
GPT의 현재 상황을 드디어 누군가가 분명히 밝혔습니다! OpenAI의 최근 연설은 입소문이 났습니다. 머스크가 직접 뽑은 천재임에 틀림없습니다

- PHPz앞으로
- 2023-05-31 16:23:411277검색
Windows Copilot 출시 이후 연설을 통해 Microsoft Build 컨퍼런스의 인기가 촉발되었습니다.
전 Tesla AI 디렉터인 Andrej Karpathy는 자신의 연설에서 생각의 나무가 AlphaGo의 Monte Carlo Tree Search(MCTS)와 유사하다고 믿었습니다!
네티즌들은 다음과 같이 외쳤습니다: 이것은 대형 언어 모델과 GPT-4 모델을 사용하는 방법에 대한 가장 상세하고 흥미로운 가이드입니다!

또한 Karpathy는 훈련 및 데이터 확장으로 인해 LLAMA 65B가 "GPT-3 175B보다 훨씬 더 강력하다"고 밝혔으며 대규모 모델 익명 경기장 ChatBot 경기장을 소개했습니다.
ChatGPT 간의 Claude 점수 3.5와 ChatGPT 4 사이.

네티즌들은 Karpathy의 연설은 항상 훌륭하고 이번에도 내용은 언제나처럼 모두를 실망시키지 않았다고 말했습니다.
스피치와 함께 트위터 유저들이 그 스피치를 바탕으로 정리한 노트도 있습니다. 31개의 노트가 있고 좋아요 수가 3000개를 넘었습니다:
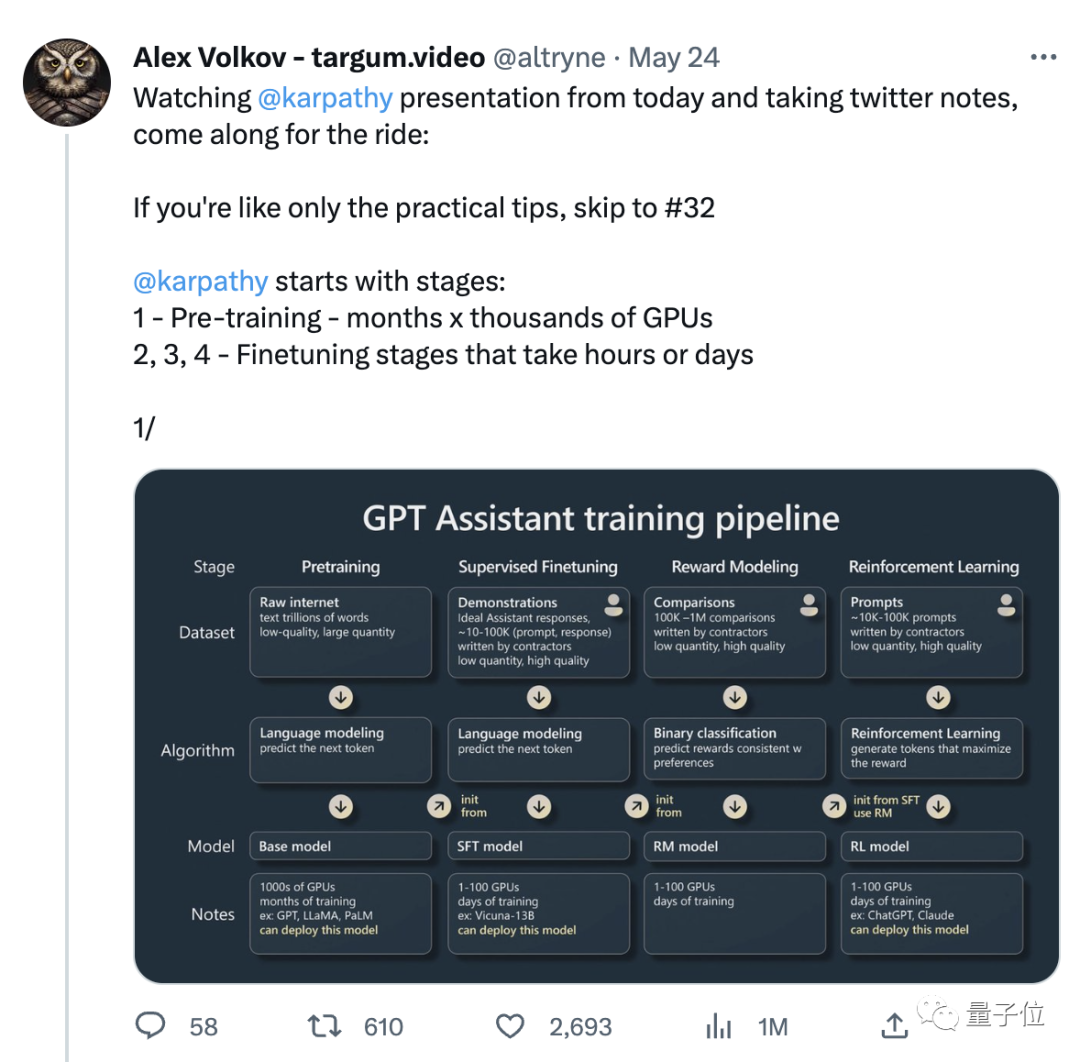
그래서 이 문단을 준비했습니다. 연설에서 많은 관심을 끌었던 구체적인 내용이 언급되었나요?
GPT 보조자를 훈련하는 방법은 무엇입니까?
Karpathy의 이번 연설은 크게 두 부분으로 나뉩니다.
1부에서는 'GPT 보조원'을 양성하는 방법에 대해 이야기했습니다.
Karpathy는 주로 AI 어시스턴트의 4가지 훈련 단계인
사전 훈련, 감독된 미세 조정, 보상 모델링 및 강화 학습에 대해 이야기합니다.
각 단계에는 데이터 세트가 필요합니다.

