
대형 모델 지식이 아웃되면 어떻게 해야 하나요? Zhejiang University 팀은 대형 모델의 매개변수를 업데이트하는 방법, 즉 모델 편집 방법을 탐구합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-30 22:11:091395검색
Xi Xiaoyao 과학 기술 토크 원저자 | Xiaoxi, Python
대형 모델의 거대한 크기 뒤에는 "대형 모델을 어떻게 업데이트해야 할까요?"라는 직관적인 질문이 있습니다.
대형 모델의 엄청난 컴퓨팅 오버헤드에서 모델 모델 지식을 업데이트하는 것은 단순한 "학습 작업"이 아닙니다. 이상적으로는 전 세계의 다양한 상황의 복잡한 변화로 인해 대형 모델이 언제 어디서나 시대를 따라잡아야 하지만 새로운 대형 모델을 학습하는 계산이 필요합니다. 따라서 다른 입력에 영향을 주지 않고 특정 영역의 모델 데이터를 효과적으로 변경하기 위한 새로운 개념의 "모델 편집"이 등장했습니다.
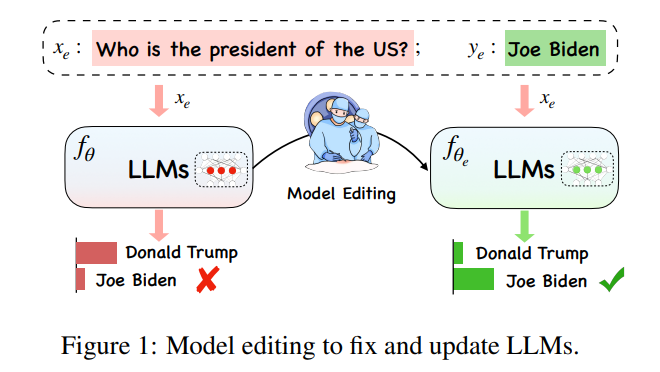

그 중 는 의 범위를 넘어서는 영역을 나타내는 의 "유효한 이웃"을 나타냅니다. 편집된 모델은 신뢰성(Reliability), 보편성(Universality), 지역성(Locality) 세 가지를 만족해야 하며, 신뢰성이란 편집된 모델의 평균 정확도로 판단할 수 있는 사전 편집된 모델의 오류 사례를 정확하게 출력할 수 있어야 함을 의미합니다. 측정, 보편성은 모델이 "유효한 이웃"에 대해 올바른 출력을 제공할 수 있어야 함을 의미합니다. 모델은 편집 범위를 벗어난 예에서도 사전 편집 정확도를 유지해야 하며 평균을 별도로 측정하여 특성화할 수 있습니다. 편집 전후의 정확도는 아래 그림과 같이 "트럼프" 편집 위치에서 다른 공개 특성을 변경해서는 안 됩니다. 동시에, "대통령"과 유사한 특성을 가지고 있음에도 불구하고 "국무부 장관"과 같은 다른 기관은 영향을 받아서는 안 됩니다.
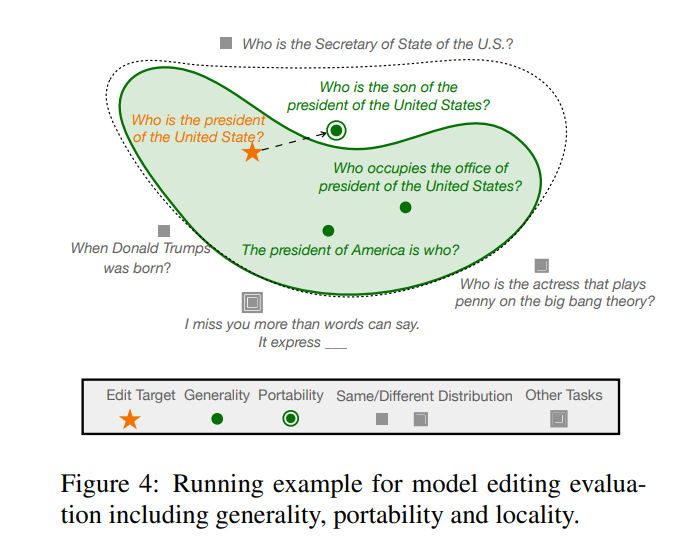
오늘 소개된 저장대학교의 논문은 대형 모델의 관점에서 대형 모델 시대의 모델 편집의 문제점과 방법 및 미래를 자세히 설명하고 새로운 벤치마크를 구축합니다. 평가 지표는 기존 기술을 보다 포괄적으로 평가하고 방법 선택에 대한 의미 있는 의사 결정 제안과 통찰력을 커뮤니티에 제공하는 데 도움이 됩니다.
