
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 상세 인덱스 실패 사례 분석
MySQL 상세 인덱스 실패 사례 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-28 13:17:431502검색
인덱스의 저장 구조
우선, 인덱스의 저장 구조를 이해해 봅시다. 인덱스의 저장 구조를 알아야만 인덱스 실패 문제를 더 잘 이해할 수 있습니다.
인덱스의 저장 구조는 MySQL 저장 엔진과 관련이 있습니다. 다양한 저장 엔진은 서로 다른 구조를 사용합니다.
MySQL의 기본 스토리지 엔진 InnoDB는 인덱스 데이터 구조로 B+Tree를 사용합니다. 테이블을 생성할 때 InnoDB는 기본적으로 클러스터형 인덱스인 기본 키 인덱스를 생성하고 다른 인덱스는 보조 인덱스입니다.
MyISAM 스토리지 엔진은 테이블 생성 시 기본적으로 B+ 트리 인덱스를 사용합니다.
둘 다 InnoDB와 같은 B+ 트리 인덱스를 지원하지만 서로 다른 방식으로 데이터를 저장합니다.
InnoDB는 클러스터형 인덱스입니다(B+ 트리 인덱스의 리프 노드는 데이터 자체를 저장합니다).
MyISAM은 비클러스터형 인덱스입니다( B+ 트리의 잎 노드가 데이터를 저장하는 물리적 주소)
아래 그림과 같이
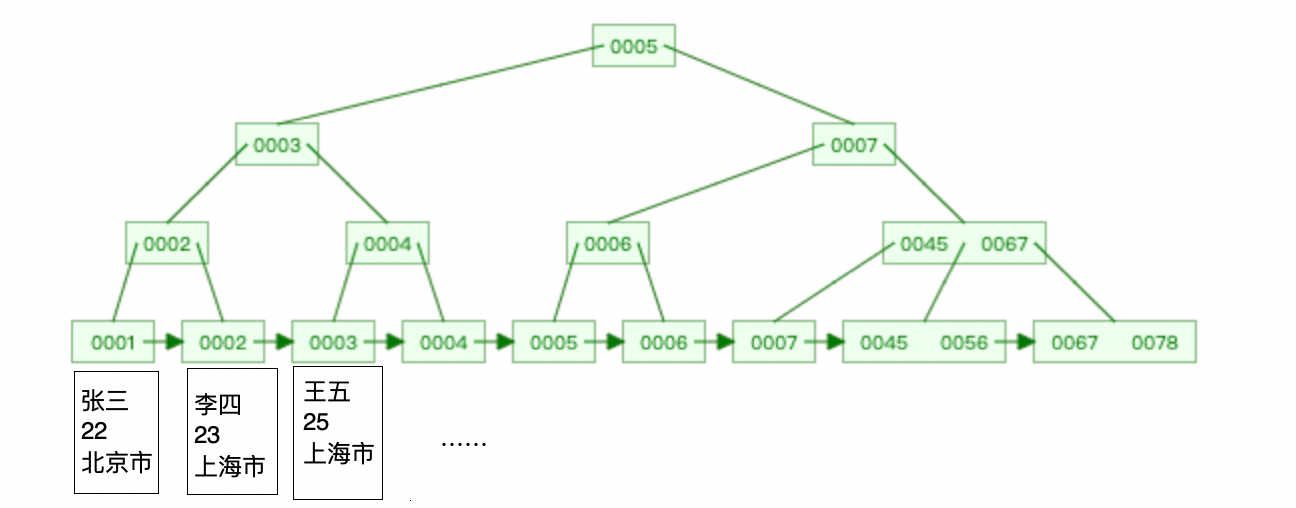
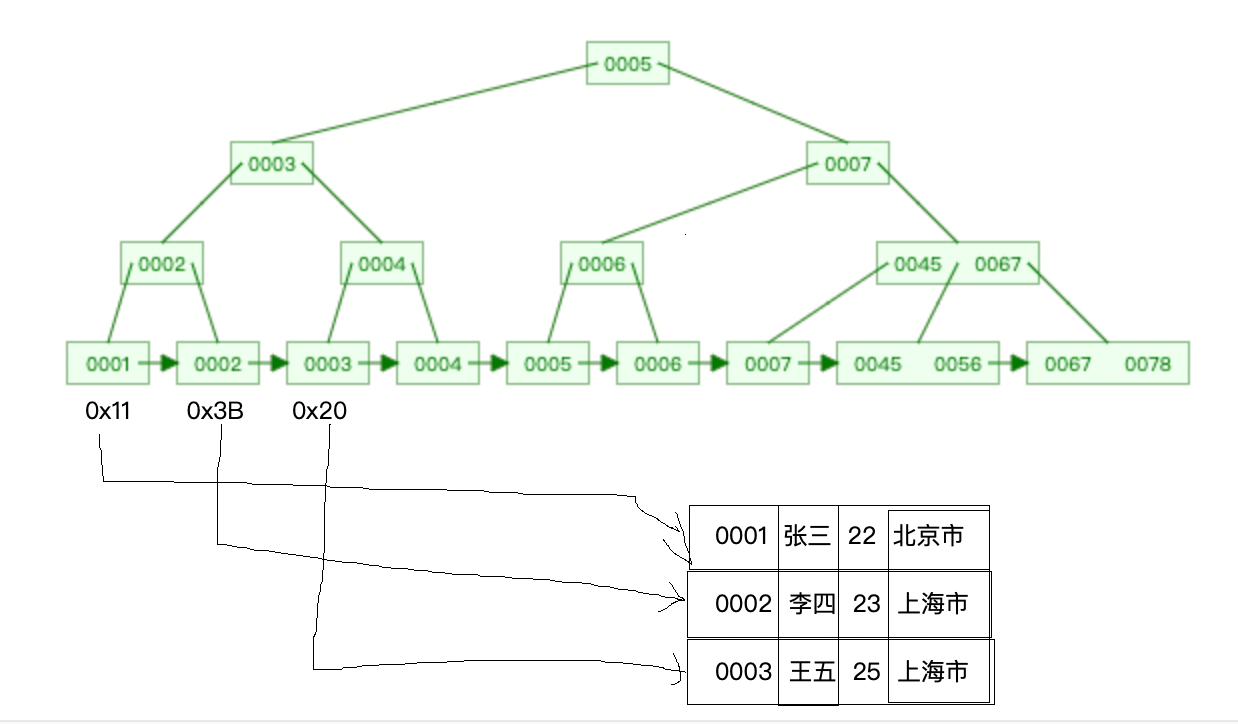
InnoDB 스토리지 엔진은 [클러스터형 인덱스]와 [보조 인덱스]로 나눌 수 있습니다. 이들 사이의 차이점은 클러스터형 인덱스의 리프 노드에 있으며, 모든 완전한 데이터는 클러스터형 인덱스의 리프 노드에 저장되며, 보조 인덱스의 리프 노드는 기본 키 값을 저장합니다.
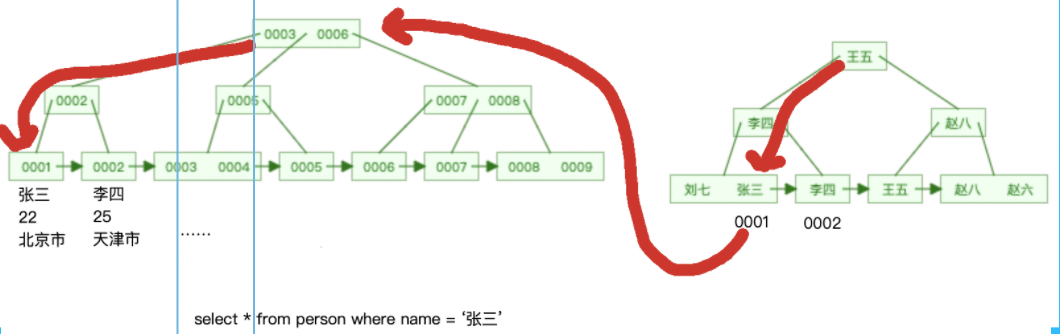
보조 인덱스 필드를 쿼리 조건으로 사용하고 클러스터형 인덱스의 데이터를 쿼리할 때
먼저 보조 인덱스에서 해당 리프 노드를 찾아 조건에 따라 기본 키 값을 얻은 다음
다음에 따라 기본 키 값은 클러스터형 인덱스로 이동하여 해당 리프 노드를 찾은 후 해당 데이터를 쿼리합니다.
