
Taifan Technology 부사장 Ma Guoning: Königsberg부터 모든 산업 지원까지 모든 것을 매핑

- 王林앞으로
- 2023-05-29 20:37:041412검색
2022년 8월 6일과 7일에 AISummit 글로벌 인공지능 기술 컨퍼런스가 예정대로 개최됩니다. 7일 오후 열린 'AI 역량 강화 산업 실천' 하위 포럼에서 Taifan Technology 부사장 Ma Guoning은 'Königsberg에서 모든 산업 역량 강화까지 모든 것을 매핑'이라는 주제를 공유하고 지식 지도를 공유했습니다. 수천 개의 산업 분야에서 역량을 강화합니다.
우공이 AI라면 산을 옮길 수 있을까요?
우공이 AI로 간주된다면 산을 옮길 수 있을까요? 산을 옮기는 방법?
마궈닝(Ma Guoning)은 인공지능 산업에서는 모든 수직 분야가 큰 산이라고 말했습니다. 예를 들어 금융, 산업, 정부 업무 및 기타 산업에서 알고리즘을 사용하여 산업별 문제를 해결할 때 원래 설계 및 구현과 항상 다르다는 것을 알게 될 것입니다. 주된 이유는 우리의 알고리즘 논리가 반드시 그렇지 않을 수도 있다는 것입니다. 업계의 비즈니스 논리와 일치합니다. 이 문제를 해결하는 초기 방법은 데이터 인텔리전스와 컴퓨팅 인텔리전스를 사용하여 힙 데이터의 양을 기반으로 학습하는 것입니다. 그러나 이 방법은 이후 단계에서 약간의 병목 현상도 발생합니다. 이를 위해 우리는 일부 시나리오에서 발생하는 문제를 해결하기 위해 얼굴 인식, 음성 인식과 같은 지각 지능 방법을 사용하기 시작했습니다.
지각 지능에도 병목 현상이 발생할 때 최신 방법은 인지 지능 알고리즘을 사용하여 이를 해결하는 것입니다. 그렇다면 인지 지능이 인간의 사고와 인지 과정을 시뮬레이션하여 복잡하고 어려운 문제를 해결할 수 있을까요?
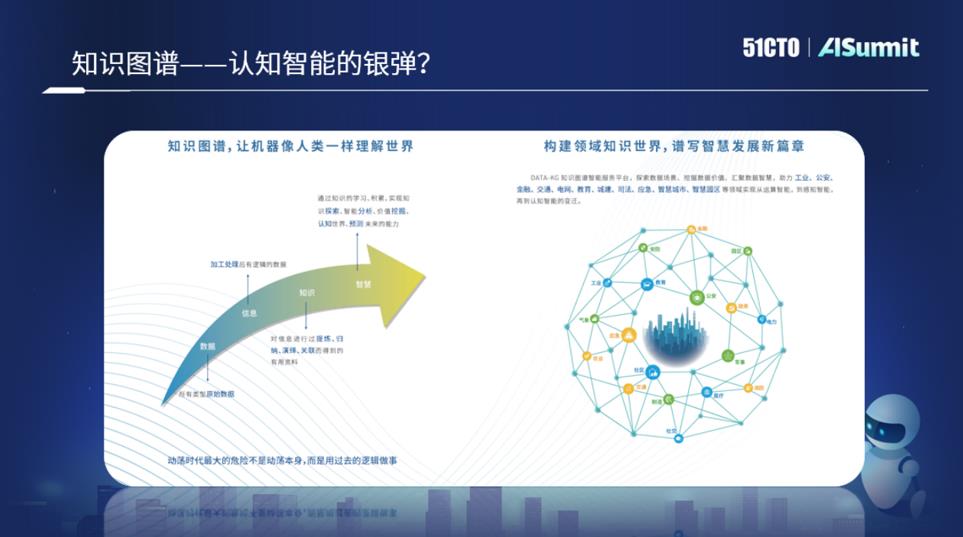
인지 지능 분야에서 Google은 오랫동안 지식 그래프를 사용하여 모든 지식을 동일한 그래프에 배치하고 인간의 사고와 추론 및 추론 과정을 시뮬레이션하려고 노력해 왔습니다. 하지만 구글이 이 아이디어를 제안한 이후 적어도 현재까지는 인간의 사고 과정을 완전히 시뮬레이션할 수 있는 방법은 아직 없습니다. 지도를 구축하는 과정은 복잡하지 않지만, 데이터의 양이 충분히 많으면 다양한 문제에 직면하게 됩니다. 예를 들어 WolframAlpha에는 10억 개가 넘는 엔터티가 있고, DBpedia에는 30억 개가 넘는 트리플이 있고, Google에는 현재 5억 개가 넘는 엔터티가 있으며, Microsoft Probase에는 수천만 개의 개념이 있습니다. 이런 경우 애플리케이션은 커녕 검색과 질의 분석만으로는 이미 어렵다.
많은 학자들은 단일 지점이나 클러스터로는 이 문제를 해결할 수 없다고 믿기 때문에 이 문제를 해결하기 위해 두 개의 클러스터 또는 심지어 12개의 클러스터를 사용합니다. 실제로 지식 그래프에서 힙 클러스터링을 수행하기 어려운 이유는 이렇게 많은 수의 개체와 노드가 연관되어 있을 경우 데이터를 분리하기가 어렵기 때문입니다.
AI는 업계에 힘을 실어줍니다. AI에 힘을 실어주는 사람은 누구일까요?
원래는 AI를 사용하여 산업에 힘을 실어주고 싶었지만 계산 지능부터 지각 지능, 인지 지능에 이르기까지 이제 AI에도 힘을 실어줄 사람이 필요합니다. 그럼 이제 어떻게 해야 하지?
마궈닝은 거인의 어깨 위에 서는 것이 길이라고 믿습니다.
위 사진의 쾨니히스베르크(Königsberg)는 작은 마을이지만 수학이나 그래프 이론의 세계에서는 매우 유명합니다. 주로 위대한 수학자 오일러(Euler)가 1736년 쾨니히스베르크(Königsberg)의 문제를 해결했기 때문입니다. 수학의 새로운 분야, 그래프 이론. 지식 그래프를 클러스터나 분산 환경에서 활용하는 경우 이러한 문제는 수학적 이론을 바탕으로 해결해야 합니다.
따라서 컴퓨터 문제가 어느 정도 해결되면 수학적 문제로 축소됩니다. 대규모 지식 그래프를 다룰 때는 분산 문제를 해결하기 위해 지식 그래프를 분할하고 컴퓨팅 파워를 재사용해야 합니다. 그렇다면 분할 과정에서 분할된 지식 그래프 간의 상관관계를 최소화하는 방법은 무엇일까? 이를 위해 업계에서 확립된 또는 최첨단 알고리즘을 사용하여 데이터 규모 및 배포 요구 사항을 충족하면서 그래프 분할을 충족해야 합니다.

