
Redis의 마스터-슬레이브 복제, 센트리 및 클러스터링 분석 예

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-29 13:52:54932검색
1. Redis 마스터-슬레이브 복제
1. 마스터-슬레이브 복제 개요
마스터-슬레이브 복제는 하나의 Redis 서버에서 다른 Redis 서버로 데이터를 복사하는 프로세스입니다. 전자를 마스터 노드(Master)라고 하고 후자를 슬레이브 노드(Slave)라고 합니다. 데이터 복제는 단방향이며 마스터 노드에서 슬레이브 노드로만 가능합니다.
기본적으로 각 Redis 서버는 마스터 노드이며 마스터 노드는 여러 개의 슬레이브 노드를 가질 수 있지만 슬레이브 노드는 하나의 마스터 노드만 가질 수 있습니다. [관련 추천: Redis 영상 튜토리얼]
2. 마스터-슬레이브 복제의 역할
● 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
● 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
● 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;有其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
● 高可用基石: 위의 기능 외에도 마스터-슬레이브 복제는 센티넬 및 클러스터 구현의 기반이기도 합니다. , 마스터-슬레이브 복제는 Redis 고가용성 Foundation입니다.
3. 마스터-슬레이브 복제 프로세스
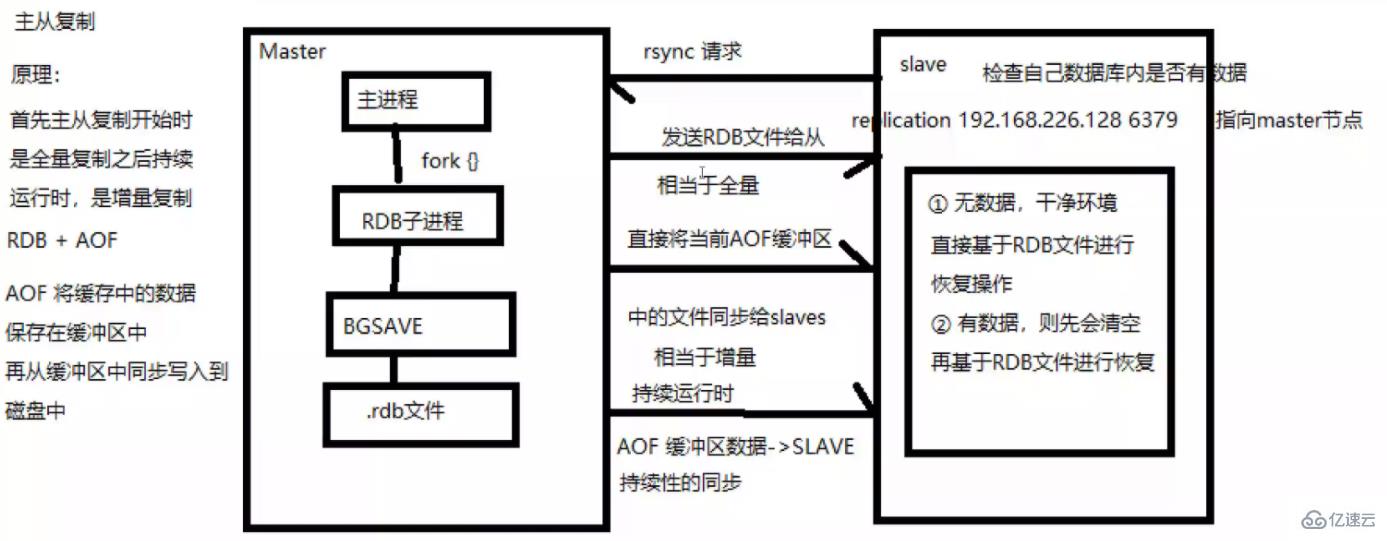
(1) 슬레이브 머신 프로세스가 시작되면 마스터 머신에 "sync command" 명령을 보내 동기 연결을 요청합니다.
