
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL의 분류 순위 분석 및 TOP N 그룹화 예시
MySQL의 분류 순위 분석 및 TOP N 그룹화 예시

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-28 23:10:041895검색
테이블 구조
학생 테이블은 다음과 같습니다.
CREATE TABLE `t_student` ( `id` int NOT NULL AUTO_INCREMENT, `t_id` int DEFAULT NULL COMMENT '学科id', `score` int DEFAULT NULL COMMENT '分数', PRIMARY KEY (`id`) );
데이터는 다음과 같습니다.
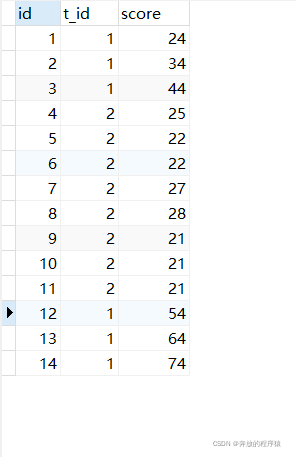
질문 1: 과목별 상위 5위 점수 획득(동점 허용)
동점 4번 등 업 상황은 허용됩니다. 5개의 결과가 동률일 경우 상위 4개는 5개의 데이터가 생성되고, 상위 5개도 5개의 데이터가 생성됩니다.
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5 ORDER BY s1.t_id, s1.score DESC
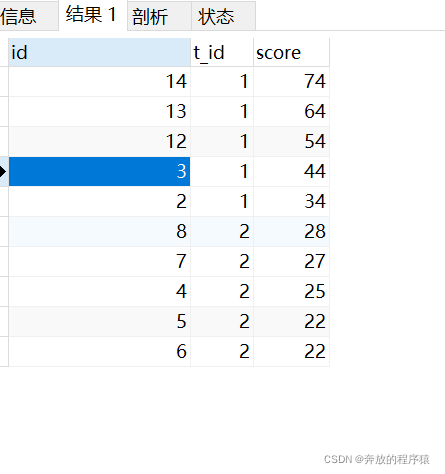
ps: 상위 4개
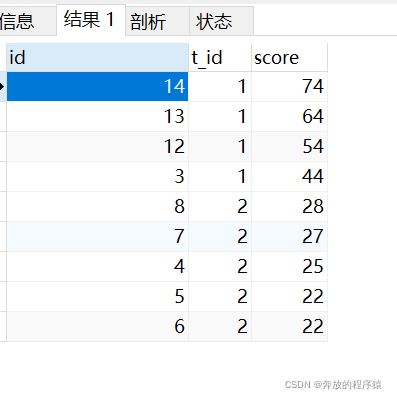
분석:
1 자체 왼쪽 외부 조인을 사용하여 왼쪽 값이 오른쪽 값보다 작은 모든 집합을 가져옵니다. t_id=1을 예로 들면 24는 그보다 5점 더 많고(74, 64, 54, 44, 34), 6위, 34는 그보다 4점만 더 많아, 5위… 그보다 크고 그는 첫 번째입니다.
