
빠르고 사용하기 쉬운 Python 데이터 시각화 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-29 17:34:161272검색
데이터 시각화는 데이터 과학 또는 기계 학습 프로젝트에서 매우 중요한 부분입니다. 일반적으로 데이터에 대한 어느 정도 이해를 얻으려면 프로젝트 초기에 탐색적 데이터 분석(EDA)을 수행해야 하며, 시각화를 생성하면 특히 대규모 고차원 데이터의 경우 분석 작업을 더 명확하고 이해하기 쉽게 만들 수 있습니다. . 세트. 프로젝트가 끝나갈 무렵에는 청중(종종 기술적 지식이 없는 고객)이 이해할 수 있도록 명확하고 간결하며 설득력 있는 방식으로 최종 결과를 제시하는 것도 중요합니다.
Heat Map
데이터 매트릭스의 각 요소의 값을 색상으로 표현하는 방식을 Heat Map이라고 합니다. 매트릭스 인덱싱을 통해 비교해야 할 두 항목이나 특징을 연관시키고 서로 다른 색상을 사용하여 서로 다른 값을 나타냅니다. 히트 맵은 색상이 해당 위치의 행렬 요소 크기를 직접 반영할 수 있기 때문에 여러 특성 변수 간의 관계를 표시하는 데 적합합니다. 히트맵의 다른 지점을 통해 각 관계를 데이터 세트의 다른 관계와 비교할 수 있습니다. 색상은 직관적인 특성으로 인해 데이터를 해석하는 간단하고 이해하기 쉬운 방법을 제공합니다.
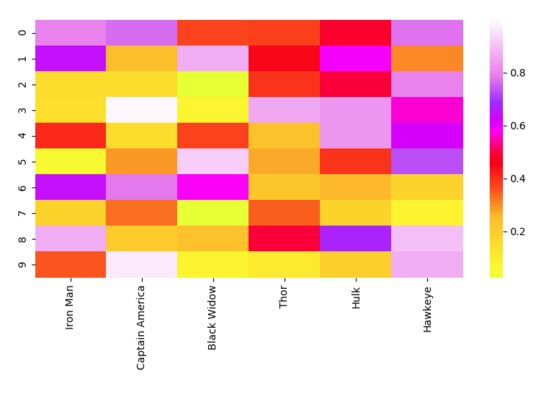
이제 구현 코드를 살펴보겠습니다. "matplotlib"와 비교하여 "seaborn"은 일반적으로 여러 색상, 그래픽 또는 변수와 같은 더 많은 구성 요소가 필요한 고급 그래픽을 그리는 데 사용할 수 있습니다. "matplotlib"는 그래픽을 표시하는 데 사용할 수 있고, "NumPy"는 데이터를 생성하는 데 사용할 수 있으며, "pandas"는 데이터를 처리하는 데 사용할 수 있습니다! 그림 그리기는 "seaborn"의 단순한 기능일 뿐입니다.
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
2차원 밀도 플롯
2차원 밀도 플롯(2D Density Plot)은 1차원 버전의 밀도 플롯을 직관적으로 확장한 것입니다. 두 변수의 확률 분포를 확인하세요. 오른쪽의 축척 플롯은 색상을 사용하여 아래 2D 밀도 플롯의 각 지점의 확률을 나타냅니다. 우리 데이터가 발생 확률이 가장 높은 곳(즉, 데이터 포인트가 가장 집중되어 있는 곳)은 크기=0.5, 속도=1.4 정도인 것으로 보입니다. 지금까지 알고 있듯이 2D 밀도 플롯은 1D 밀도 플롯과 같이 단 하나의 변수와 달리 데이터가 두 개의 변수로 가장 집중된 영역을 빠르게 찾는 데 매우 유용합니다. 2차원 밀도 도표를 사용하여 데이터를 관찰하는 것은 출력에 중요한 두 개의 변수가 있고 두 변수가 어떻게 함께 작동하여 출력 분포에 기여하는지 이해하려는 경우에 유용합니다.
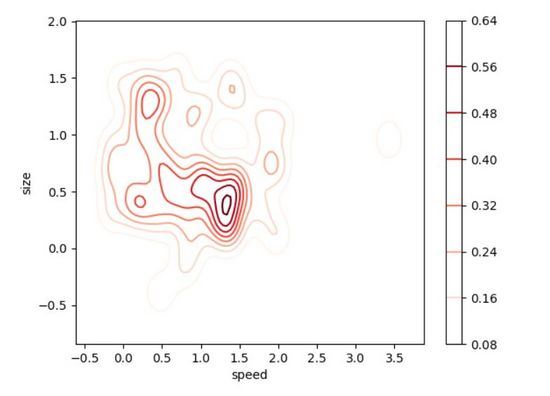
"seaborn"을 사용하여 코드를 작성하는 것이 매우 편리하다는 사실이 다시 한 번 입증되었습니다! 이번에는 데이터 시각화를 더욱 흥미롭게 만들기 위해 편향된 분포를 만들어 보겠습니다. 시각화를 더 명확하게 보이도록 대부분의 선택적 매개변수를 조정할 수 있습니다.