(2) 첫 번째 연결이든 재연결이든 마스터 머신은 백그라운드 프로세스를 시작하고 데이터 스냅샷을 데이터 파일에 저장합니다(RDB 작업 수행). 동시에 마스터는 수정하는 모든 명령도 기록합니다. 데이터를 파일의 데이터 파일에 캐시합니다.
(3) 백그라운드 프로세스가 캐싱 작업을 완료한 후 마스터 머신은 데이터 파일을 슬레이브 머신으로 전송합니다. 슬레이브 머신은 데이터 파일을 하드 디스크에 저장한 다음 마스터 머신에 로드합니다. 데이터를 수정합니다. 모든 작업은 슬레이브 시스템으로 함께 전송됩니다. 슬레이브에 오류가 발생하여 가동 중지 시간이 발생하면 정상으로 돌아올 때 자동으로 다시 연결됩니다.
(4) 마스터 시스템은 슬레이브 시스템으로부터 연결을 받은 후 전체 데이터 파일을 슬레이브 시스템으로 보냅니다. 마스터가 슬레이브로부터 동시에 여러 동기화 요청을 받으면 마스터는 다음에서 프로세스를 시작합니다. 백그라운드에서 데이터 파일을 저장한 다음 모든 슬레이브 머신에 전송하여 모든 슬레이브 머신이 정상인지 확인합니다.
4. Redis 마스터-슬레이브 복제 구축
4.1 서버 IP 구성
| Server | 호스트 이름 | IP |
|---|---|---|
| 마스터 노드 | 마스터 | 192.168.122.10 |
| Slave1 노드 | slave1 | 192.168.122.11 |
| Slave2 노드 | slave2 | 192.168.122.12 |
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
E
Redis 설치에 대한 자세한 내용은 이전 블로그를 참조하세요:
Nosql의 redis 자세한 설명传入安装包到/opt目录 yum install -y gcc gcc-c++ make tar zxvf redis-5.0.7.tar.gz -C /opt/ cd /opt/redis-5.0.7/ make make PREFIX=/usr/local/redis install cd /opt/redis-5.0.7/utils ./install_server.sh ...... Please select the redis executable path [] #输入/uar/local/redis/bin/redis-server ln -s /usr/local/redis/bin/* /usr/local/bin/
4.4 redis 구성 파일 수정(마스터 노드 작업)
마스터: 192.168.122.10
[root@master ~]# vim /etc/redis/6379.conf ##70行,修改监听地址为0.0.0.0,表示监听任何地址 bind 0.0.0.0 ##137行,开启守护进程 daemonize yes ##172行,指定日志文件目录 logfile /var/log/redis_6379.log ##264行,指定工作日志 dir /var/lib/redis/6379 ##700行,开启AOF持久化功能 appendonly yes4.5 Redis 구성 파일 수정(슬레이브 노드 작업)
Slave1: 192.168.122.11
[root@slave1 utils]# vim /etc/redis/6379.conf ##70行,修改监听地址为0.0.0.0,表示监听任何地址 bind 0.0.0.0 ##137行,开启守护进程 daemonize yes ##172行,指定日志文件目录 logfile /var/log/redis_6379.log ##264行,指定工作日志 dir /var/lib/redis/6379 ##288行,添加要同步的Master节点IP和端口 replicaof 192.168.122.10 6379 ##700行,开启AOF持久化功能 appendonly yes [root@slave1 utils]# /etc/init.d/redis_6379 restart Stopping ... Redis stopped Starting Redis server...
Slave2: 192.168.122.12
[root@slave2 utils]# vim /etc/redis/6379.conf ##70行,修改监听地址为0.0.0.0,表示监听任何地址 bind 0.0.0.0 ##137行,开启守护进程 daemonize yes ##172行,指定日志文件目录 logfile /var/log/redis_6379.log ##264行,指定工作日志 dir /var/lib/redis/6379 ##288行,添加要同步的Master节点IP和端口 replicaof 192.168.122.10 6379 ##700行,开启AOF持久化功能 appendonly yes [root@slave2 utils]# /etc/init.d/redis_6379 restart Stopping ... Redis stopped Starting Redis server...
