
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL에서 윈도우 기능을 사용하는 방법
MySQL에서 윈도우 기능을 사용하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-30 15:10:362981검색
(1) 윈도잉 기능의 정의
윈도우 기능은 OLAP(Online Analytical Process, 온라인 분석 처리)라고도 하며, 주로 데이터를 실시간으로 분석하고 처리하는 데 사용됩니다. MySQL 버전 8.0 이전에는 윈도잉 기능이 지원되지 않았으나, 이번 버전부터 윈도잉 기능이 지원됩니다.
# 开窗函数语法 func_name(<parameter>) OVER([PARTITION BY <part_by_condition>] [ORDER BY <order_by_list> ASC|DESC])
Window 함수 명령문 분석:
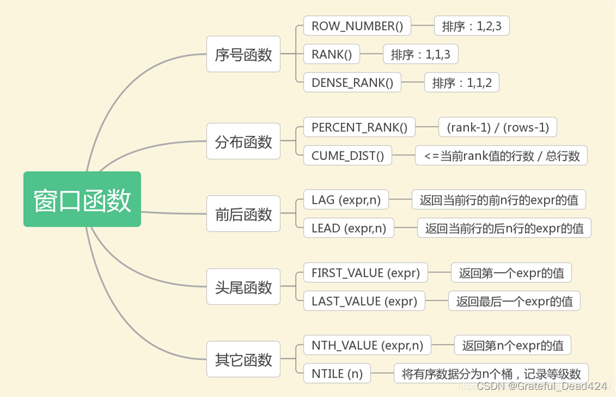
함수는 두 부분으로 나뉘며, 한 부분은 함수 이름이고, 창 함수의 수는 상대적으로 적으며, 총 11개의 창 함수 + 집계 함수만 있습니다(모든 집계 함수는 창 기능 기능으로 사용됨). 함수의 성격에 따라 매개변수를 작성해야 하는 경우도 있고 그렇지 않은 경우도 있습니다.
다른 부분은 over()를 작성해야 합니다. 내부 매개변수는 모두 선택사항이며 필요에 따라 선택적으로 사용할 수 있습니다.
첫 번째 매개변수는 + 필드 기준 파티션입니다. 이 필드는 데이터 세트를 여러 부분으로 나눕니다
두 번째 매개변수는 + 필드 기준 순서입니다. 각 창의 데이터는 이 필드에 따라 오름차순 또는 내림차순으로 정렬됩니다.
창 기능 및 그룹화 aggregation function 비교적 유사하며, 필드를 지정하여 데이터를 여러 부분으로 나눈다는 차이점이 있습니다.
SQL 표준에서는 모든 집계 함수를 윈도우 함수로 사용할 수 있으며, OVER 키워드를 사용하여 윈도우 함수를 구분합니다. 그리고 집계 함수.
Aggregation 함수는 그룹당 하나의 값만 반환하는 반면, windowing 함수는 그룹당 여러 값을 반환할 수 있습니다.
이 11가지 윈도우 함수 중 실제 작업에서 가장 많이 사용되는 정렬 함수는 ROW_NUMBER(), RANK(), DENSE_RANK() 3가지입니다. 간단한 데이터 세트를 통해 이 세 가지 윈도우 기능을 배워보겠습니다.