논문 제목: 대규모 언어 모델 편집: 문제, 방법 및 기회
논문 링크: https://arxiv .org/pdf/2305.13172.pdf
Mainstream method
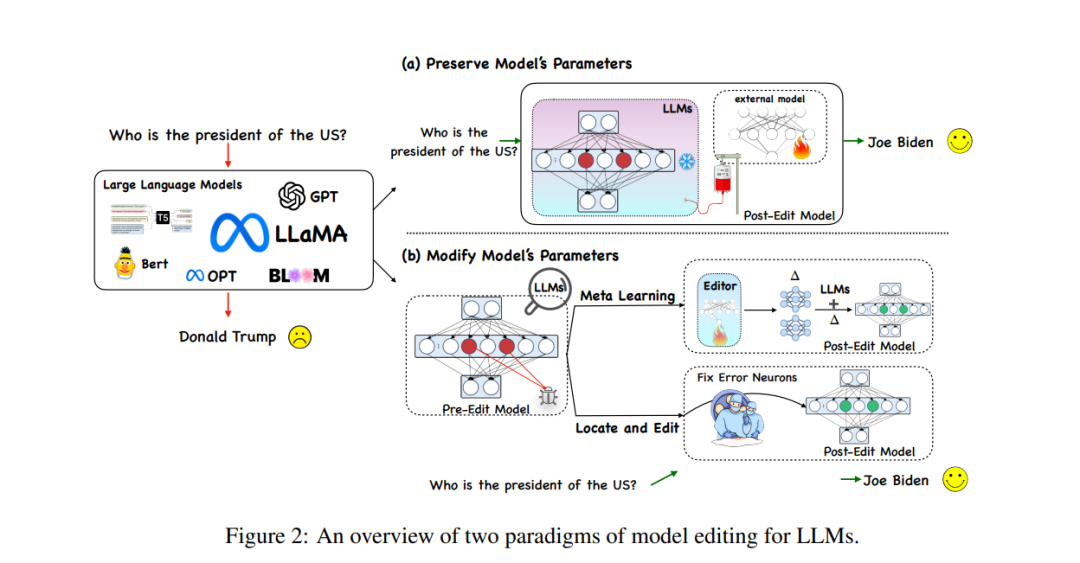
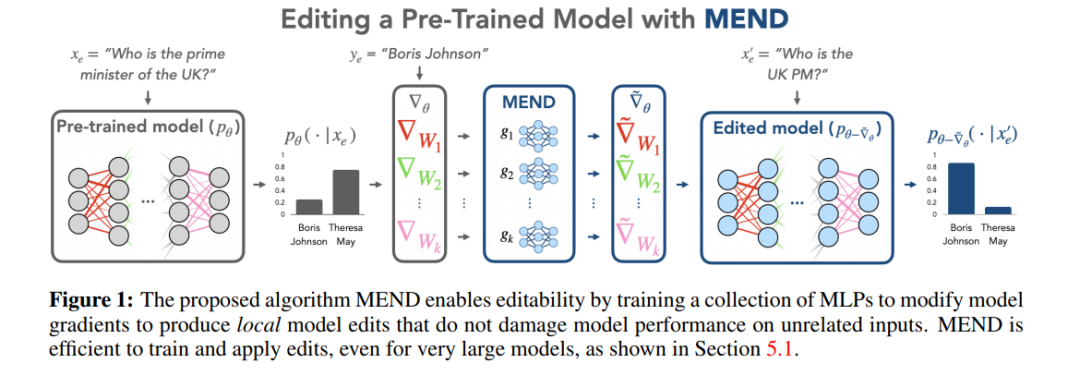
현재 대규모 언어 모델(LLM)의 모델 편집 방법은 아래 그림과 같이 크게 두 가지 유형의 패러다임으로 나누어집니다. ) 아래에서는 원래 모델 매개변수를 변경하지 않은 채 추가 매개변수를 사용하고, 모델의 내부 매개변수를 아래 그림 (b)와 같이 수정합니다.