4.6 마스터-슬레이브 효과 검증
4.6.1 마스터 노드에서 로그 읽기
[root@master ~]# tail -f /var/log/redis_6379.log 1002:M 23 Sep 2021 16:46:33.569 * Background saving terminated with success 1002:M 23 Sep 2021 16:46:33.569 * Synchronization with replica 192.168.122.11:6379 succeeded 1002:M 23 Sep 2021 16:46:34.519 * Replica 192.168.122.12:6379 asks for synchronization 1002:M 23 Sep 2021 16:46:34.519 * Full resync requested by replica 192.168.122.12:6379 1002:M 23 Sep 2021 16:46:34.519 * Starting BGSAVE for SYNC with target: disk 1002:M 23 Sep 2021 16:46:34.519 * Background saving started by pid 7941 7941:C 23 Sep 2021 16:46:34.521 * DB saved on disk 7941:C 23 Sep 2021 16:46:34.521 * RDB: 0 MB of memory used by copy-on-write 1002:M 23 Sep 2021 16:46:34.591 * Background saving terminated with success 1002:M 23 Sep 2021 16:46:34.591 * Synchronization with replica 192.168.122.12:6379 succeeded
4.6.2 마스터 노드에서 슬레이브 노드 확인
[root@master ~]# redis-cli info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.122.11,port=6379,state=online,offset=910,lag=0 slave1:ip=192.168.122.12,port=6379,state=online,offset=910,lag=0 master_replid:9d7fa17fc64cd573f5b81457183831d97dfad7dc master_replid2:0000000000000000000000000000000000000000 master_repl_offset:910 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:910
2. Redis Sentinel 모드
1 Sentinel 모드의 핵심 기능On. 마스터-슬레이브 복제의 기반이 되는 Sentinel이 도입되었습니다. 마스터 노드의 자동 장애 조치.
2. Sentinel 모드의 원리Sentinel은 마스터-슬레이브 구조의 각 서버를 모니터링하는 데 사용되는 분산 시스템입니다. 장애가 발생하면 투표 메커니즘을 통해 새로운 마스터가 선택되고 모든 슬레이브가 연결됩니다. 새로운 마스터. 따라서 Sentinel을 실행하는 전체 클러스터의 수는 3개 노드 이상이어야 합니다.
3. 센티넬 모드의 역할● 모니터링: 센티넬은 마스터 노드와 슬레이브 노드가 정상적으로 작동하는지 지속적으로 확인합니다.
자동 장애 조치: 마스터 노드가 제대로 작동하지 않으면 Sentinel은 장애가 발생한 마스터 노드의 슬레이브 노드 중 하나를 새 마스터 노드로 업그레이드하고 자동 장애 조치 작업을 시작합니다. 다른 슬레이브 노드 노드는 새로운 기본 노드를 복제하도록 변경됩니다. ● 알림 알림: Sentinel은 장애 조치 결과를 클라이언트에 보낼 수 있습니다. 监控:哨兵会不断地检查主节点和从节点是否运作正常。
● 自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
● 通知提醒
4. 센티넬 모드의 구조
센티넬 구조는 센티넬 노드와 데이터 노드의 두 부분으로 구성됩니다. ● 센티넬 노드: 센티넬 시스템은 하나 이상의 노드로 구성됩니다. 데이터를 저장하지 않는 redis 노드.
● 데이터 노드: 마스터 노드와 슬레이브 노드는 모두 데이터 노드입니다.
5. Sentinel 모드 작동 방식
 Sentinel 모드의 시작은 마스터-슬레이브 모드에 따라 다르므로 Sentinel 모드를 시작하기 전에 마스터-슬레이브 모드를 설치해야 합니다. Sentinel 모드는 모든 Redis 작업 노드가 정상인지 여부를 모니터링합니다. 마스터에 문제가 있는 경우 다른 노드가 마스터 노드와의 연결이 끊겼기 때문에 투표의 절반 이상이 투표하는 것으로 간주됩니다. 실제로 마스터에 문제가 있음을 확인하고 센티널룸에 통보한 후 슬레이브 중 하나를 새로운 마스터로 선택합니다.
