
Python에서 itertools 모듈을 사용하는 방법

- 王林앞으로
- 2023-05-28 15:41:581581검색
itertools — 효율적인 루프를 위한 반복자를 생성하는 함수
accumulate(iterable: Iterable, func: None,initial:None)
iterable: 작동해야 하는 반복 가능한 객체
func: 반복 가능한 객체에 필요 함수에는 두 개의 매개변수가 있어야 합니다.
initial: 누적의 시작 값
func를 사용하여 반복 가능한 객체에 대해 쌍안 연산을 수행하는 경우 두 개의 매개변수를 제공해야 합니다. 반환되는 것은 반복자입니다. functools의 축소는 둘 다 누적적으로 작동합니다. 차이점은 축소는 마지막 요소만 반환하는 반면, 누적은 중간 요소를 포함하여 모든 요소를 표시한다는 것입니다.
| Difference | reduce | accumulate |
|---|---|---|
| 반환 값은 | 요소를 반환 | 반복자(중간 처리된 요소 포함)를 반환 |
| 그것이 속한 모듈 | functools | itertools |
| 성능 | 약간 나쁩니다 | reduce보다 낫습니다 |
| 초기값 | 초기값을 설정할 수 있습니다 | 초기값을 설정할 수 있습니다 |
import time
from itertools import accumulate
from functools import reduce
l_data = [1, 2, 3, 4]
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(list(data))
start = time.time()
for i in range(100000):
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(time.time() - start)
start = time.time()
for i in range(100000):
data = reduce(lambda x, y: x + y, l_data)
print(time.time() - start)
#输出
[2, 3, 5, 8, 12]
0.027924537658691406
0.03989362716674805위 결과에서 알 수 있듯이, 누적은 감소보다 성능이 약간 더 좋고, 중간 처리 과정도 출력할 수 있습니다.
chain(*iterables)
iterables: 여러 반복 가능한 객체를 받습니다
여러 반복 가능한 객체의 요소를 차례로 반환합니다. 반환되는 것은 사전의 요소를 출력할 때 사전의 키가 출력됩니다. default
from itertools import chain
import time
list_data = [1, 2, 3]
dict_data = {"a": 1, "b": 2}
set_data = {4, 5, 6}
print(list(chain(list_data, dict_data, set_data)))
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
start = time.time()
for i in range(100000):
chain(list_data, list_data2)
print(time.time() - start)
start = time.time()
for i in range(100000):
list_data.extend(list_data2)
print(time.time() - start)
#输出
[1, 2, 3, 'a', 'b', 4, 5, 6]
0.012955427169799805
0.013965129852294922조합(iterable: Iterable, r)
iterable: 연산이 필요한 iterable 객체
r: 추출된 하위 시퀀스 요소의 수
iterable 객체를 연산하고 하위 시퀀스 수에 따라 하위 시퀀스를 반환합니다. 하위 시퀀스의 요소도 순서가 지정되고 반복 불가능하며 튜플 형식으로 표시됩니다.
from itertools import combinations data = range(5) print(tuple(combinations(data, 2))) str_data = "asdfgh" print(tuple(combinations(str_data, 2))) #输出 ((0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)) (('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'g'), ('f', 'h'), ('g', 'h'))
combinations_with_replacement(iterable: Iterable, r)
은 위의 조합(iterable: Iterable, r)과 유사하지만, 차이점은 Combinations_with_replacement의 하위 시퀀스 요소가 반복될 수 있고 다음과 같이 순서가 지정된다는 점입니다.
from itertools import combinations_with_replacement data = range(5) print(tuple(combinations_with_replacement(data, 2))) str_data = "asdfgh" print(tuple(combinations_with_replacement(str_data, 2))) #输出 ((0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4)) (('a', 'a'), ('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 's'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'd'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'f'), ('f', 'g'), ('f', 'h'), ('g', 'g'), ('g', 'h'), ('h', 'h'))
압축(데이터: Iterable, 선택기: Iterable)
data: 작동해야 하는 반복 가능한 객체
selectors: 참값을 결정하는 반복 가능한 객체, str일 수 없으며 가급적이면 목록, 튜플 등이 될 수 없습니다.
