABLE table_name ( …… ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT = '表注释';🎜대부분의 필드를 이해할 수 있지만 오늘 살펴볼 것은 COLLATE 키워드입니다. 이 값에 해당하는
utf8_general_ci는 무엇을 의미하나요? 여기 우리가 알아보러 왔습니다. 🎜COLLATE는 어떤 용도로 사용되나요?
🎜Navicat을 사용하여 개발한 것들은 옵션에 답변이 제공되어 있으므로 익숙해 보일 수 있습니다: 🎜🎜 🎜🎜일명
🎜🎜일명 utf8_general_ci는 실제로 정렬에 사용되는 규칙입니다. VARCHAR, CHAR 및 TEXT 유형 열과 같은 MySQL의 문자 유형 열의 경우 COLLATE 유형은 MySQL에 열 정렬 및 비교 방법을 알려주는 데 필요합니다. 즉, COLLATE는 ORDER BY 문의 순서, WHERE 조건의 크거나 작은 기호 및 DISTINCT로 필터링된 결과에 영향을 미칩니다. , GROUP BY, HAVING 문의 쿼리 결과입니다. 또한 MySQL이 인덱스를 구축할 때 인덱스 열이 문자 유형인 경우 인덱스 생성에도 영향을 주지만 우리는 이러한 영향을 인식할 수 없습니다. 간단히 말해서, 문자 유형의 비교 또는 정렬과 관련된 모든 곳은 COLLATE와 관련됩니다. 🎜🎜문자열과 관련된 다양한 작업의 핵심에는 문자 정렬 규칙(COLLATE, "검사"라고도 번역됨)이 포함되어야 합니다. MySQL의 문자열 작업이 대소문자를 구분하는지 여부는 기본적으로 MySQL이 사용하는 COLLATE 데이터 정렬에 따라 다릅니다. 🎜🎜utf8_general_ci는 특정 COLLATE 값입니다. 각각의 특정 COLLATE는 고유한 문자 집합에 해당합니다. 이 COLLATE에 해당하는 문자 집합은 utf8임을 알 수 있습니다. 대소문자 구분 문제와 관련하여 접미사 _ci가 있습니다. 공식 MySQL 문서에서는 이를 Case Ignore의 약어로 설명합니다. 이는 대소문자를 구분하지 않음을 의미합니다. MySQL은 문자 집합 utf8의 기본 COLLATE로 utf8_general_ci를 지정하므로 이 역시 기사 시작 부분에서 언급한 현상으로 이어집니다. 동시에 MySQL은 다른 COLLATE 값 옵션도 제공하며 utf8_bin은 대소문자를 구분합니다. 실제로 모든 대소문자 구분 COLLATE에는 _bin 또는 _cs가 접미사로 붙습니다. 전자는 Binary의 약어이고 후자는 입니다. Sensitive의 대소문자 약어입니다. 🎜다양한 COLLATE의 차이점
COLLATE은 일반적으로 데이터 인코딩(CHARSET)과 관련이 있습니다. 일반적으로 각 CHARSET에는 지원하는 여러 COLLATE가 있으며 각 CHARSET은 하나의 COLLATE를 기본값으로 지정합니다. 예를 들어, Latin1 인코딩의 기본 COLLATE는 latin1_swedish_ci이고, GBK 인코딩의 기본 COLLATE는 gbk_chinese_ci이며, utf8mb4 인코딩의 기본값은 utf8mb4_general_ci입니다. >. latin1_swedish_ci,GBK 编码的默认 COLLATE 为 gbk_chinese_ci,utf8mb4 编码的默认值为 utf8mb4_general_ci。
这里顺便讲个题外话,MySQL 中有 utf8 和 utf8mb4 两种编码,在 MySQL 中请大家忘记 utf8,永远使用 utf8mb4。这是 MySQL 的一个遗留问题,MySQL 中的 utf8 最多只能支持 3bytes 长度的字符编码,对于一些需要占据 4bytes 的文字,MySQL 的 utf8 就不支持了,要使用 utf8mb4 才行。
很多 COLLATE 都带有 _ci 字样,这是 Case Insensitive 的缩写,即大小写无关,也就是说 "A" 和 "a" 在排序和比较的时候是一视同仁的。selection * from table1 where field1="a" 同样可以把 field1 为 "A" 的值选出来。与此同时,对于那些 _cs 后缀的 COLLATE,则是 Case Sensitive,即大小写敏感的。