사전 학습 단계에서는 대량의 데이터 세트를 수집하기 위해 대량의 컴퓨팅 리소스를 사용해야 합니다. 기본 모델은 감독되지 않은 대규모 데이터 세트에 대해 학습됩니다.
Karpathy는 보완을 위해 더 많은 예제를 사용했습니다.
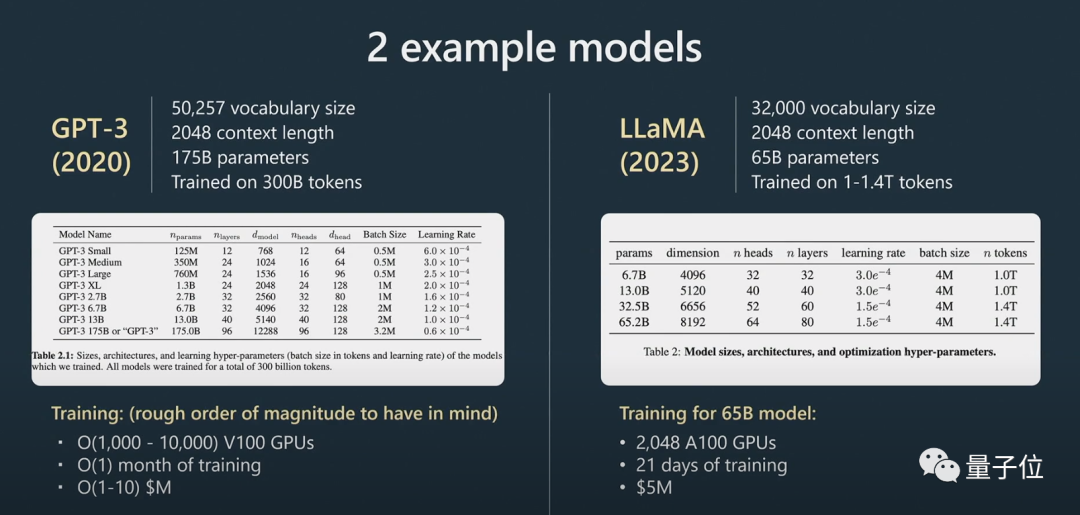
그런 다음 미세 조정 단계에 들어갑니다.
더 작은 지도 데이터 세트를 사용하고 지도 학습을 통해 이 기본 모델을 미세 조정하여 질문에 답할 수 있는 보조 모델을 만듭니다.
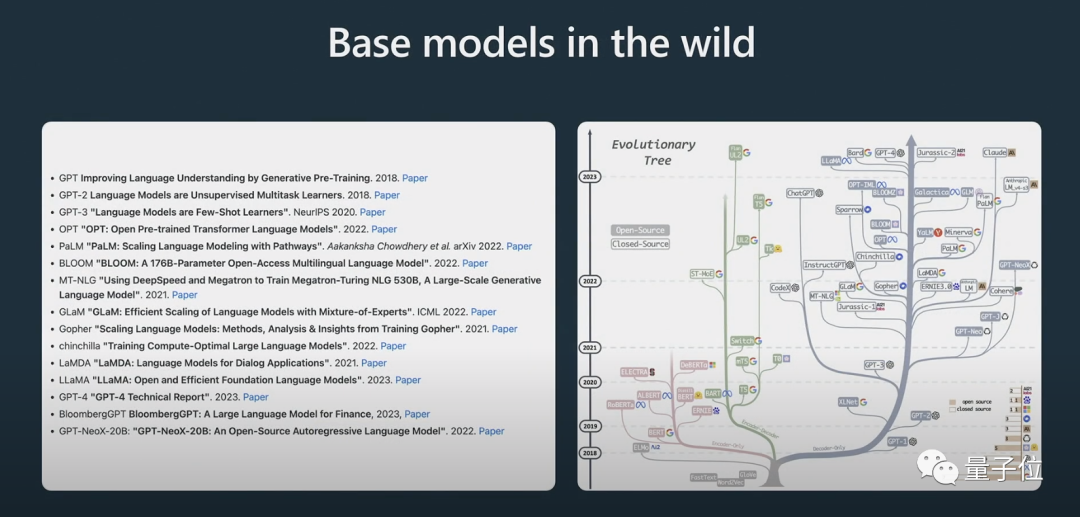
그는 또한 일부 모델의 진화 과정을 보여주었고 많은 사람들이 이전에 위의 "진화 나무" 그림을 본 적이 있을 것이라고 생각합니다.
Karpathy는 현재 최고의 오픈 소스 모델이 Meta의 LLaMA 시리즈라고 믿습니다(OpenAI는 GPT-4에 대해 아무것도 오픈 소스화하지 않았기 때문입니다).
여기서 분명히 짚고 넘어가야 할 점은 기본 모델은 보조 모델이 아니라는 점입니다.