에 따라 선택기의 요소가 true인지 여부는 데이터의 해당 인덱스 요소 중 가장 짧은 요소를 출력하고 반복자를 반환합니다.
from itertools import compress data = "asdfg" list_data = [1, 0, 0, 0, 1, 4] print(list(compress(data, list_data))) #输出 ['a', 'g']
count(start, step)
start: 시작 요소
step: 요소가 처음부터 성장하는 단계
증가하는 반복자를 생성하며, 시작점은 start이고 증분 단계는 주어진 것입니다. value, no 모든 요소는 즉시 생성됩니다. 요소를 재귀적으로 가져오려면 next() 메서드를 사용하는 것이 좋습니다.
from itertools import count c = count(start=10, step=20) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(c) #输出 10 30 50 70 count(90, 20)
cycle(iterable)
iterable: 루프
로 출력해야 하는 반복 가능한 개체입니다. 반복자를 반환하고 반복 가능한 개체의 요소를 반복합니다. count와 마찬가지로 결과를 반복 가능한 객체로 변환하지 않는 것이 가장 좋습니다. 요소를 얻으려면 next() 또는 for 루프를 사용하는 것이 좋습니다.
from itertools import cycle a = "asdfg" data = cycle(a) print(next(data)) print(next(data)) print(next(data)) print(next(data)) #输出 a s d f
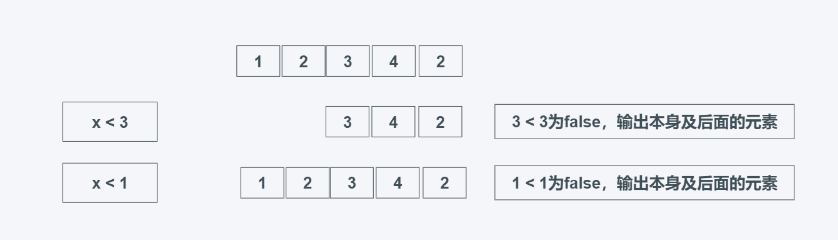
dropwhile(predicate, iterable)
predicate: 요소 삭제 여부에 대한 기준
iterable: 반복 가능한 객체
predicate의 계산 결과를 필터링하여 반복자를 반환하고 해당 계산 결과를 이 반복기에서 삭제합니다. 진실. 다음 요소가 True 또는 False인지 관계없이 조건자가 False인 경우 출력됩니다.
from itertools import dropwhile list_data = [1, 2, 3, 4, 5] print(list(dropwhile(lambda i: i < 3, list_data))) print(list(dropwhile(lambda x: x < 5, [1, 4, 6, 4, 1]))) #输出 [3, 4, 5] [6, 4, 1]
filterfalse(predicate, iterable)
predicate: 요소를 삭제할지 여부에 대한 기준
iterable: 반복 가능한 객체
는 각 요소에 대한 작업을 수행하기 전에 조건자 조건을 만족하는지 확인하는 반복자를 생성합니다. filter 방식과 유사하지만 filter의 반대입니다.
import time
from itertools import filterfalse
print(list(filterfalse(lambda i: i % 2 == 0, range(10))))
start = time.time()
for i in range(100000):
filterfalse(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
start = time.time()
for i in range(100000):
filter(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
#输出
[1, 3, 5, 7, 9]
0.276653528213501
0.2768676280975342위 결과를 보면 filterfalse와 filter의 성능이 크게 다르지 않음을 알 수 있습니다
groupby(iterable, key=None)
iterable: iterable 객체
key: 선택 가능, 요소에서 판단해야 할 조건, 기본값은 x == x입니다.