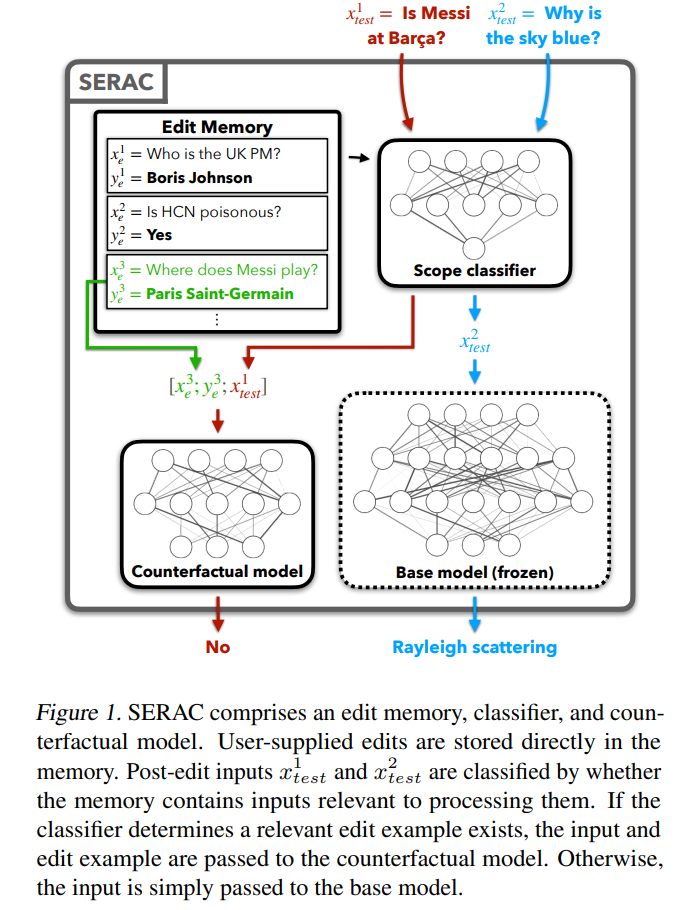
먼저 매개변수를 추가하는 비교적 간단한 방법을 살펴보겠습니다. 이 방법은 메모리 기반 모델 편집 방법이라고도 합니다. 대표적인 방법은 "모델 편집"을 제안하는 Mitchell의 논문에서 처음 등장했습니다. 핵심 아이디어는 모델의 원래 매개변수를 변경하지 않고 유지하고 독립적인 매개변수 세트를 통해 수정된 사실을 재처리하는 것입니다. 특히 이 유형의 방법은 일반적으로 새 입력이 "재편집된" 내에 있는지 확인하기 위해 먼저 "범위 분류자"를 추가합니다. " 사실 범위 내에 속하는 경우 입력은 독립적인 매개변수 세트를 사용하여 처리되므로 캐시의 "정답"에 더 높은 선택 확률을 제공합니다. SERAC를 기반으로 T-Patcher와 CaliNET은 추가 모델을 연결하는 대신 PLM의 피드포워드 모듈에 추가 훈련 가능한 매개변수를 도입하여 모델 편집 효과를 달성합니다.
또 다른 주요 방법인 원본 모델의 매개변수를 수정하는 방법은 주로 Δ 행렬을 사용하여 모델의 일부 매개변수를 업데이트하는 방법으로, 구체적으로 매개변수를 수정하는 방법은 "찾은 후 편집"으로 나눌 수 있습니다. 및 메타 학습 방법에는 이름에서 알 수 있듯이 두 가지 유형이 있습니다. Locate-Then-Edit 방법은 먼저 모델에서 주요 영향을 미치는 매개 변수를 찾은 다음 찾은 모델 매개 변수를 수정하여 모델 편집을 구현합니다. 방법은 KN(Knowledge Neuron 방법)입니다. 주요 영향 매개변수는 모델에서 "지식 뉴런"을 식별하여 결정되며, ROME이라는 또 다른 방법은 KN과 유사한 아이디어를 가지고 있습니다. 인과관계 중개 분석을 통해 편집 영역에 추가로 MEMIT 방식을 사용하여 일련의 편집 설명을 업데이트할 수 있습니다. 이 유형의 방법의 가장 큰 문제점은 일반적으로 사실적 지식의 지역성 가정에 의존한다는 것입니다. 그러나 이 가정은 널리 검증되지 않았으며 많은 매개변수를 편집하면 예상치 못한 결과가 발생할 수 있습니다.