在 MySQL 中使用 show collation 指令可以查看到 MySQL 所支持的所有 COLLATE。以 utf8mb4 为例,该编码所支持的所有 COLLATE 如下图所示。
图中我们能看到很多国家的语言自己的排序规则。在国内比较常用的是 utf8mb4_general_ci(默认)、utf8mb4_unicode_ci、utf8mb4_bin 这三个。我们来探究一下这三个的区别:
UTF8mb4_bin的比较方式是将所有字符作为二进制串,然后从最高位到最低位进行比较。所以很显然它是区分大小写的。
而 utf8mb4_unicode_ci 和 utf8mb4_general_ci 对于中文和英文来说,其实是没有任何区别的。对于我们开发的国内使用的系统来说,随便选哪个都行。只是对于某些西方国家的字母来说,utf8mb4_unicode_ci 会比 utf8mb4_general_ci 更符合他们的语言习惯一些,general 是 MySQL 一个比较老的标准了。例如,德语字母 "ß",在 utf8mb4_unicode_ci 中是等价于 "ss" 两个字母的(这是符合德国人习惯的做法),而在 utf8mb4_general_ci 中,它却和字母 "s"
utf8
을 잊어버리고 MySQL에서는 항상utf8mb4
를 사용하세요. 이는 MySQL의 레거시 문제입니다. MySQL의 utf8은 최대 3바이트 길이의 문자 인코딩만 지원할 수 있습니다. 4바이트를 차지해야 하는 일부 텍스트의 경우 MySQL의 utf8은 이를 지원하지 않습니다.많은 COLLATE에는 Case Insensitive의 약어인 _ci라는 단어, 즉 대소문자를 구분하지 않는 "A" 및 MySQL에서 지원하는 모든 COLLATE를 보려면 MySQL에서 "a"는 정렬 및 비교할 때 동일하게 처리됩니다. selection * from table1 where field1="a"는 field1의 값을 "A"로 선택할 수도 있습니다. 동시에 _cs 접미사가 있는 COLLATE의 경우 대소문자 구분, 즉 대소문자를 구분합니다. show collation 명령을 사용하세요. utf8mb4를 예로 들면, 이 인코딩이 지원하는 모든 COLLATE는 아래 그림과 같습니다.
그림에서 우리는 여러 나라 언어의 정렬 규칙을 볼 수 있습니다. 중국에서 일반적으로 사용되는 세 가지는 utf8mb4_general_ci(기본값), utf8mb4_unicode_ci 및 utf8mb4_bin입니다. 이 세 가지의 차이점을 살펴보겠습니다. UTF8mb4_bin의 비교 방법은 모든 문자를 이진 문자열로 처리한 다음 가장 높은 비트에서 가장 낮은 비트까지 비교하는 것입니다. 그러니 당연히 대소문자를 구분합니다. 실제로 중국어와 영어의 경우 utf8mb4_unicode_ci와 utf8mb4_general_ci 사이에는 차이가 없습니다. 우리가 가정용으로 개발한 시스템은 아무거나 선택하시면 됩니다. 그러나 일부 서구 국가의 문자에서는 utf8mb4_unicode_ci가 utf8mb4_general_ci보다 언어 습관에 더 가깝습니다. 일반은 MySQL의 오래된 표준입니다. 예를 들어, 독일어 문자 "ß"는 utf8mb4_unicode_ci의 두 문자 "ss"와 동일하며(이는 독일 습관과 일치함), utf8mb4_unicode_ci의 경우 utf8mb4_general_ci , 문자 "s"와 동일합니다. 그러나 두 인코딩 간의 미묘한 차이는 일반적인 개발에서는 인식하기 어렵습니다. 한발 물러서서 한두 글자가 잘못 정렬되어도 실제로 시스템에 치명적인 결과를 가져올 수 있습니까? 인터넷에서 발견된 다양한 게시물과 토론을 보면 utf8mb4_unicode_ci를 사용하는 것을 권장하는 사람들이 늘어나고 있지만 기본값을 사용하는 시스템에는 그다지 저항력이 없으며 큰 문제가 없다고 생각합니다. 