Sentinel 모드의 시작은 마스터-슬레이브 모드에 따라 다르므로 Sentinel 모드를 시작하기 전에 마스터-슬레이브 모드를 설치해야 합니다. Sentinel 모드는 모든 Redis 작업 노드가 정상인지 여부를 모니터링합니다. 마스터에 문제가 있는 경우 다른 노드가 마스터 노드와의 연결이 끊겼기 때문에 투표의 절반 이상이 투표하는 것으로 간주됩니다. 실제로 마스터에 문제가 있음을 확인하고 센티널룸에 통보한 후 슬레이브 중 하나를 새로운 마스터로 선택합니다.
6. 장애 조치 메커니즘
- 은 마스터 노드의 실패 여부를 감지하기 위해 센티넬 노드에 의해 정기적으로 모니터링됩니다. Sentinel 노드는 1초마다 ping 명령을 보내 하트비트 감지를 수행하고 그 결과를 마스터 노드, 슬레이브 노드 및 기타 Sentinel 노드에 보냅니다. 마스터 노드가 일정 시간 내에 응답하지 않거나 오류 메시지로 응답하는 경우 센티널은 마스터 노드가 주관적으로(일방적으로) 오프라인 상태인 것으로 간주합니다. 센티넬 노드의 절반 이상이 마스터 노드가 주관적으로 오프라인이라고 믿으면 객관적으로 오프라인이 됩니다.
- 마스터 노드에 장애가 발생하면 Sentinel 노드는 Raft 알고리즘(선거 알고리즘)을 통해 선출 메커니즘을 구현하여 마스터 노드의 장애 조치 및 알림을 처리할 리더로 Sentinel 노드를 공동 선출합니다. 따라서 Sentinel 클러스터의 호스트 수는 노드 3개 이상이어야 합니다.
- 리더 센티넬 노드는 장애 조치를 수행합니다.
● 슬레이브 노드를 새 마스터 노드로 업그레이드하고 다른 슬레이브 노드가 새 마스터 노드를 가리키도록 합니다.
● 원래 마스터 노드가 복구되면 또한 슬레이브 노드가 되어 새로운 마스터 노드를 가리킵니다.
● 마스터 노드가 변경되었음을 클라이언트에 알립니다.
목표 오프라인은 마스터 노드에만 적용되는 개념입니다. 슬레이브 노드와 센티널 노드가 실패하면 센티널이 주관적으로 오프라인 상태가 된 후에는 후속 목표 오프라인 및 장애 조치 작업이 발생하지 않습니다.
7. 마스터 노드 선출
- 센티넬 핑 응답에 응답하지 않는 비정상(오프라인) 슬레이브 노드를 필터링합니다.
- 구성 파일에서 우선 순위가 가장 높은 슬레이브 노드를 선택합니다(복제 우선 순위, 기본값은 100).
- 복사 오프셋이 가장 큰 슬레이브 노드, 즉 가장 완전한 사본을 선택합니다.
