
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL에서 문자열 필드를 인덱싱하는 방법
MySQL에서 문자열 필드를 인덱싱하는 방법

- 王林앞으로
- 2023-05-28 14:38:522622검색
현재 이메일 로그인을 지원하는 시스템을 유지 관리하고 있다고 가정해 보겠습니다. 사용자 테이블은 다음과 같이 정의됩니다.
create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
로그인하려면 이메일을 사용해야 하므로 비즈니스 코드에는 분명히 다음과 유사한 명령문이 있을 것입니다.
select f1, f2 from SUser where email='xxx';
이메일 필드가 인덱스 없음인 경우 이 명령문은 전체 테이블 스캔만 수행할 수 있습니다.
1) 이메일 주소 필드에 색인을 만들 수 있나요?
MySQL은 접두어 인덱스를 지원하므로 문자열의 일부를 인덱스로 정의할 수 있습니다
2) 인덱스를 생성하는 문에서 접두어 길이를 지정하지 않으면 어떻게 되나요?
색인에는 전체 문자열이 포함됩니다
3) 설명할 수 있는 예를 들어주실 수 있나요?
alter table SUser add index index1(email); 或 alter table SUser add index index2(email(6));
index1 인덱스는 각 레코드의 전체 문자열을 포함합니다.
index2 인덱스는 각 레코드의 처음 6바이트만 가져옵니다.
4) 이 두 가지 데이터 구조의 서로 다른 정의와 차이점은 무엇입니까? 저장?
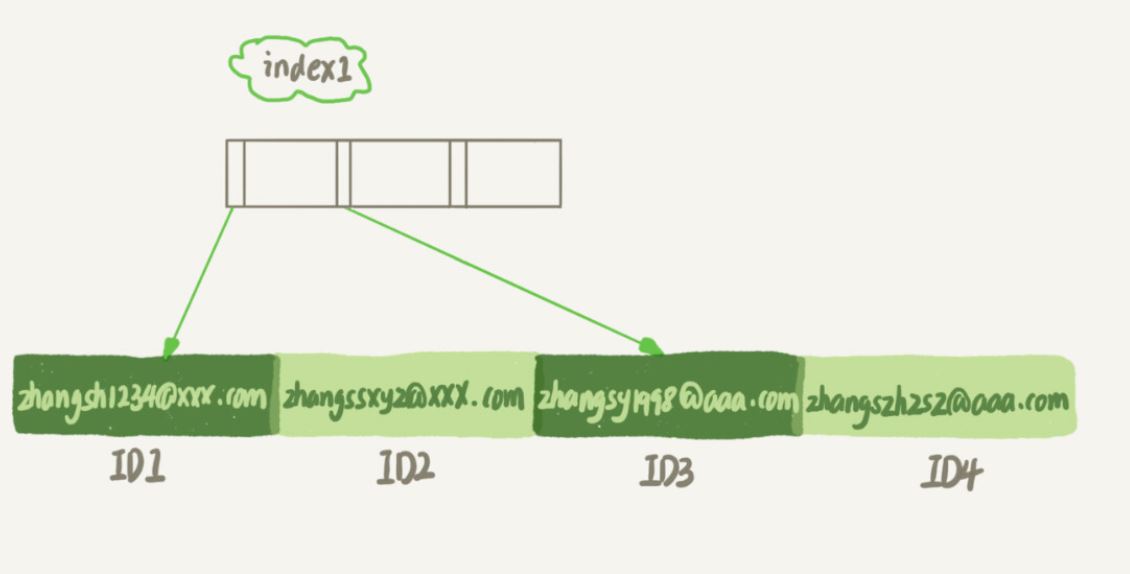
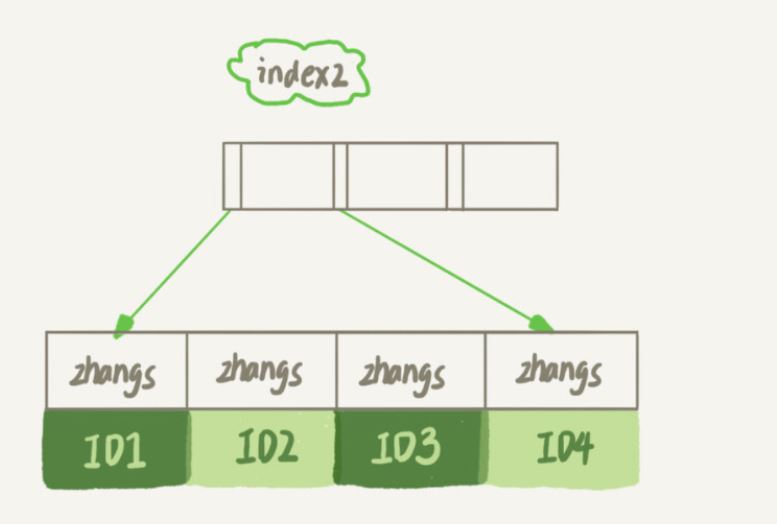
email(6) 인덱스 구조가 공간을 덜 차지할 것은 분명합니다
5) email(6) 인덱스 구조에 단점이 있나요?
추가 레코드 검색 횟수가 늘어날 수 있습니다.
6) 이 두 인덱스 정의에서 다음 명령문은 어떻게 실행됩니까?
select id,name,email from SUser where email='zhangssxyz@xxx.com';
index1(즉, 이메일 전체 문자열의 인덱스 구조), 실행 순서
-
는 index1 인덱스 트리에서 ’zhangssxyz@xxx.com’ 그리고 ID2의 값을 얻습니다.