기본 모델은 문제를 해결할 수 있는 능력이 있지만, 제공하는 답변은 신뢰할 수 없는 반면, 보조 모델은 신뢰할 수 있는 답변을 제공할 수 있습니다. 감독되고 미세 조정된 보조 모델은 기본 모델을 기반으로 학습되며 응답 생성 및 텍스트 구조 이해 성능이 기본 모델보다 우수합니다.
강화 학습은 언어 모델을 훈련할 때 또 다른 핵심 프로세스입니다.
훈련 과정에서는 수동으로 주석이 달린 고품질 데이터가 사용되며, 성능 향상을 위해 보상 모델링 방식으로 손실 함수가 생성됩니다. 강화 훈련은 긍정적 표시 확률을 높이고 부정적 표시 확률을 감소시켜 달성할 수 있습니다.
창의적인 작업에 있어 AI 모델을 개선하려면 인간의 판단이 매우 중요하며, 인간의 피드백을 통합하여 모델을 더욱 효과적으로 훈련할 수 있습니다.
인간 피드백을 통한 강화 학습 후 RLHF 모델을 얻을 수 있습니다.
모델이 훈련된 후 다음 단계는 이러한 모델을 효과적으로 사용하여 문제를 해결하는 방법입니다.
모델을 더 잘 사용하는 방법은 무엇인가요?
2부에서 Karpathy는 프롬프트 전략, 미세 조정, 빠르게 진화하는 도구 생태계 및 향후 확장에 대해 논의합니다.
Karpathy는 설명하기 위해 또 다른 구체적인 예를 제시했습니다.