메타 학습 방법은 Locate-Then-Edit 방법과 다릅니다. 메타 학습 방법은 하이퍼 네트워크 방법을 사용하며 하이퍼 네트워크를 사용하여 다른 네트워크에 대한 가중치를 생성합니다. 구체적으로 저자는 양방향 LSTM은 각 데이터 포인트가 모델 가중치에 가져오는 업데이트를 예측하여 편집 대상 지식의 제한된 최적화를 달성합니다. 이러한 유형의 지식 편집 방법은 LLM의 엄청난 양의 매개변수로 인해 적용하기 어렵습니다. 따라서 Mitchell 등은 단일 편집 설명으로 LLM을 효과적으로 업데이트할 수 있도록 MEND(Model Editor Networks with Gradient Decomposition)를 제안했습니다. 업데이트 이 방법은 주로 그라디언트의 낮은 순위 분해를 사용하여 대규모 모델의 그라디언트를 미세 조정함으로써 LLM에 대한 리소스 업데이트를 최소화합니다. 찾기 후 편집 방법과 달리 메타 학습 방법은 일반적으로 시간이 더 오래 걸리고 메모리 비용도 더 많이 소모합니다.
방법 평가
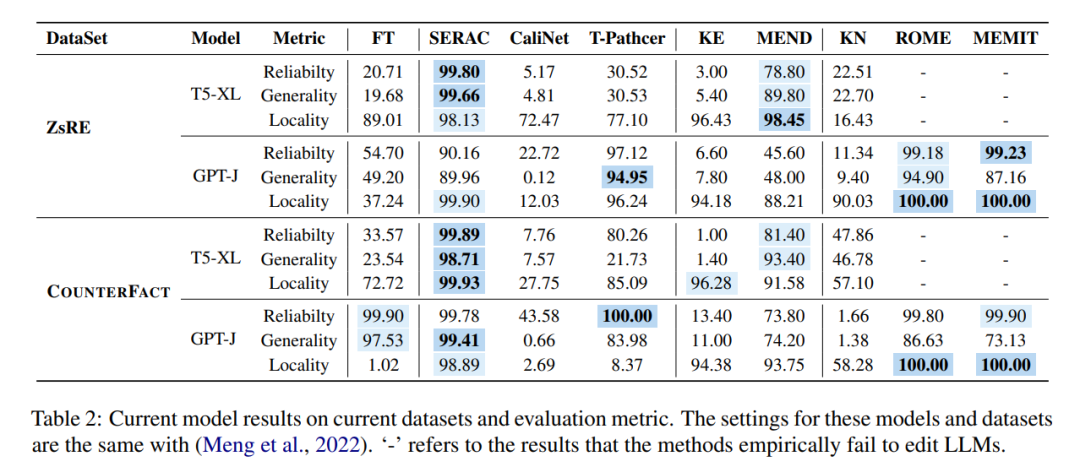
이러한 다양한 방법은 모델 편집 ZsRE(질문 및 답변 데이터 세트, 역번역으로 생성된 질문을 사용하여 유효한 필드로 다시 작성)와 COUNTERFACT(반사실 데이터 세트)의 두 가지 주류 데이터 세트에 사용됩니다. , 대상 엔터티를 유효한 필드로 대체)로 변환하여 실험은 아래 그림과 같이 주로 비교적 큰 규모의 두 LLM T5-XL(3B) 및 GPT-J(6B)에 중점을 두고 수행되었습니다. 프로세서는 모델 성능, 추론 속도 및 저장 공간 간의 균형을 유지해야 합니다.