8. Redis Sentinel 모드 구축
8.1 서버 IP 구성
| 호스트 이름 | IP | |||
|---|---|---|---|---|
| 마스터 | 192.168.122.10 | |||
| slave1 | 192.168.122.11 | |||
| slave2 | 192.168.122.12 |
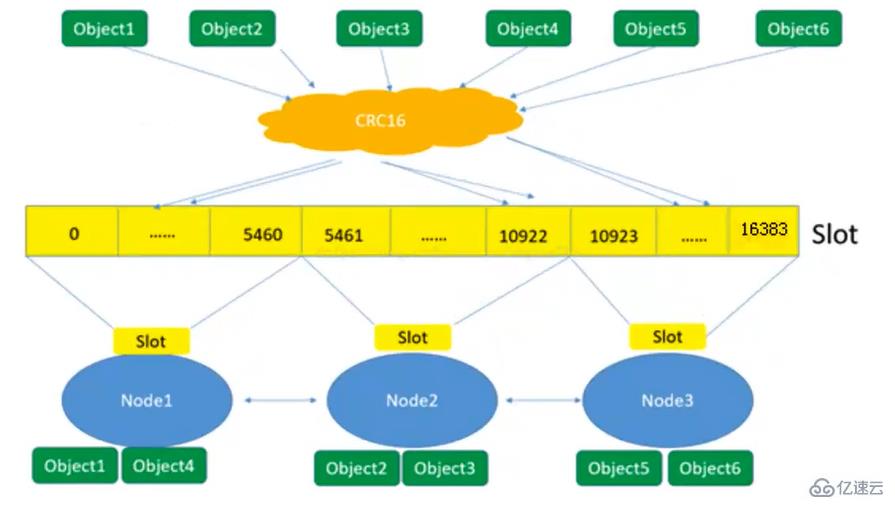
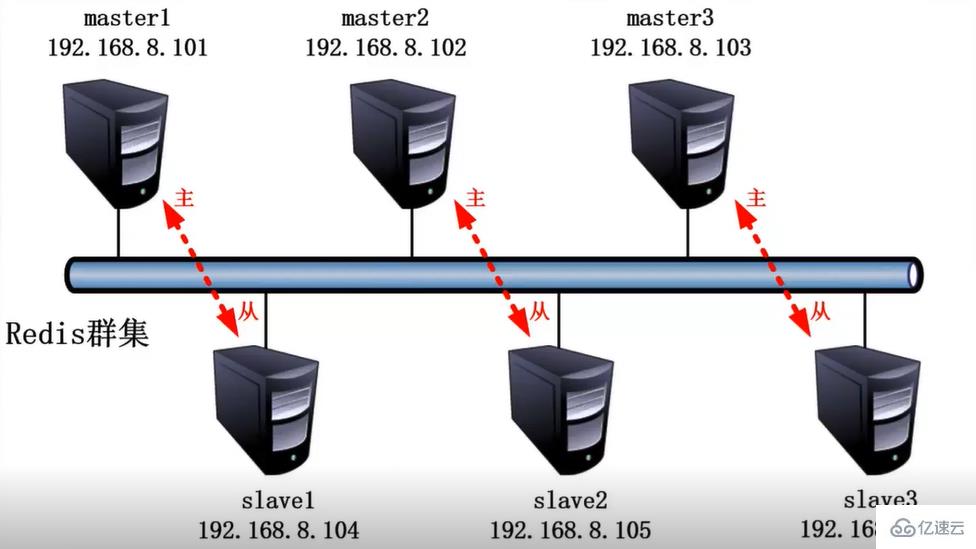
| 服务器 | 主机名 | IP | 主端口 | 从端口 |
|---|---|---|---|---|
| Node1节点 | node | 192.168.122.10 | 6001 | 6004 |
| Node2节点 | node | 192.168.122.10 | 6002 | 6005 |
| Node3节点 | node | 192.168.122.10 | 6003 | 6006 |
7.2 服务器防火墙环境
systemctl stop firewalld && systemctl disable firewalld setenforce 0
7.3 创建集群配置目录及文件
[root@node ~]# cd /etc/redis
[root@node redis]# mkdir -p redis-cluster/redis600{1..6}
[root@node redis]# for i in {1..6}
> do
> cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
> cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
> done
[root@node redis]# ls -R redis-cluster/
redis-cluster/:
redis6001 redis6002 redis6003 redis6004 redis6005 redis6006
redis-cluster/redis6001:
redis-cli redis.conf redis-server
redis-cluster/redis6002:
redis-cli redis.conf redis-server
redis-cluster/redis6003:
redis-cli redis.conf redis-server
redis-cluster/redis6004:
redis-cli redis.conf redis-server
redis-cluster/redis6005:
redis-cli redis.conf redis-server
redis-cluster/redis6006:
redis-cli redis.conf redis-server7.4 开启群集功能
仅以redis6001为例,其他5个文件夹的配置文件以此类推修改,特别注意端口号的修改。
[root@node redis]# cd redis-cluster/redis6001 [root@node redis6001]# vim redis.conf ##69行,注释掉bind项,默认监听所有网卡 #bind 127.0.0.1 ##88行,修改,关闭保护模式 protected-mode no ##92行,修改,redis监听端口 port 6001 ##136行,开启守护进程,以独立进程启动 daemonize yes ##832行,取消注释,开启群集功能 cluster-enabled yes ##840行,注销注释,群集名称文件设置 cluster-config-file nodes-6001.conf ##846行,注销注释,群集超时时间设置 cluster-node-timeout 15000 ##700行,修改,开启AOF持久化 appendonly yes
7.5 启动redis节点
分别进入那六个文件夹,执行命令:“redis-server redis.conf”,来启动redis节点
[root@node redis6001]# for d in {1..6}
> do
> cd /etc/redis/redis-cluster/redis600$i
> ^C
[root@node redis6001]# for d in {1..6}
> do
> cd /etc/redis/redis-cluster/redis600$d
> redis-server redis.conf
> done