이 프로세스는 테이블로 다시 호출됩니다.
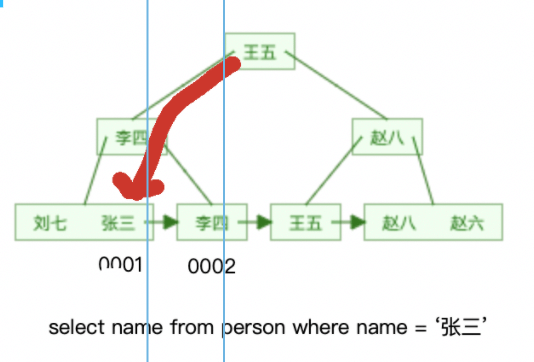
보조 인덱스를 쿼리 조건으로 사용하고 쿼리된 데이터를 사용합니다. 2차 인덱스의 리프 노드에 있음 업로드 시 2차 인덱스의 B+ 트리에 해당하는 리프 노드를 찾아 데이터를 읽어오기만 하면 됩니다. 이 과정을 커버링 인덱스라고 합니다
위 쿼리 조건은 모두 인덱스 컬럼을 사용한다고 해서 반드시 사용되는 것은 아닙니다. 인덱스 컬럼 인덱스는 반드시 적용됩니다. 인덱스 실패 상황을 다시 살펴보겠습니다
불합리한 퍼지 쿼리 조건
왼쪽 또는 왼쪽 퍼지 쿼리를 사용할 때, like "% Zhang" 또는 like "%张%" 이 두 가지 퍼지 쿼리 방법은 인덱스 오류를 발생시킵니다like "%张"或like "%张%"这两种模糊查询方式都会导致索引失效
因为B+树是根据索引值进行排列的,前缀不确定的时候可能是,“小张”,"二张"之类的所有的情况,就只能通过全表扫描的方式来查询
对索引使用函数
例如:SELECT * FROM sys_user WHERE LENGTH(user_id) = 3 ;

因为索引保存的是索引字段的原始值,而不是经过函数计算后的值,所以使用函数的时候就不会走索引了
不过从MySQL8.0开始,索引特性增加了函数索引,也就是针对该函数计算后的值建立一个索引,这样就可以通过扫描索引来查询数据了;
alter table t_user add key idx_name_length ((length(name)));
对索引进行表达式计算
例如:select * from sys_user where user_id+1 =3;

但是如果是SELECT * FROM sys_user WHERE user_id = 1+1 ;这样的不在索引字段上进行计算,就又会走索引了

原因跟对索引使用函数差不多,索引保存的是索引字段的原始值,而不是运算后的值,所以无法走索引
对索引使用隐式转换
这里的phone字段是二级索引,且是varchar类型的


使用整型作为查询参数的时候,执行计划中type为ALL,也就是通过全表扫描查询的,但如果是字符串类型,还是走索引查询的
我们再看一个例子
这里user_id
 인덱스에 함수를 사용하세요
인덱스에 함수를 사용하세요
SELECT * FROM sys_user WHERE LENGTH(user_id) = 3;🎜🎜🎜🎜 인덱스는 함수에서 계산한 값이 아닌 인덱스 필드의 원래 값을 저장하기 때문에 함수 사용 시 인덱스는 사용되지 않습니다. 하지만 MySQL 8.0부터, 인덱스 기능은 인덱스를 생성하는 함수 인덱스를 추가하므로 인덱스를 스캔하여 데이터를 쿼리할 수 있습니다. 🎜SELECT * FROM sys_user WHERE phone = 18200000000 ;🎜 인덱스에 대한 표현식 계산을 수행합니다🎜🎜예:
select; * sys_user에서 user_id+1 =3; code>🎜🎜<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168525107040754.png" class="lazy" alt="인스턴스 분석 MySQL 세부 정보의 인덱스 오류">🎜 🎜그러나 <code>SELECT * FROM sys_user WHERE user_id = 1+1;가 인덱스 필드에서 계산되지 않으면 인덱스가 다시 사용됩니다🎜🎜🎜🎜이유는 에서 함수를 사용하는 것과 비슷합니다. 인덱스는 인덱스 필드를 저장합니다. 계산된 값이 아닌 원래 값이므로 인덱스를 사용할 수 없습니다🎜🎜인덱스에 암시적 변환을 사용하세요🎜🎜여기서 phone 필드는 보조 인덱스이며 다음과 같습니다. varchar 유형🎜🎜🎜🎜  🎜🎜정수를 쿼리로 사용하는 경우 매개 변수, 실행 계획의 유형은 ALL, 즉 전체 테이블 스캔을 통해 쿼리되지만 문자열 유형인 경우 여전히 인덱스로 쿼리됩니다 🎜🎜 다른 예를 살펴 보겠습니다 🎜🎜여기
🎜🎜정수를 쿼리로 사용하는 경우 매개 변수, 실행 계획의 유형은 ALL, 즉 전체 테이블 스캔을 통해 쿼리되지만 문자열 유형인 경우 여전히 인덱스로 쿼리됩니다 🎜🎜 다른 예를 살펴 보겠습니다 🎜🎜여기 user_id는 bigint 유형이지만 문자열을 쿼리 매개변수로 사용하면 여전히 인덱싱이 필요하지 않습니다🎜🎜🎜🎜
为什么第一个例子导致了索引失效,而第二个不会呢?
这里就要了解一下MySQL的字符转换规则了,看是数字转字符串,还是字符串转数字
我们可以用select "10">9来测试一下
如果是数字转字符串,那么就相当于select "10">"9"结果应该是0
如果是字符串转数字,那么就相当于select 10>9,结果是1
在MySQL中的执行结果如下:

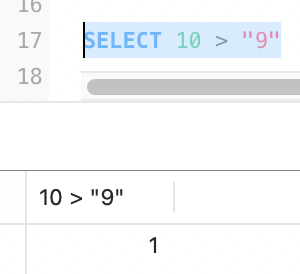
这就说明,MySQL在遇到数字与字符串的比较的时候,会自动把字符串转换为数字,然后进行比较
也就是说,在第一个例子中
SELECT * FROM sys_user WHERE phone = 18200000000 ;
相当于
SELECT * FROM sys_user WHERE CAST(phone AS UNSIGNED) = 18200000000 ;
这就在索引字段上使用了函数,所以导致索引失效
而在第二个例子中
