
집 >데이터 베이스 >MySQL 튜토리얼 >Python을 사용하여 수천만 개의 데이터를 읽고 자동으로 MySQL 데이터베이스에 쓰는 방법
Python을 사용하여 수천만 개의 데이터를 읽고 자동으로 MySQL 데이터베이스에 쓰는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-30 11:55:281767검색
시나리오 1: mysql에 데이터를 자주 쓸 필요는 없습니다
navicat 도구의 가져오기 마법사 기능을 사용하세요. 이 소프트웨어는 다양한 파일 형식을 지원할 수 있으며 파일 필드를 기반으로 테이블을 자동으로 생성하거나 기존 테이블에 데이터를 삽입할 수 있어 매우 빠르고 편리합니다.
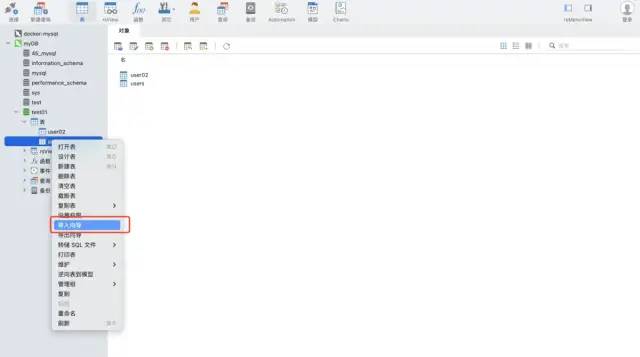
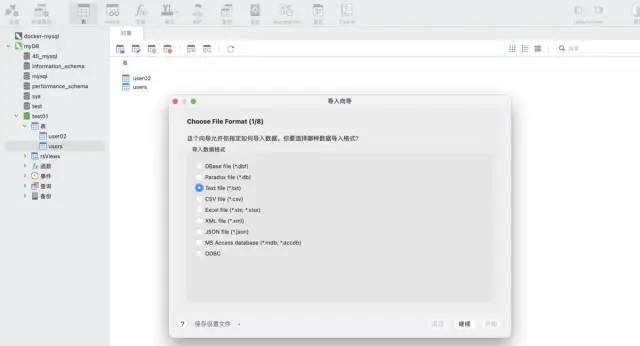
시나리오 2: 데이터는 증분형이므로 자동화해야 하며 mysql
에 자주 기록해야 합니다. 테스트 데이터: csv 형식, 약 1,200만 행
import pandas as pd data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.shape
인쇄 결과:

방법 1: python ➕ pymysql 라이브러리
pymysql 설치 명령:
pip install pymysql
코드 구현:
import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')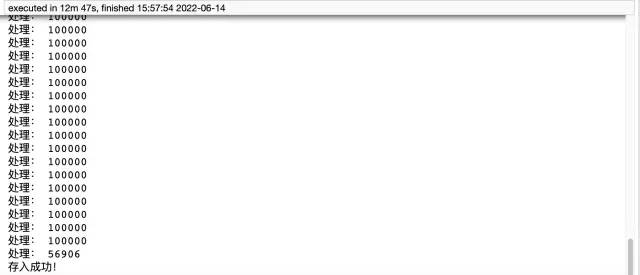
방법 2: pandas ➕ sqlalchem y: pandas는 sqlalchemy를 도입해야 합니다. sql을 지원하기 위해 sqlalchemy의 지원을 통해 모든 일반적인 데이터베이스 유형의 쿼리, 업데이트 및 기타 작업을 구현할 수 있습니다.
코드 구현:
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01') data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.to_sql('user02',engine,chunksize=100000,index=None) print('存入成功!')요약pymysql 메서드는 12분 47초가 소요됩니다. 이는 여전히 상대적으로 길고 코드 양이 많습니다. 그러나 Pandas에서는 이 요구 사항을 달성하려면 5줄의 코드만 필요합니다. 약 4분 정도 소요됩니다. 마지막으로, 첫 번째 방법은 미리 테이블을 생성해야 하지만 두 번째 방법은 그렇지 않다는 점을 덧붙이고 싶습니다. 따라서 모든 사람은 편리하고 효율적인 두 번째 방법을 사용하는 것이 좋습니다. 여전히 느리다고 느껴진다면 멀티 프로세스와 멀티 스레딩을 추가하는 것을 고려해 보세요.
MySQL 데이터베이스에 데이터를 저장하는 가장 완벽한 세 가지 방법:
- navicat의 가져오기 마법사 기능을 사용하는 직접 저장
- Python pymysql
- Pandas sqlalchemy
위 내용은 Python을 사용하여 수천만 개의 데이터를 읽고 자동으로 MySQL 데이터베이스에 쓰는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
이 기사는 yisu.com에서 복제됩니다. 침해가 있는 경우 admin@php.cn으로 문의하시기 바랍니다. 삭제
이전 기사:MySQL에서 정수를 사용하는 방법다음 기사:MySQL에서 정수를 사용하는 방법