글을 쓸 때 우리는 표현이 정확한지 고려하는 것을 포함하여 많은 정신적 활동을 수행해야 합니다. GPT의 경우 이는 태그가 지정되는 일련의 토큰일 뿐입니다.
그리고 즉시는 이러한 인지적 격차를 메울 수 있습니다.
Karpathy는 Thought Chain 프롬프트가 작동하는 방식을 자세히 설명합니다.
추론 문제의 경우 Transformer가 자연어 처리에서 더 나은 성능을 발휘하도록 하려면 매우 복잡한 문제를 직접적으로 던지기보다는 단계별로 정보를 처리하도록 해야 합니다.
몇 가지 예를 들면 이 예의 템플릿을 모방하게 되어 최종 결과가 더 좋아질 것입니다.

모델은 생성된 콘텐츠가 잘못된 경우에만 질문에 답할 수 있습니다.
확인을 요청하지 않으면 자체적으로 확인하지 않습니다.
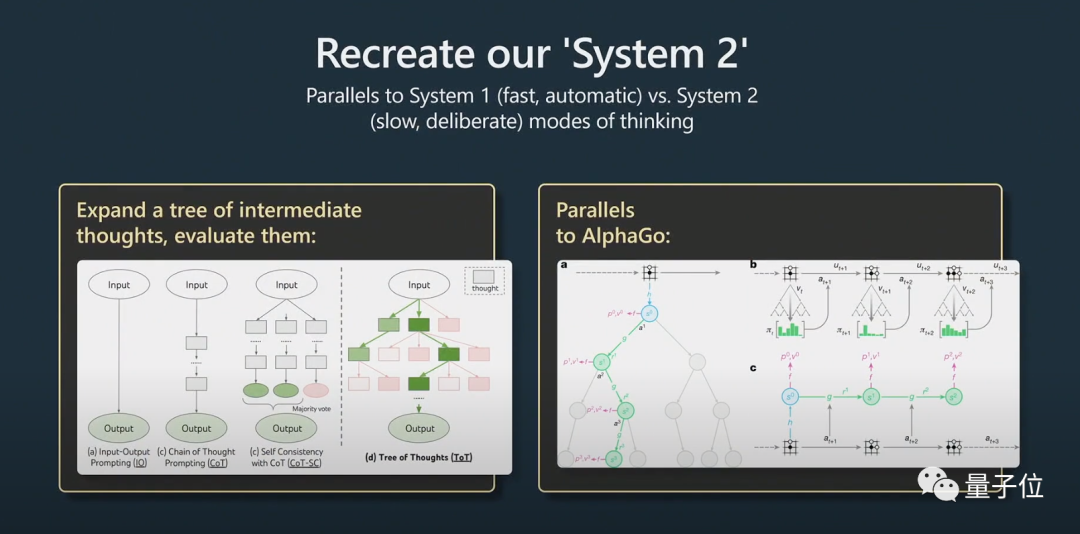
이것은 System1 및 System2의 문제와 관련이 있습니다.
노벨상 수상자 Daniel Kahneman은 "Thinking Fast and Slow"에서 인간의 인지 시스템이 System1과 System2라는 두 개의 하위 시스템으로 구성되어 있다고 제안했습니다. System1은 주로 직관에 의존하는 반면 System2는 논리적 분석 시스템입니다.
일반인의 관점에서 보면 System1은 빠르고 자동으로 생성되는 프로세스인 반면 System2는 세심하게 고려된 부분입니다.
이 내용은 최근 인기 논문 "생각의 나무"에서도 언급되었습니다.

사려 깊다는 것은 단순히 질문에 대한 답변을 제공하는 것이 아니라 Python 글루 코드와 함께 사용하여 여러 프롬프트를 함께 묶는 프롬프트와 비슷합니다. 힌트의 크기를 조정하려면 모델이 여러 힌트를 유지하고 트리 검색 알고리즘을 수행해야 합니다.
Karpathy는 이 아이디어가 AlphaGo와 매우 유사하다고 믿습니다.
AlphaGo가 바둑을 플레이할 때 다음 말을 어디에 배치할지 고려해야 합니다. 처음에는 인간을 모방하여 배웠습니다.
이 외에도 몬테카를로 트리 검색을 구현하여 여러 잠재적 전략으로 결과를 얻습니다. 가능한 많은 동작을 평가하고 더 나은 동작만 유지합니다. 이건 알파고와 어느 정도 비슷하다고 생각합니다.
이와 관련하여 Karpathy는 AutoGPT에 대해서도 언급했습니다.
현재 효과가 그다지 좋지 않다고 생각하며 실제 적용에는 권장하지 않습니다. 나는 우리가 시간이 지남에 따라 진화하는 것을 배울 수 있다고 생각합니다.