첫 번째 열의 미세 조정(FT) 결과를 비교하면 SERAC와 ROME이 ZsRE 및 COUNTERFACT 데이터세트에서 좋은 성능을 보이는 것을 알 수 있으며, 특히 SERAC는 여러 평가 지표에서 90% 이상의 결과를 얻습니다. MEMIT 다재다능함은 SERAC, ROME만큼 좋지는 않지만 신뢰성과 지역성 측면에서 좋은 성능을 발휘합니다. T-Patcher 방식은 COUNTERFACT 데이터셋에서는 신뢰도와 지역성이 매우 높으나, GPT-J에서는 신뢰도와 일반성이 뛰어나지만 지역성에서는 성능이 떨어진다. KE, CaliNET 및 KN의 성능이 "소형 모델"에서 달성한 우수한 성능과 비교하면 실험을 통해 이러한 방법이 대형 모델 환경에 잘 적용되지 않는다는 점을 입증할 수 있습니다.
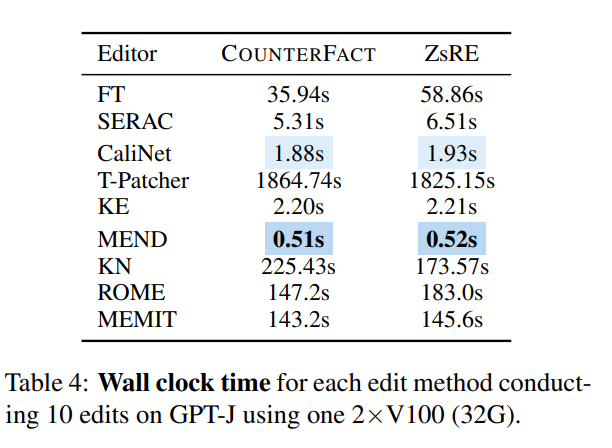
시간 관점에서 볼 때 네트워크가 훈련되면 KE와 MEND는 매우 잘 수행되는 반면 T-Patcher와 같은 방법은 시간이 너무 많이 걸립니다.
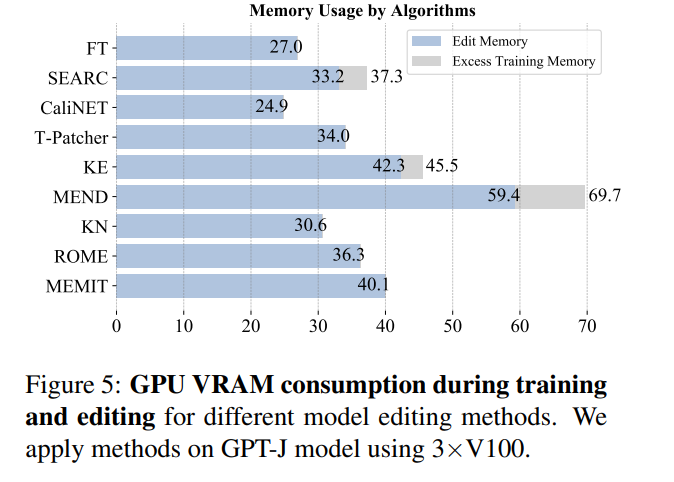
메모리 소비를 살펴보면 대부분의 방법이 메모리를 소비합니다. 크기는 동일하지만 추가 매개변수를 도입하는 방법은 추가 메모리 오버헤드를 부담합니다.
동시에 일반적으로 모델 편집 작업에서는 일괄 입력 편집 정보와 순차 입력 편집도 고려해야 합니다. 즉, 여러 팩트 정보를 한 번에 업데이트하고 여러 팩트 정보를 순차적으로 업데이트하는 것입니다. 일괄 입력 편집 정보의 전반적인 모델 효과는 아래 그림과 같이 MEMIT가 동시에 10,000개 이상의 정보를 편집할 수 있음을 알 수 있습니다. MEND와 SERAC의 성능이 좋지 않은 반면 두 지표의 성능은 안정적으로 유지됩니다.