키(키 조건을 충족하는 연속 요소)에 따라 연속 키와 그룹을 반환하는 반복자를 반환합니다.
groupby를 사용하여 그룹화하기 전에 정렬이 필요하다는 점에 유의하세요.
from itertools import groupby
str_data = "babada"
for k, v in groupby(str_data):
print(k, list(v))
str_data = "aaabbbcd"
for k, v in groupby(str_data):
print(k, list(v))
def func(x: str):
print(x)
return x.isdigit()
str_data = "12a34d5"
for k, v in groupby(str_data, key=func):
print(k, list(v))
#输出
b ['b']
a ['a']
b ['b']
a ['a']
d ['d']
a ['a']
a ['a', 'a', 'a']
b ['b', 'b', 'b']
c ['c']
d ['d']
1
2
a
True ['1', '2']
3
False ['a']
4
d
True ['3', '4']
5
False ['d']
True ['5']islice(iterable, stop)islice(iterable, start, stop[, step])
iterable: 연산이 필요한 반복 가능한 객체
start: 연산이 시작되는 인덱스 위치
stop: 인덱스 작업이 끝나는 위치
step: 단계 크기
반복자를 반환합니다. 슬라이싱과 유사하지만 해당 인덱스는 음수를 지원하지 않습니다.
from itertools import islice
import time
list_data = [1, 5, 4, 2, 7]
#学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
start = time.time()
for i in range(100000):
data = list_data[:2:]
print(time.time() - start)
start = time.time()
for i in range(100000):
data = islice(list_data, 2)
print(time.time() - start)
print(list(islice(list_data, 1, 3)))
print(list(islice(list_data, 1, 4, 2)))
#输出
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]위 결과를 보면 슬라이싱 성능이 islice 성능보다 조금 더 나은 것을 알 수 있습니다.
pairwise(iterable)
연산이 필요한 반복 가능한 객체
반복 가능한 객체에 연속적으로 겹치는 쌍이 2개 미만인 경우 비어 있는 값을 반환하는 반복자를 반환합니다.
from itertools import pairwise str_data = "asdfweffva" list_data = [1, 2, 5, 76, 8] print(list(pairwise(str_data))) print(list(pairwise(list_data))) #输出 [('a', 's'), ('s', 'd'), ('d', 'f'), ('f', 'w'), ('w', 'e'), ('e', 'f'), ('f', 'f'), ('f', 'v'), ('v', 'a')] [(1, 2), (2, 5), (5, 76), (76, 8)]
permutations(iterable, r=None)
iterable: 연산이 필요한 반복 가능한 객체
r: 추출된 하위 시퀀스
는 모두 반복 가능한 객체의 하위 시퀀스입니다. 반복되고 순서가 지정되지 않으며 조합_교체_와 정반대입니다.
from itertools import permutations data = range(5) print(tuple(permutations(data, 2))) str_data = "asdfgh" print(tuple(permutations(str_data, 2))) #输出 ((0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3)) (('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'a'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'a'), ('d', 's'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'a'), ('f', 's'), ('f', 'd'), ('f', 'g'), ('f', 'h'), ('g', 'a'), ('g', 's'), ('g', 'd'), ('g', 'f'), ('g', 'h'), ('h', 'a'), ('h', 's'), ('h', 'd'), ('h', 'f'), ('h', 'g'))
product(*iterables,peat=1)
iterables: 다중일 수 있는 반복 가능한 객체
repeat: 반복 가능한 객체의 반복 횟수, 즉 복사본 수
반복자를 반환합니다. 유사한 순열과 조합은 데카르트 곱의 반복 가능한 객체를 생성합니다. 제품 기능은 zip 기능과 유사하지만 zip은 요소를 일대일로 일치시키는 반면 제품은 일대다 관계를 만듭니다.