두 번째로 또 다른 작은 비결은 Enhanced Generation(Agumented Generation 검색)과 효과적인 팁을 검색하는 것입니다.
창 컨텍스트의 내용은 런타임 시 변환기의 작업 메모리입니다. 작업 관련 정보를 컨텍스트에 추가할 수 있으면 이 정보에 즉시 액세스할 수 있으므로 성능이 매우 좋습니다.
간단히 말하면, 모델에 효율적으로 접근할 수 있도록 관련 데이터를 색인화할 수 있다는 뜻입니다.
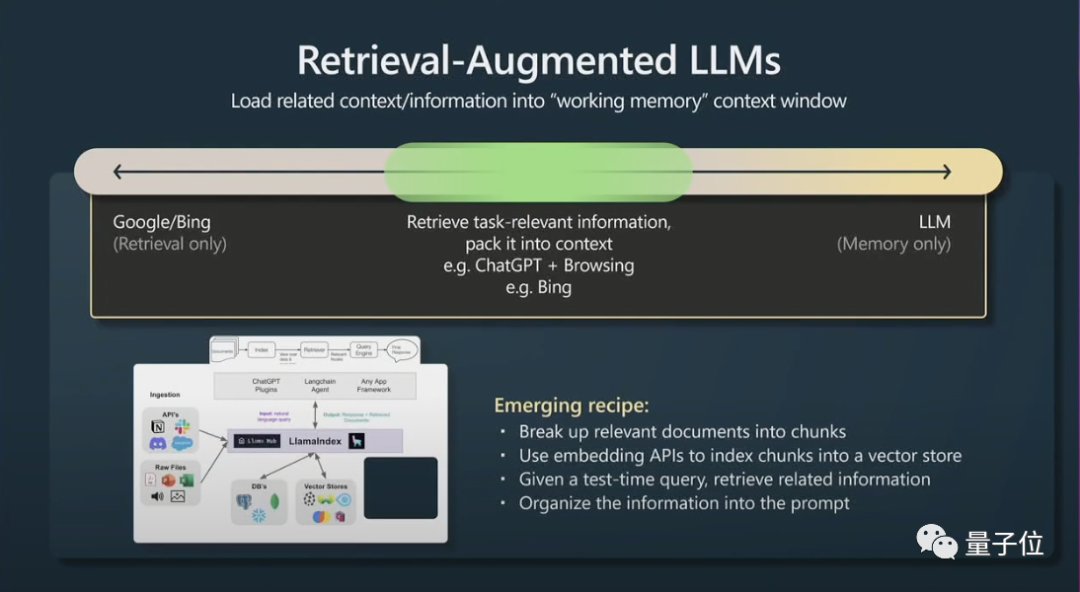
Transformer는 참조할 기본 파일도 있으면 더 나은 성능을 발휘합니다.
마지막으로 Karpathy는 대규모 언어 모델의 제약 조건 프롬프트 및 미세 조정에 대해 간략하게 설명했습니다.
대규모 언어 모델은 제약 조건 힌트와 미세 조정을 통해 개선될 수 있습니다. 제약 조건 힌트는 대규모 언어 모델의 출력에 템플릿을 적용하는 동시에 미세 조정을 통해 모델의 가중치를 조정하여 성능을 향상시킵니다.
위험도가 낮은 애플리케이션에서는 대규모 언어 모델을 사용하고 항상 인간 감독과 결합하여 영감과 조언의 원천으로 취급하고 완전히 자율적인 에이전트로 만들기보다는 부조종사를 고려하는 것이 좋습니다.
Andrej Karpathy 소개

Andrej Karpathy 박사의 졸업 후 첫 번째 직업은 OpenAI에서 컴퓨터 비전을 공부하는 것이었습니다.
나중에 OpenAI의 공동 창립자 중 한 명인 Musk는 Karpathy와 사랑에 빠졌고 그를 Tesla에 고용했습니다. 이 문제를 두고 머스크와 OpenAI가 대립했고 머스크는 결국 제외됐다. Karpathy는 Tesla의 Autopilot, FSD 및 기타 프로젝트를 담당하고 있습니다.
Karpathy는 Tesla를 떠난 지 7개월 만인 올해 2월, 다시 OpenAI에 합류했습니다.
최근 그는 오픈 소스 대형 언어 모델 생태계 개발에 매우 관심이 있다고 트윗했는데, 이는 마치 초기 캄브리아기 폭발의 징후와도 같습니다.
포털:
[1]https://www.youtube.com/watch?v=xO73EUwSegU(음성 영상)
[2]https://arxiv . org/PDF/2305.10601.pdf ("생각의 나무" 논문)
참조 링크:
[1] https://twitter.com/altryne/status/16612367888832896
[ 2 ]https://www.reddit.com/r/MachineLearning/comments/13qrtek/n_state_of_gpt_by_andrej_karpathy_in_msbuild_2023/
[3]https://www.wisdominanutshell.academy/state-of-gpt/
위 내용은 GPT의 현재 상황을 드디어 누군가가 분명히 밝혔습니다! OpenAI의 최근 연설은 입소문이 났습니다. 머스크가 직접 뽑은 천재임에 틀림없습니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!