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
스파이더 플롯
스파이더 플롯은 일대다 관계를 표시하는 가장 좋은 방법 중 하나입니다.. 즉, 특정 변수나 범주를 기준으로 여러 변수의 값을 그래프로 그려서 볼 수 있습니다. 거미줄 다이어그램에서는 특정 방향으로 갈수록 커버되는 면적과 중심으로부터의 길이가 커지기 때문에 한 변수가 다른 변수에 비해 갖는 중요성이 명확하고 분명합니다. 이러한 변수로 설명되는 다양한 개체 범주를 나란히 표시하여 개체 간의 차이점을 확인할 수 있습니다. 아래 차트에서는 어벤져스의 다양한 속성을 쉽게 비교하고 각각의 뛰어난 점을 확인할 수 있습니다! (이 데이터는 무작위로 설정되었으며 어벤져스 멤버들에 대해 편견을 갖고 있지 않다는 점에 유의하시기 바랍니다.)
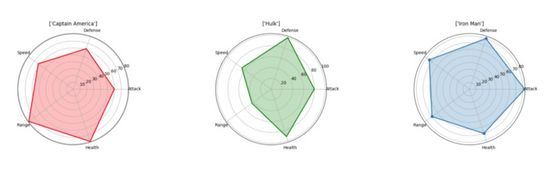
"seaborn"을 사용하지 않고도 "matplotlib"을 사용하여 시각화 결과를 생성할 수 있습니다. 각 속성은 원주 주위에 동일한 간격으로 배치되어야 합니다. 각 모서리에 레이블이 있으며 중심으로부터의 거리가 해당 값/크기에 비례하는 점으로 값을 표시합니다. 이를 보다 명확하게 보여주기 위해 속성 포인트를 연결하는 선으로 형성된 영역을 반투명 색상으로 채웁니다.
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()Treemap
저희는 초등학교 때부터 트리맵 사용법을 배웠습니다. 수형도는 본질적으로 직관적이기 때문에 이해하기 쉽습니다. 직접 연결된 노드는 밀접하게 관련되어 있는 반면, 여러 연결이 있는 노드는 덜 유사합니다. 아래 시각화에서는 Kaggle의 통계(건강, 공격, 방어, 특수 공격, 특수 방어, 속도)를 기반으로 포켓몬 게임 데이터 세트의 작은 하위 집합에 대한 덴드로그램을 플롯했습니다.
因此,统计意义上最匹配的口袋妖怪将被紧密地连接在一起。例如,在图的顶部,阿柏怪 和尖嘴鸟是直接连接的,如果我们查看数据,阿柏怪的总分为 438,尖嘴鸟则为 442,二者非常接近!但是如果我们看看拉达,我们可以看到其总得分为 413,这和阿柏怪、尖嘴鸟就具有较大差别了,所以它们在树状图中是被分开的!当我们沿着树往上移动时,绿色组的口袋妖怪彼此之间比它们和红色组中的任何口袋妖怪都更相似,即使这里并没有直接的绿色的连接。
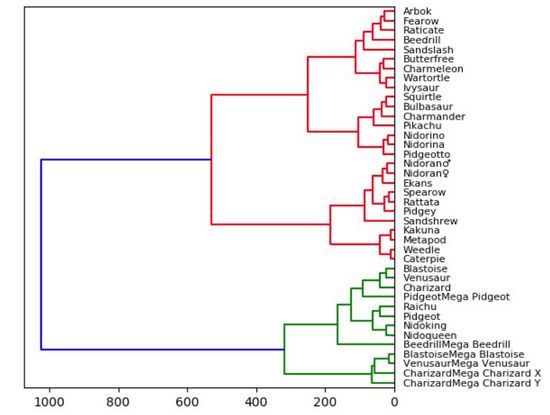
实际上,我们需要使用「Scipy」来绘制树状图。一旦读取了数据集中的数据,我们就会删除字符串列。这么做只是为了使可视化结果更加直观、便于理解,但在实践中,将这些字符串转换为分类变量会得到更好的结果和对比效果。我们还创建了数据帧的索引,以方便在每个节点上正确引用它的列。告诉大家的最后一件事是:在“Scipy”中,计算和绘制树状图只需一行简单代码。
# Import libs import pandas as pd from matplotlib import pyplot as plt from scipy.cluster import hierarchy import numpy as np # Read in the dataset # Drop any fields that are strings # Only get the first 40 because this dataset is big df = pd.read_csv('Pokemon.csv') df = df.set_index('Name') del df.index.name df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1) df = df.head(n=40) # Calculate the distance between each sample Z = hierarchy.linkage(df, 'ward') # Orientation our tree hierarchy.dendrogram(Z, orientation="left", labels=df.index) plt.show()
위 내용은 빠르고 사용하기 쉬운 Python 데이터 시각화 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!