from itertools import product list_data = [1, 2, 3] list_data2 = [4, 5, 6] print(list(product(list_data, list_data2))) print(list(zip(list_data, list_data2))) # 如下两个含义是一样的,都是将可迭代对象复制一份, 很方便的进行同列表的操作 print(list(product(list_data, repeat=2))) print(list(product(list_data, list_data))) # 同上述含义 print(list(product(list_data, list_data2, repeat=2))) print(list(product(list_data, list_data2, list_data, list_data2))) #输出 [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)] [(1, 4), (2, 5), (3, 6)] [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)] [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)] [(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)] [(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
repeat(object[, times])
object: 모든 합법적인 객체
times: 선택사항, 객체 객체가 생성되는 횟수. times이 전달되지 않으면 무한히 반복됩니다.
반복자를 반환합니다. , 시간에 따라 반복 객체 객체를 생성합니다.
from itertools import repeat
str_data = "assd"
print(repeat(str_data))
print(list(repeat(str_data, 4)))
list_data = [1, 2, 4]
print(repeat(list_data))
print(list(repeat(list_data, 4)))
dict_data = {"a": 1, "b": 2}
print(repeat(dict_data))
print(list(repeat(dict_data, 4)))
#输出
repeat('assd')
['assd', 'assd', 'assd', 'assd']
repeat([1, 2, 4])
[[1, 2, 4], [1, 2, 4], [1, 2, 4], [1, 2, 4]]
repeat({'a': 1, 'b': 2})
[{'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}]starmap(function, iterable)
function: 범위가 지정된 반복자 객체의 요소 함수
iterable: 반복 가능 객체
는 반복자를 반환하고 반복 가능 객체의 모든 요소에 함수를 적용합니다(모든 요소는 Iterable이어야 합니다) 객체는 값이 하나만 있는 경우에도 map 함수와 유사하게 반복 가능한 객체(예: tuple (1, ))로 래핑해야 합니다. 함수 매개변수가 반복 가능한 객체의 요소와 일치하는 경우 다음을 사용하세요. 요소 대신 튜플을 사용합니다(예: [(2,3), (3,3)]에 해당하는 pow(a, b)).
map과 starmap의 차이점은 map은 일반적으로 함수에 매개변수가 하나만 있을 때 작동하는 반면, starmap은 함수에 매개변수가 여러 개 있을 때 작동할 수 있다는 것입니다.
from itertools import starmap
list_data = [1, 2, 3, 4, 5]
list_data2 = [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]
list_data3 = [(1,), (2,), (3,), (4,), (5,)]
print(list(starmap(lambda x, y: x + y, list_data2)))
print(list(map(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data3)))
#输出
[2, 4, 6, 8, 10]
[1, 4, 9, 16, 25]
Traceback (most recent call last):
File "c:\Users\ts\Desktop\2022.7\2022.7.22\test.py", line 65, in <module>
print(list(starmap(lambda x: x * x, list_data)))
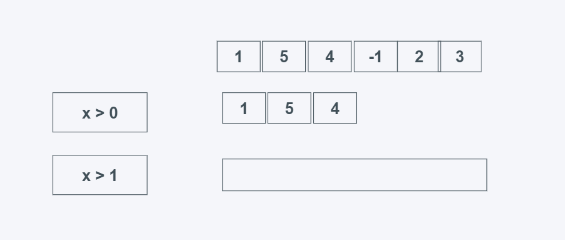
TypeError: 'int' object is not iterabletakewhile(predicate, iterable)
predicate:判断条件,为真就返回
iterable: 可迭代对象
当predicate为真时返回元素,需要注意的是,当第一个元素不为True时,则后面的无论结果如何都不会返回,找的前多少个为True的元素。