SELECT * FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score
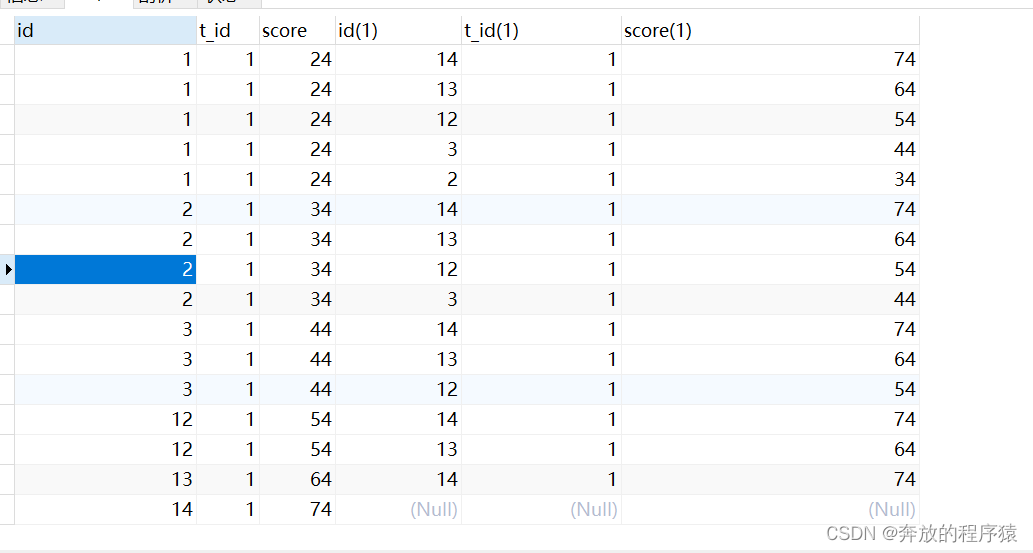
2. 요약된 규칙을 SQL로 변환하여 표현하는데, 이는 각 학생의 ID(s1.id)별로 그룹화되고, 이 ID 아래의 값이 그보다 얼마나 큰지에 대한 통계를 얻습니다( s2.id)
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5
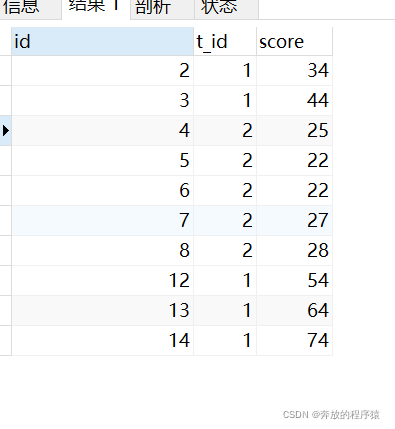
3. 마지막으로 t_id에 따라 분류하고 점수를 역순으로 정렬합니다.
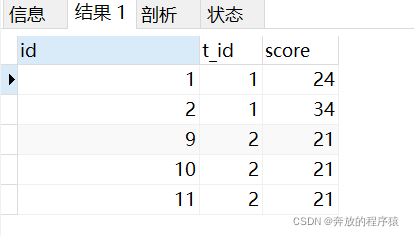
질문 2: 각 과목에서 마지막 두 학생의 평균 점수를 구하세요.
마지막 두 점수를 구하세요
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score
두 항목이 나란히 존재하는 경우 동일한 t_id로 필터링된 결과 수가 다음보다 커질 수 있습니다. 2, 그러나 질문에는 여러 번 평균을 낸 후에도 여전히 동일하므로 더 이상 처리할 필요가 없으며 이는 질문의 요구 사항을 충족할 수 있습니다. : 평균 그룹화: 求
SELECT t_id,AVG(score) FROM ( SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score ) tt GROUP BY t_id결과:
Rreeee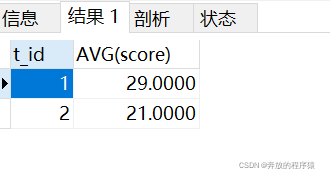
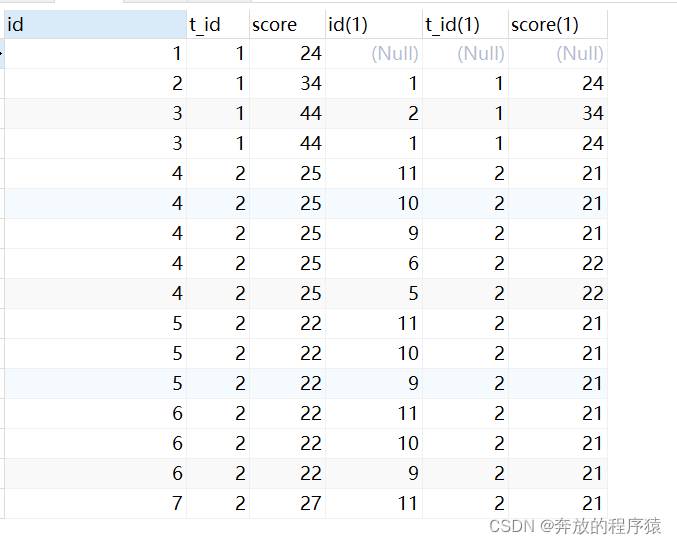 질문 3: 각 과목의 상위 5개 점수 순위를 가져옵니다(타이밍은 허용되지 않음)
질문 3: 각 과목의 상위 5개 점수 순위를 가져옵니다(타이밍은 허용되지 않음)
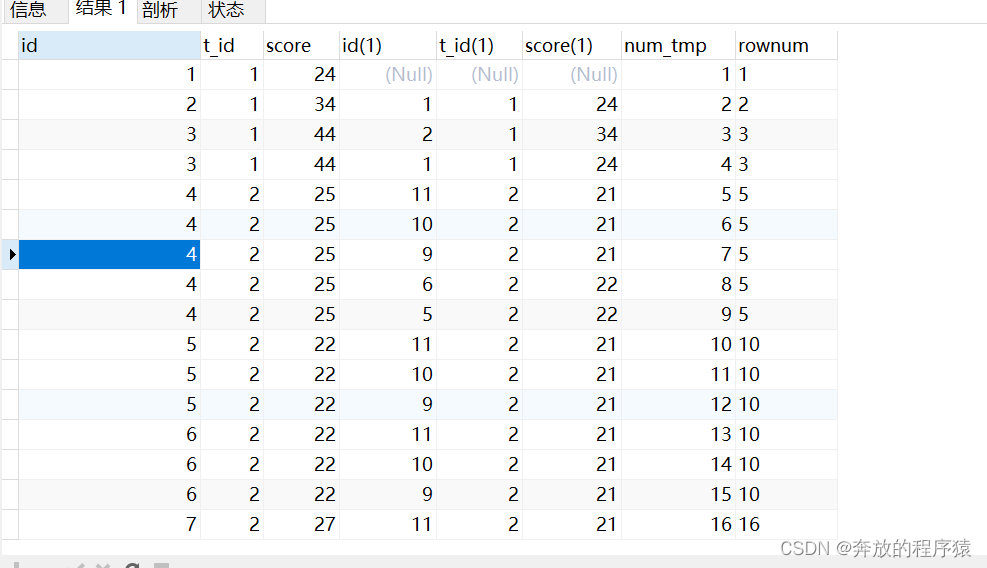
SELECT s1.*,s2.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score분석: 1 . 보조 매개변수 도입
SELECT * FROM ( SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC ) tt GROUP BY t_id, score, rownum HAVING COUNT( rownum )< 5
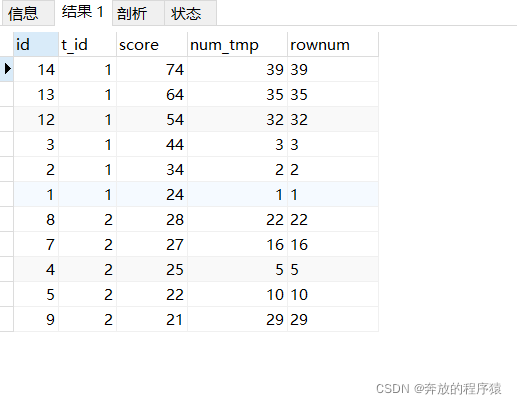 2. 중복된 s1.id 제거, 그룹화 및 정렬
2. 중복된 s1.id 제거, 그룹화 및 정렬 SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it
위 내용은 MySQL의 분류 순위 분석 및 TOP N 그룹화 예시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!