SELECT * FROM sys_user WHERE user_id = "1" ;
相当于
SELECT * FROM sys_user WHERE user_id = CAST("1" AS UNSIGNED) ;函数式作用在查询参数上的,并没有作用在索引字段上,所以还是走索引的
联合索引非最左匹配
多个普通字段组合在一起创建的索引叫做联合索引(组合索引)
在使用联合索引的时候,一定要注意顺序问题,联合索引的使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引匹配。
例如,创建了一个(a,b,c)联合索引,那么如果查询条件是一下几种,就可以匹配上联合索引
where a = 1
where a = 1 and b = 2
where a = 1 and b = 2 and c = 3
需要注意的是,因为有查询优化器,所以a字段在where子句中的顺序不重要
若缺少a字段,则以下几种情况由于不符合最左匹配原则将无法匹配联合索引,导致该联合索引失效
where b = 2
where c = 3
where b = 2 and c = 3
还有一个比较特殊的查询条件:where a = 1 and c = 3
在MySQL5.5的话,前面的a 会走索引,在联合索引找到主键值,然后回表,到主键索引读取数据行,然后在比对c字段的值
在MySQL5.6之后,有一个索引下推的功能,
下推就是将部分上层(服务层)负责的事情,交给了下层(引擎层)处理
存储引擎直接在联合索引里按照c=3过滤,按照过滤后的数据在进行回表扫描,减少了回表的次数,从而提升了性能
在执行计划中Extra = Using index condition就表示使用了索引下推

联合索引不遵循最左匹配原则的原因:在联合索引中,数据按照第一列索引进行排序,第一列数据相同时,才会按照第二列进行排序,以此类推,所以直接使用第二列进行查询的时候,联合索引就会失效
where子句中的or
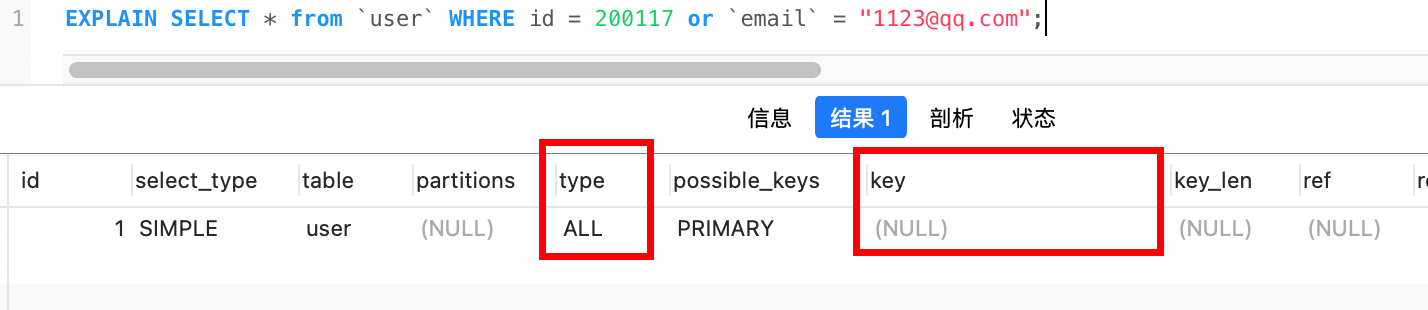
where子句中or的条件列有不是索引列会导致索引失效
例如:下图中id是索引列,email不是索引列,从执行计划来看,进行了全文扫描并没有使用到索引
因为or关键字只满足一个条件就可以,因此只要有一个列不是索引列,其他索引列也就没有意义了,就会进行全表扫描
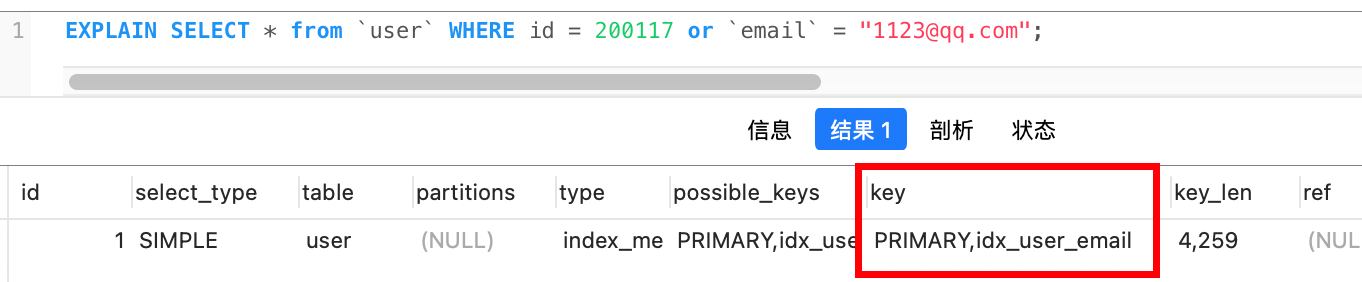
在email列上建立索引之后,可以看到执行计划中使用到了两个索引
type = index_merge表示对id 和email都进行了扫描,然后进行了合并
위 내용은 MySQL 상세 인덱스 실패 사례 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!