
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 인덱스 구조에서 B+ 트리를 사용하는 문제를 이해하는 방법
MySQL 인덱스 구조에서 B+ 트리를 사용하는 문제를 이해하는 방법

- 王林앞으로
- 2023-05-29 15:31:131612검색
1. B-트리 및 B+ 트리
일반적으로 데이터베이스 스토리지 엔진은 B-트리 또는 B+ 트리를 사용하여 인덱스를 저장합니다. 먼저 그림과 같이 B-트리를 살펴보십시오.
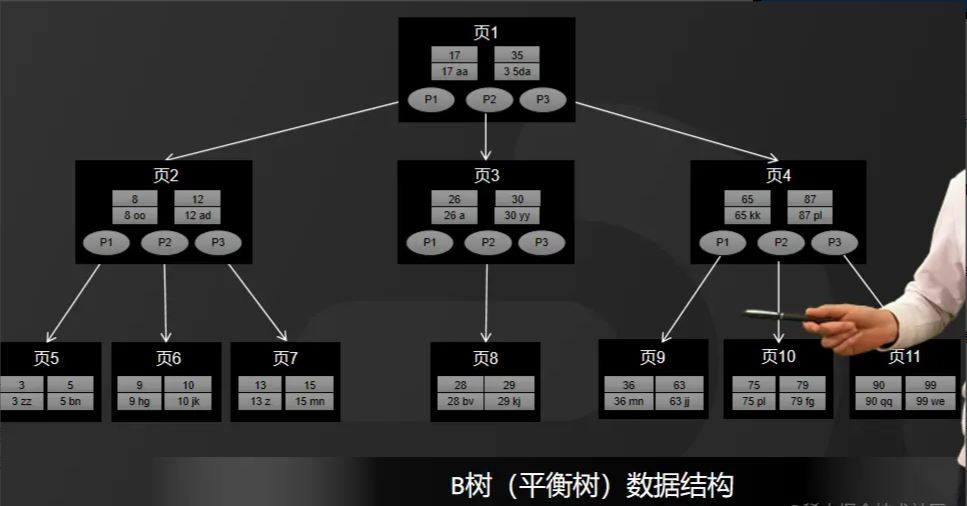
B-트리는 다중 방향 균형 트리입니다. 이 저장 구조를 사용하여 많은 양의 데이터를 저장하면 전체 높이가 이진 트리보다 훨씬 짧아집니다.
데이터베이스의 경우 모든 데이터가 디스크에 저장되며 특히 랜덤 디스크 I/O의 경우 디스크 I/O 효율성이 상대적으로 낮습니다.
그래서 높이가 디스크 I/O 개수를 결정합니다. 디스크 I/O 개수가 적을수록 성능 향상은 그림과 같이 B-tree를 인덱스 저장 구조로 사용하는 이유입니다.
MySQL의 InnoDB 스토리지 엔진은 향상된 B-트리 구조, 즉 B+ 트리를 인덱스 및 데이터 저장 구조로 사용합니다.
B-트리 구조에 비해 B+트리는 그림과 같이 두 가지 측면에서 최적화되었습니다.
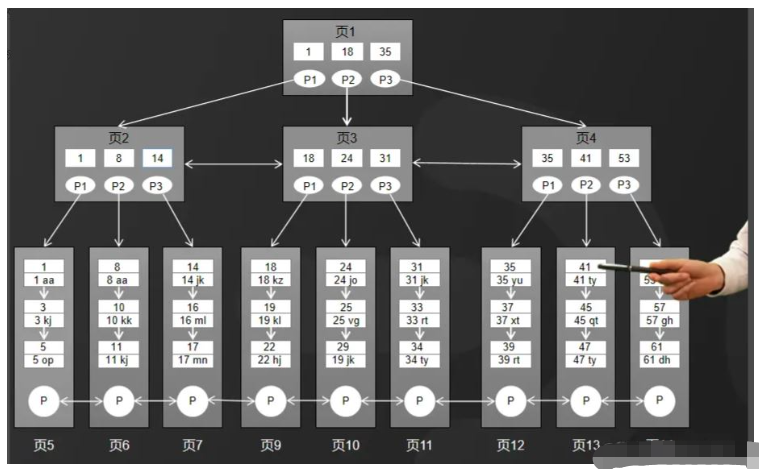
1. B+ 트리의 모든 데이터는 리프 노드에 저장되고, 리프가 아닌 노드에는 인덱스만 저장됩니다.
2. 리프 노드의 데이터는 이중 연결 목록을 사용하여 관련됩니다.
2. 원인 분석
MySQL 인덱스 구조는 다음과 같은 4가지 이유로 B+ 트리를 사용한다고 생각합니다.

1 디스크 I/O 효율성의 관점에서 보면 B+ 트리의 리프가 아닌 노드가 사용됩니다. 데이터를 저장하지 않으므로 트리의 각 레이어는 더 많은 인덱스를 저장할 수 있습니다. 즉, 레이어 높이가 동일할 때 B+ 트리는 B-트리보다 더 많은 데이터를 저장할 수 있으므로 간접적으로 디스크 I/O 수가 줄어듭니다. .
2. 범위 쿼리 효율성 측면에서 볼 때: MySQL에서 범위 쿼리는 비교적 일반적인 작업이며 B+ 트리의 리프 노드에 저장된 모든 데이터는 이중 연결 목록을 사용하여 연결되므로 B+ 트리를 쿼리할 때 필요한 것은 다음과 같습니다. 순회를 위해 두 개의 노드를 확인하는 반면 B-트리는 모든 노드를 획득해야 하므로 범위 쿼리에서는 B+ 트리가 더 효율적입니다.
3. 전체 테이블 스캐닝의 관점에서: B+ 트리의 리프 노드는 모든 데이터를 저장하기 때문에 B+ 트리의 전역 스캐닝 기능은 리프 노드만 스캔하면 되기 때문에 더욱 강력합니다. B-트리는 전체 트리를 순회해야 합니다.
4. 자체 증가 ID의 관점에서 보면 B+ 트리 기반 데이터 구조로, 자체 증가 정수 데이터를 기본 키로 사용하면 데이터 추가 시 리프 노드 분할을 더 잘 피할 수 있습니다. 문제.
위 내용은 MySQL 인덱스 구조에서 B+ 트리를 사용하는 문제를 이해하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!