그러나 현재 공개적으로 구현되거나 기록된 알고리즘으로는 모든 문제를 완벽하게 해결할 수 없습니다. 하나는 클러스터링이고 다른 하나는 분산입니다. 절단면이나 정점 수를 최소화하면서 각 기계 간의 로드 밸런싱 및 통신 비용 문제를 동시에 만족시키기 어렵기 때문입니다.
이러한 문제를 해결하는 방법은 무엇입니까? 우리의 접근 방식은 가중치가 없는 간단한 그래프의 복잡성을 지수 내 상수로 줄이는 것입니다. 가중치 그래프에서 지수 중 하나를 일정한 복잡성으로 줄이는 것은 비교적 최첨단 연구 결과입니다. 하이퍼그래프 분야에서 하이퍼그래프의 절단 문제는 궁극적으로 서브브레인 k-파트의 특수한 경우로 간주되어야 하며, K값이 결정되면 이를 해결하는데 문제가 없다.

예를 들어 간단한 그래프의 경우 3개의 선으로 자르면 실제로는 전체 지식 그래프를 3개의 클러스터로 나누는 것으로 간단히 이해할 수 있습니다. 그 중 지식 노드 S2는 독립적으로 절단되고, 반대편의 S2는 최소 독립 절단으로, 이 그래프가 분리된 이유를 모두가 쉽게 이해할 수 있도록 하기 위해 사용하는 간단한 시각적 설명입니다.
효과 측면에서 METIS 알고리즘과 마찬가지로 파티션 전체의 정점 수와 Hash 알고리즘 또는 JA-BE-JA 알고리즘과 같은 후속 지식 마이닝 시간을 최소화하는 측면에서 더 균형이 잡혀 있을 수 있습니다. 한편으로는 더 나은 성능을 발휘합니다. 만족스럽지는 않지만 METIS 알고리즘의 성능은 상대적으로 균형이 잡혀 있습니다.
지식 그래프 및 모든 산업의 역량 강화
Taifan Technology는 기술 및 산업 연구를 기반으로 지식 그래프 플랫폼을 구축했습니다. 상위 계층은 검색, 시각적 지식 쿼리 및 지능형 질문 및 답변을 포함한 응용 서비스 시스템입니다. .최하층에는 지식이 통합되어 지도의 "중요 기관"이 구성됩니다. 실제로 그래프는 원래 의미론적 문제였으며, 시맨틱 웹을 기반으로 개발되었습니다. 지식을 업데이트하는 방법, 업데이트가 얼마나 세분화되어 있는지, 관련 분야에서 얼마나 많은 개체를 다루어야 하는지, 얼마나 많은 매핑 관계를 다루어야 하는지 등을 포함한 의미 체계 데이터베이스 관리를 Taifan Technology가 전체 프레임워크에 넣습니다. 따라서 이는 모든 계층에서 사용할 수 있는 매우 다재다능한 프레임워크 플랫폼입니다.

또한 전체 프레임워크에는 지능형 추천, 검색 및 확장성을 포함하여 지식 베이스의 전체 수명 주기 관리를 실현하는 등 실제 적용에 필요한 기능도 통합되어 있습니다. . 실제로 고려해야 할 문제. 또한 지식 마이닝을 통해 많은 관계 탐색 및 마이닝을 해결할 수 있습니다.
다음 시간에는 마궈닝이 스마트 파크, 스마트 빌딩, 스마트 교통, 스마트 항공, 스마트 과학 데이터 분석 등 시나리오 사례를 통해 다양한 산업 분야에서 즈마푸의 실제 적용 사례를 자세히 소개했습니다.
"기술 혁신의 별빛 바다와 미래의 무한한 가능성은 더욱 흥미진진합니다. 저는 이것을 깊이 믿습니다." 마 구오닝은 이번 공유를 통해 더 많은 동료나 다른 야심 찬 사람들이 함께할 수 있기를 바란다고 말했습니다. 이 업계는 수천 개의 산업에 힘을 실어주기 위해 인공 지능 기술을 적용하는 데 더 자신감을 가질 수 있습니다.
현재 컨퍼런스 연설 다시보기와 PPT가 온라인에 공개되어 흥미로운 콘텐츠를 보실 수 있습니다.
위 내용은 Taifan Technology 부사장 Ma Guoning: Königsberg부터 모든 산업 지원까지 모든 것을 매핑의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!