-
테이블로 돌아가서 기본 키 값이 ID2인 행을 찾아 이메일의 값이 올바른지 판단하고 이 레코드 행을 결과 집합에 추가합니다.
인덱스 인덱스 트리의 다음 레코드로 계속 진행하여 이메일이 더 이상 ='zhangssxyz@xxx.com’ 조건을 충족하지 않는 것을 확인하면 루프가 종료됩니다. - 이 과정에서는 기본 키 인덱스에서 데이터를 한 번만 검색하면 되므로 시스템에서는 한 행만 스캔된 것으로 간주합니다.
- 입니다. 기본키로 기본키 값이 ID1인 행이 발견되어 이메일의 값이 ’zhangssxyz@xxx.com’이 아닌 것으로 판단되어 이 레코드 행을 폐기합니다.
- Get 다음; 방금 index2에서 찾은 위치 기록을 확인하고 여전히 'zhangs'인 것을 확인하고 ID2를 꺼낸 다음 ID 색인에서 전체 행을 가져와 판단합니다. 이번에는 값이 정확합니다. 이 레코드 행을 result set;
- idxe2에서 얻은 값이 'zhangs'가 아닐 때까지 이전 단계를 반복합니다. 사이클이 종료됩니다.
- 이 과정에서는 기본 키 인덱스를 4번 검색해야 합니다. 즉, 4개의 행을 검색해야 합니다.
7) 위의 비교를 통해 어떤 결론을 내릴 수 있나요?
Prefix Index를 사용한 후에는 쿼리문이 데이터를 읽는 횟수가 늘어날 수 있습니다.
- 8) 접두사 색인은 정말 쓸모가 없나요?
우리가 정의한 index2가 email(6)이 아니고 email(7)이라면, 접두사 ’zhangss’를 만족하는 레코드는 단 하나뿐이고, ID2를 직접 찾아서 한 줄만 스캔하게 됩니다.
- 9) 그렇다면 Prefix Index 사용 시 주의사항은 무엇인가요?
길이를 합리적으로 선택하세요
- 10) 문자열에 대한 접두어 인덱스를 생성할 때 접두어 인덱스의 길이를 어떻게 알 수 있나요?
인덱스에 얼마나 많은 값이 있는지 세어 접두사의 길이를 결정하세요.
- 11) 인덱스에 몇 개의 서로 다른 값이 있는지 계산하는 방법은 무엇입니까?
select count(distinct email) as L from SUser;12) 인덱스에 해당하는 서로 다른 값을 몇 개나 구한 후 다음에는 무엇을 해야 할까요?
길이가 다른 접두어를 차례로 선택하여 값을 확인하세요
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
다음 SQL 문:
select id,email from SUser where email='zhangssxyz@xxx.com';이전 예의 SQL 문
select id,name,email from SUser where email='zhangssxyz@xxx.com';과 비교하면 첫 번째 문에는 id 및 email 필드만 반환하면 됩니다. index1(즉, 이메일 전체 문자열의 인덱스 구조)을 사용하면 이메일을 확인하여 ID를 얻을 수 있으며, 그러면 테이블을 반환할 필요가 없습니다.
用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
14)那我把index2 的定义修改为 email(18) 的前缀索引不就行了?
这个18是你自己定义的,系统不知道18这个长度是否已经大于我的email长度,所以它还是会回表去查一下验证。
总而言之:使用前缀索引就用不上覆盖索引对查询性能的优化了
针对类似于邮箱这样的字段,使用前缀索引可能会产生不错的效果。但是,遇到身份证这种前缀的区分度不够好的情况时,我们要怎么办呢?
索引选取的要更长一些。
但是所以越长的话,占的磁盘空间更大,相同的一页能放下的索引值就变少了,反而会影响查询效率。
16)如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
-
既然正过来相同的多,那我就把它倒过来存。查询时候这样查
select field_list from t where id_card = reverse('input_id_card_string');
使用 的时候用count(distinct) 方法去做个验证
-
使用 hash 字段。在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
新记录插入时必须使用 crc32() 函数生成校验码,并填入新字段中。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节(int类型),比原来小了很多
17)使用倒序存储和使用 hash 字段这两种方法有什么异同点?
相同点:都不支持范围查询
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
区别
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。以仅考虑这两个函数的计算复杂度为前提,reverse 函数对 CPU 资源的额外消耗将较少。
就查询性能而言,采用哈希字段方式的查询更具可靠性。虽然crc32算法不可避免地存在冲突的风险,但这种风险极其微小,因此我们可以认为查询时平均扫描行数接近于1。使用倒序存储方式仍然需要使用前缀索引来进行扫描,因此会增加扫描的行数。
案例:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
学生必须输入正确的登录名和密码,方可继续使用系统。如果只考虑登录验证这个行为,你会如何为登录名设计索引?
如果一个学校每年预计2万新生,50年才100万记录,如果直接使用全字段索引,可以节省多少存储空间?。除非遇到超大规模数据,否则不需要使用后两种方法,从而避免了开发转换和限制风险
在实际操作中,只需对所有字段进行索引,一个学校的数据库数据量和查询负担不会变得很大。 如果单从优化数据表的角度: \1. 后缀@gmail可以单独一个字段来存,或者用业务代码来保证, \2. 城市编号和学校编号估计也不会变,也可以用业务代码来配置 \3. 然后直接存年份和顺序编号就行了,这个字段可以全字段索引
위 내용은 MySQL에서 문자열 필드를 인덱싱하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!