# 首先创建虚拟的业务员销售数据 CREATE TABLE Sales ( idate date, iname char(2), sales int ); # 向表中插入数据 INSERT INTO Sales VALUES ('2021/1/1', '丁一', 200), ('2021/2/1', '丁一', 180), ('2021/2/1', '李四', 100), ('2021/3/1', '李四', 150), ('2021/2/1', '刘猛', 180), ('2021/3/1', '刘猛', 150), ('2021/1/1', '王二', 200), ('2021/2/1', '王二', 180), ('2021/3/1', '王二', 300), ('2021/1/1', '张三', 300), ('2021/2/1', '张三', 280), ('2021/3/1', '张三', 280); # 数据查询 SELECT * FROM Sales; # 查询各月中销售业绩最差的业务员 SELECT month(idate),iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as sales_order FROM Sales; SELECT * FROM (SELECT month(idate),iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as sales_order FROM Sales) as t WHERE sales_order=1;

# ROW_NUMBER()、RANK()、DENSE_RANK()的区别 SELECT * FROM (SELECT month(idate) as imonth,iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as row_order, RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as rank_order, DENSE_RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as dense_order FROM Sales) as t;
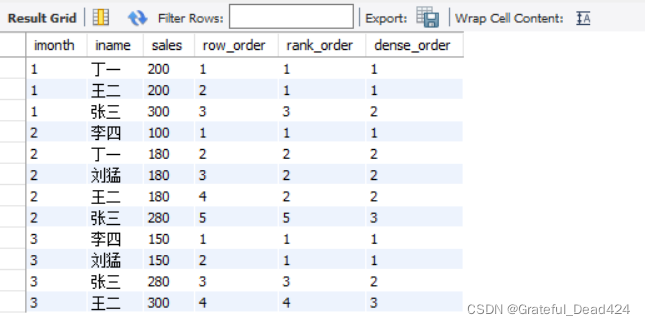
ROW_NUMBER(): 순차 정렬——1, 2, 3
RANK(): 병렬 정렬, 반복되는 일련 번호 건너뛰기——1, 1, 3
DENSE_RANK(): 병렬 반복되는 일련번호를 건너뛰지 않고 정렬 - 1, 1, 2
(2) 윈도우 기능의 실제 적용 시나리오
직장이나 면접에서 사용자가 연속으로 로그인해야 하거나 일 수만큼 로그인해야 하는 경우가 있을 수 있습니다. . 다음은 이러한 문제를 해결하기 위해 윈도우 기능을 사용하는 방법에 대한 아이디어를 제공합니다.
# 首先创建虚拟的用户登录表,并插入数据 create table user_login ( user_id varchar(100), login_time datetime ); insert into user_login values (1,'2020-11-25 13:21:12'), (1,'2020-11-24 13:15:22'), (1,'2020-11-24 10:30:15'), (1,'2020-11-24 09:18:27'), (1,'2020-11-23 07:43:54'), (1,'2020-11-10 09:48:36'), (1,'2020-11-09 03:30:22'), (1,'2020-11-01 15:28:29'), (1,'2020-10-31 09:37:45'), (2,'2020-11-25 13:54:40'), (2,'2020-11-24 13:22:32'), (2,'2020-11-23 10:55:52'), (2,'2020-11-22 06:30:09'), (2,'2020-11-21 08:33:15'), (2,'2020-11-20 05:38:18'), (2,'2020-11-19 09:21:42'), (2,'2020-11-02 00:19:38'), (2,'2020-11-01 09:03:11'), (2,'2020-10-31 07:44:55'), (2,'2020-10-30 08:56:33'), (2,'2020-10-29 09:30:28'); # 查看数据 SELECT * FROM user_login;
연속 로그인 일수를 계산할 때는 일반적으로 세 가지 상황이 있습니다.
사용자별 연속 로그인 상황 보기
사용자별 최대 연속 로그인 일수 보기
보기에서 특정 기간 N일 이상 연속 로그인한 사용자
첫 번째 상황: 각 사용자의 연속 로그인 상황을 확인하세요
실제 경험을 바탕으로 일정 시간 내에 사용자가 로그인할 수 있음을 알고 있습니다. 이 정보를 여러 번 연속적으로 사용합니다. 모든 필드가 출력되어야 하므로 최종 결과에 출력되는 필드는 사용자 ID, 첫 번째 로그인 날짜, 로그인 종료 날짜 및 연속 로그인 일 수입니다.