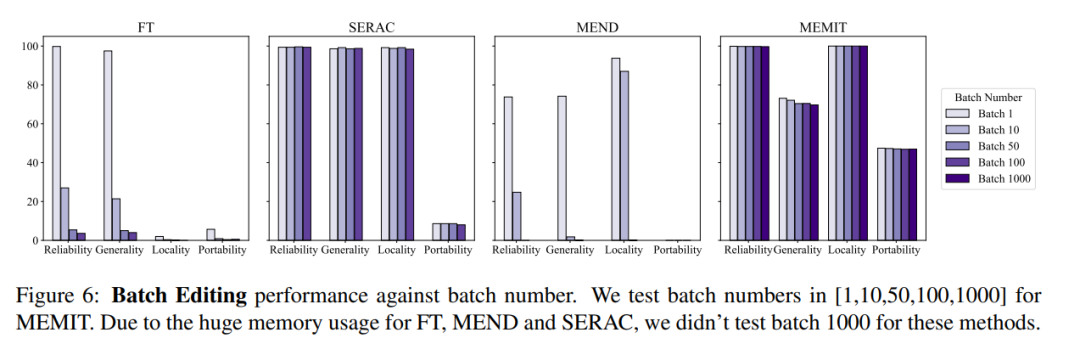
순차 입력 측면에서 SERAC와 T-Patcher는 ROME, MEMIT, MEND 모두 특정 횟수의 입력 이후 모델 성능이 급격히 저하되는 현상을 경험했습니다.
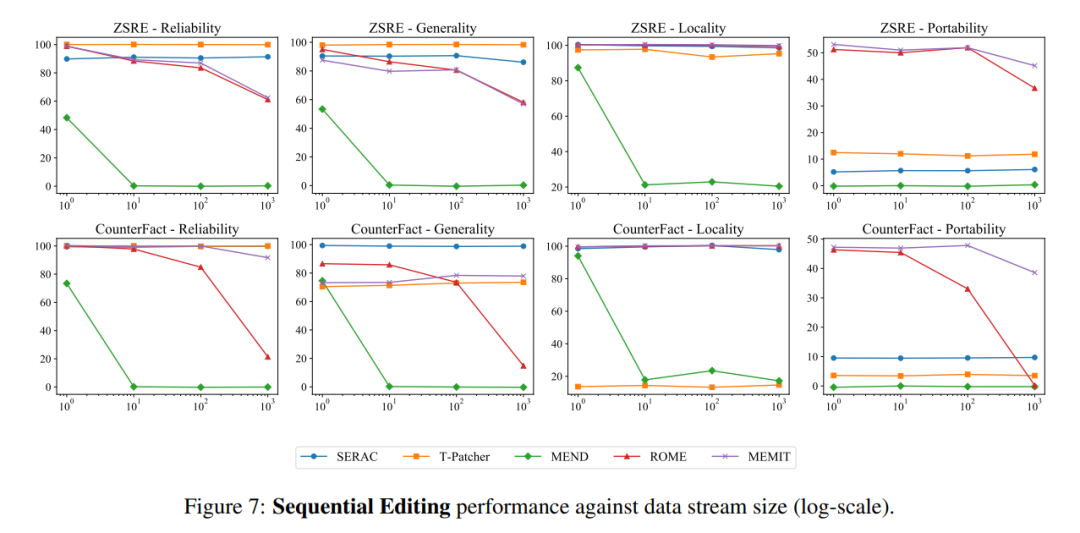
마지막으로 저자는 연구에 따르면 이러한 데이터 세트의 현재 구성 및 평가 지표는 주로 문장 표현의 변경에만 초점을 맞추고 모델 편집자가 많은 관련 논리적 사실에 대해 적용한 변경 사항은 다루지 않습니다. 예를 들어 "Watts Humphrey가 어느 대학에 다녔는지. " "답은 트리니티 칼리지에서 미시간 대학교로 바뀌었습니다. 분명히 모델에게 "와츠 험프리가 대학에 살았던 도시는 어디입니까?"라고 묻는다면 이상적인 모델은 하트포드 대신 앤아버라고 대답해야 하므로 논문 작성자는 세 가지 평가 지표를 바탕으로 지식 전달에서 편집된 모델의 효율성을 측정하기 위해 "이식성" 지표가 도입되었습니다.