from itertools import takewhile #学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078 list_data = [1, 5, 4, 6, 2, 3] print(list(takewhile(lambda x: x > 0, list_data))) print(list(takewhile(lambda x: x > 1, list_data)))
zip_longest(*iterables, fillvalue=None)
iterables:可迭代对象
fillvalue:当长度超过时,缺省值、默认值, 默认为None
返回迭代器, 可迭代对象元素一一对应生成元组,当两个可迭代对象长度不一致时,会按照最长的有元素输出并使用fillvalue补充,是zip的反向扩展,zip为最小长度输出。
from itertools import zip_longest list_data = [1, 2, 3] list_data2 = ["a", "b", "c", "d"] print(list(zip_longest(list_data, list_data2, fillvalue="-"))) print(list(zip_longest(list_data, list_data2))) print(list(zip(list_data, list_data2))) [(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')] [(1, 'a'), (2, 'b'), (3, 'c'), (None, 'd')] [(1, 'a'), (2, 'b'), (3, 'c')]
总结
accumulate(iterable: Iterable, func: None, initial:None):
进行可迭代对象元素的累计运算,可以设置初始值,类似于reduce,相比较reduce,accumulate可以输出中间过程的值,reduce只能输出最后结果,且accumulate性能略好于reduce。
chain(*iterables)
依次输出迭代器中的元素,不会循环输出,有多少输出多少。当输出字典元素时,默认会输出字典的键;而对于列表,则相当于使用extend函数。
combinations(iterable: Iterable, r):
抽取可迭代对象的子序列,其实就是排列组合,不过只返回有序、不重复的子序列,以元组形式呈现。
combinations_with_replacement(iterable: Iterable, r)
类似于combinations,从可迭代对象中提取子序列,但是返回的子序列是无序且不重复的,以元组的形式呈现。
compress(data: Iterable, selectors: Iterable)
根据selectors中的元素是否为True或者False返回可迭代对象的合法元素,selectors为str时,都为True,并且只会决定长度。
count(start, step):
从start开始安装step不断生成元素,是无限循环的,最好控制输出个数或者使用next(),send()等获取、设置结果
cycle(iterable)
循环输出可迭代对象的元素,相当于对chain函数进行无限循环。建议控制输出数据的数量,或使用next()、send()等函数获取或设置返回结果。
dropwhile(predicate, iterable)
根据predicate是否为False来返回可迭代器元素,predicate可以为函数, 返回的是第一个False及之后的所有元素,不管后面的元素是否为True或者False。这个函数适用于舍弃迭代器或可迭代对象的开头部分,比如在写入文件时忽略文档注释
filterfalse(predicate, iterable)
类似于filter方法,返回所有满足predicate条件的元素,作为一个可迭代对象。
groupby(iterable, key=None)
输出连续符合key要求的键值对,默认为x == x。
islice(iterable, stop)\islice(iterable, start, stop[, step])
对可迭代对象进行切片,和普通切片类似,但是这个不支持负数。这种方法适用于迭代对象的切片,比如你需要获取文件中的某几行内容
pairwise(iterable)
返回连续的重叠对象(两个元素), 少于两个元素返回空,不返回。
permutations(iterable, r=None)
从可迭代对象中抽取子序列,与combinations类似,不过抽取的子序列是无序、可重复。
product(*iterables, repeat=1)
输出可迭代对象的笛卡尔积,类似于排序组合,不可重复,是两个或者多个可迭代对象进行操作,当是一个可迭代对象时,则返回元素,以元组形式返回。
repeat(object[, times])
重复返回object对象,默认时无限循环
starmap(function, iterable)
批量操作可迭代对象中的元素,操作的可迭代对象中的元素必须也要是可迭代对象,与map类似,但是可以对类似于多元素的元组进行操作。
takewhile(predicate, iterable)
返回前多少个predicate为True的元素,如果第一个为False,则直接输出一个空。
zip_longest(*iterables, fillvalue=None)
将可迭代对象中的元素一一对应,组成元组形式存储,与zip方法类似,不过zip是取最短的,而zip_longest是取最长的,缺少的使用缺省值。
위 내용은 Python에서 itertools 모듈을 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!