결론: utf8mb4_unicode_ci를 사용하는 것이 좋습니다. 이미 utf8mb4_general_ci를 사용하고 있는 시스템의 경우 수정하는 데 시간을 들일 필요가 없습니다. 또 주목해야 할 점은 MySQL 8.0부터 MySQL의 기본 CHARSET이 더 이상 Latin1이 아니라 utf8mb4(참조 링크)로 변경되었으며 기본 COLLATE도 utf8mb4_0900_ai_ci로 변경되었다는 것입니다. utf8mb4_0900_ai_ci는 일반적으로 유니코드의 추가 하위 구분입니다. 0900은 유니코드 비교 알고리즘(유니코드 대조 알고리즘 버전)의 번호를 나타내며, ai는 e, è, é, ê와 같이 악센트를 구분하지 않음을 의미합니다. ;와 동일하게 취급됩니다. 관련 참조 링크 1, 관련 참조 링크 2COLLATE 설정 수준 및 우선 순위
- library
- ,
table
및 column - 의 세 가지 수준으로 지정할 수 있습니다. 함께 지정하면 우선순위 관계는 컬럼 > COLLATE 설정은 🎜인스턴스 수준🎜, 🎜라이브러리 수준🎜, 🎜테이블 수준🎜, 🎜열 수준🎜 및 🎜SQL 🎜에서 지정할 수 있습니다. 동시에 지정하는 경우 우선순위 관계는 SQL 사양 > 열 > 라이브러리 > 인스턴스 수준입니다. 🎜🎜🎜🎜인스턴스 수준 COLLATE 설정은 MySQL 구성 파일 또는 시작 명령의 collation_connection 시스템 변수입니다. 🎜🎜🎜🎜라이브러리 수준에서 COLLATE를 설정하는 명령문은 다음과 같습니다. 🎜
CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
如果库级别没有设置 CHARSET 和 COLLATE,则库级别默认的 CHARSET 和 COLLATE 使用实例级别的设置。在 MySQL 8.0 以下版本中,你如果什么都不修改,默认的 CHARSET 是 Latin1,默认的 COLLATE 是 latin1_swedish_ci。从 MySQL 8.0 开始,默认的 CHARSET 已经改为了 utf8mb4,默认的 COLLATE 改为了 utf8mb4_0900_ai_ci。
表级别的 COLLATE 设置,则是在 CREATE TABLE 的时候加上相关设置语句,例如:
CREATE TABLE table_name ( …… ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT = '表注释';
如果表级别没有设置 CHARSET 和 COLLATE,则表级别会继承库级别的 CHARSET 与 COLLATE。
列级别的设置,则在 CREATE TABLE 中声明列的时候指定,例如
CREATE TABLE ( `field1` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '字段1', …… ) ……
如果列级别没有设置 CHARSET 和 COLATE,则列级别会继承表级别的 CHARSET 与 COLLATE。
最后,你也可以在写 SQL 查询的时候显示声明 COLLATE 来覆盖任何库表列的 COLLATE 设置,不太常用,了解即可:
SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1; SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_unicode_ci;
如果全都显示设置了,那么优先级顺序是 SQL 语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置。
也就是说列上所指定的 COLLATE可以覆盖表上指定的 COLLATE,表上指定的 COLLATE 可以覆盖库级别的 COLLATE。如果没有指定,则继承下一级的设置。
即列上面没有指定 COLLATE,则该列的 COLLATE 和表上设置的一样。
위 내용은 MySQL에 저장된 데이터를 쿼리할 때 대문자와 소문자를 구별하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!