[root@node1 redis6006]# ps -ef | grep redis
root 992 1 0 13:45 ? 00:00:07 /usr/local/redis/bin/redis-server 0.0.0.0:6379
root 2289 1 0 14:41 ? 00:00:00 redis-server *:6001 [cluster]
root 2294 1 0 14:41 ? 00:00:00 redis-server *:6002 [cluster]
root 2299 1 0 14:41 ? 00:00:00 redis-server *:6003 [cluster]
root 2304 1 0 14:41 ? 00:00:00 redis-server *:6004 [cluster]
root 2309 1 0 14:41 ? 00:00:00 redis-server *:6005 [cluster]
root 2314 1 0 14:41 ? 00:00:00 redis-server *:6006 [cluster]
root 2450 2337 0 14:50 pts/0 00:00:00 grep --color=auto redis7.6 启动集群
[root@node redis6006]# redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1
六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候需要输入yes才可以成功创建。
–replicas 1表示每个主节点有1个从节点。
7.7 测试集群
[root@node1 redis6006]# redis-cli -p 6001 -c
#加-c参数,节点之前就可以互相跳转
127.0.0.1:6001> cluster slots
#查看节点的哈希槽编号范围
1) 1) (integer) 0
#哈希槽起始编号
2) (integer) 5460
#哈希槽终止编号
3) 1) "127.0.0.1"
2) (integer) 6001
#node节点主
3) "18e59f493579facea29abf90ca4050f566d66339"
4) 1) "127.0.0.1"
2) (integer) 6004
#node节点从
3) "2635bf6a0c286ef910ec5da03dbdc7cde308c588"
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6003
3) "51460d417eb56537e5bd7e8c9581c66fdd817b3c"
4) 1) "127.0.0.1"
2) (integer) 6006
3) "51a75667dcf21b530e69a3242a3e9f81f577168d"
3) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 6002
3) "6381d68c06ddb7ac43c8f7d7b8da0644845dcd59"
4) 1) "127.0.0.1"
2) (integer) 6005
3) "375ad927116d3aa845e95ad5f0586306e7ff3a96"
127.0.0.1:6001> set num 1
OK
127.0.0.1:6001> get num
"1"
127.0.0.1:6001> keys *
1) "num"
127.0.0.1:6001> quit
[root@node1 redis6006]# redis-cli -p 6002 -c
127.0.0.1:6002> keys *
#6002端口无键值对
(empty list or set)
127.0.0.1:6002> get num
-> Redirected to slot [2765] located at 127.0.0.1:6001
"1"
#6002端口获取到num键位于6001端口,切换到6001端口并显示键值
127.0.0.1:6001> set key1 11111
-> Redirected to slot [9189] located at 127.0.0.1:6002
OK
#6001端口创建键值对,将其存至6002端口,并切换至6002端口
127.0.0.1:6002>위 내용은 Redis의 마스터-슬레이브 복제, 센트리 및 클러스터링 분석 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!