# 数据预处理:由于统计的窗口期是天数,所以可以对登录时间字段进行格式转换,将其变成日期格式然后再去重(去掉用户同一天内多次登录的情况)
# 为方便后续代码查看,将处理结果放置新表中,一步一步操作
create table user_login_date(
select distinct user_id, date(login_time) login_date from user_login);
# 处理后的数据如下:
select * from user_login_date;
# 第一种情况:查看每位用户连续登陆的情况
# 对用户登录数据进行排序
create table user_login_date_1(
select *,
rank() over(partition by user_id order by login_date) irank
from user_login_date);
#查看结果
select * from user_login_date_1;
# 增加辅助列,帮助判断用户是否连续登录
create table user_login_date_2(
select *,
date_sub(login_date, interval irank DAY) idate #data_sub从指定的日期减去指定的时间间隔
from user_login_date_1);
# 查看结果
select * from user_login_date_2;
# 计算每位用户连续登录天数
select user_id,
min(login_date) as start_date,
max(login_date) as end_date,
count(login_date) as days
from user_login_date_2
group by user_id,idate;
# ===============【整合代码,解决用户连续登录问题】===================
select user_id,
min(login_date) start_date,
max(login_date) end_date,
count(login_date) days
from (select *,date_sub(login_date, interval irank day) idate
from (select *,rank() over(partition by user_id order by login_date) irank
from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c
group by user_id,idate;두 번째 경우: 각 사용자의 최대 연속 로그인 일수를 확인하세요
# 计算每个用户最大连续登录天数 select user_id,max(days) from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate) as d group by user_id;
세 번째 경우: 특정 기간에 N일 이상 로그인한 사용자를 확인하세요
확인이 필요한 경우 10일 연속 로그인 일수 11월 29일부터 11월 25일 사이에 5일 이상 연속 로그인한 사용자에 대해 어떻게 구현하나요? . 이 요구 사항은 첫 번째 경우의 쿼리 결과를 사용하여 필터링할 수도 있습니다.
# 查看在这段时间内连续登录天数≥5天的用户 select distinct user_id from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate having days>=5 ) as d;
이러한 작성 방법은 결과를 얻을 수 있지만 이 문제에 대해서는 약간 번거롭습니다. 다음은 간단한 방법입니다. 새로운 정적 창 함수인 Lead()를 참조하세요
select *, lead(login_date,4) over(partition by user_id order by login_date) as idate5 from user_login_date;
lead 함수에는 세 개의 매개변수가 있습니다. 첫 번째 매개변수는 지정된 열(여기서는 로그인 날짜가 사용됨)이고, 두 번째 매개변수는 현재 행 뒤의 여러 행의 값입니다. 여기서는 4번째 로그인 날짜이고, 세 번째 매개변수는 Null을 반환하는 경우입니다. 값은 지정된 값으로 대체될 수 있습니다. 여기서는 세 번째 매개변수가 사용되지 않습니다. over 절에서는 창을 user_id별로 그룹화하고 각 창의 데이터를 로그인 날짜 기준으로 오름차순으로 정렬합니다.
5번째 로그인 날짜(login_date+1)를 사용하세요. 5이면 연속으로 5일 동안 로그인했다는 의미입니다. 값이 5보다 크면 로그인하지 않았음을 의미합니다. 5일 연속 코드와 결과는 다음과 같습니다.
# 计算第5次登录日期与当天的差值 select *,datediff(idate5,login_date)+1 days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_login_date) as a; # 找出相差天数为5的记录 select distinct user_id from (select *,datediff(idate5,login_date)+1 as days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_logrin_date) as a)as b where days = 5;
[연습]메이투안 테이크아웃 플랫폼 데이터 분석 인터뷰 질문 - SQL
기존 거래 데이터 테이블 user_goods_table은 다음과 같습니다.

이제 사장님이 알고 싶어하십니다. 각 사용자가 구매한 테이크아웃 카테고리 선호도 분포를 알아보고, 각 사용자가 가장 많이 구매한 테이크아웃 카테고리가 무엇인지 알아봅니다.
아아아아위 내용은 MySQL에서 윈도우 기능을 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!