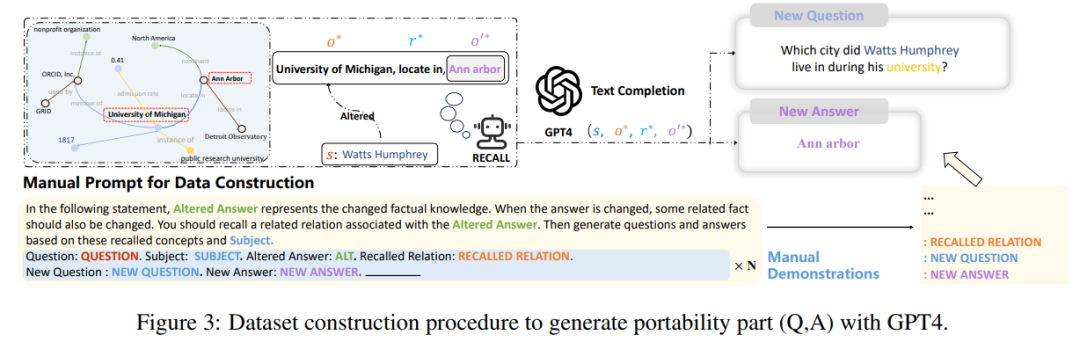
이를 위해 저자는 GPT-4를 사용하여 원래 질문에 대한 답변을 입력으로 변경하여 새로운 데이터 세트를 구성했습니다. 모델이 올바르게 출력될 수 있다면 편집된 모델에 "이식성"이 있음을 증명합니다. 이 방법에 따라 논문에서는 아래 그림과 같이 여러 기존 방법의 이식성 점수를 테스트했습니다.
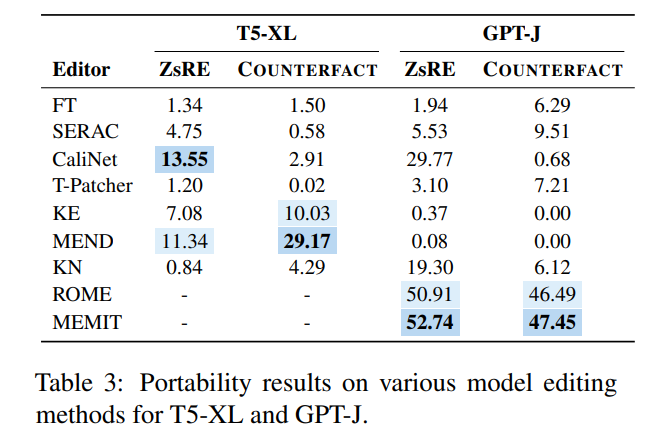
거의 대부분의 모델 편집 방법이 이식성 측면에서 이상적이지 않다는 것을 알 수 있습니다. 한때 좋은 성능을 발휘했던 SERAC의 이식성 정확도는 10% 미만이고, 상대적으로 가장 좋은 ROME과 MEMIT는 기껏해야 50% 정도에 불과해 현재의 모델 편집 방법으로는 편집된 모델의 확장과 홍보가 거의 어렵다는 것을 알 수 있습니다. 지식과 모델 편집에는 아직 갈 길이 멉니다.
논의와 미래
어떤 의미에서 모델 편집 프리셋의 문제는 앞으로 소위 "빅 모델 시대"에 큰 잠재력을 가지고 있습니다. 모델 지식이 저장됩니다." "모델 편집 작업이 어떻게 다른 모듈의 출력에 영향을 미치지 않을 수 있습니까?" 그리고 일련의 매우 어려운 질문입니다. 한편, 모델의 "오래된" 문제를 해결하기 위해 모델을 "편집"하도록 하는 것 외에도 모델 편집이든 민감한 지식이든 모델을 "평생 학습"하고 "잊어버리게" 하는 또 다른 아이디어가 있습니다. 모델 평생 학습, 이러한 연구는 LLM의 보안 및 개인 정보 보호 문제에 의미 있는 기여를 할 것입니다.
위 내용은 대형 모델 지식이 아웃되면 어떻게 해야 하나요? Zhejiang University 팀은 대형 모델의 매개변수를 업데이트하는 방법, 즉 모델 편집 방법을 탐구합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!