cx | 93 | 심천 | 남성 |
|
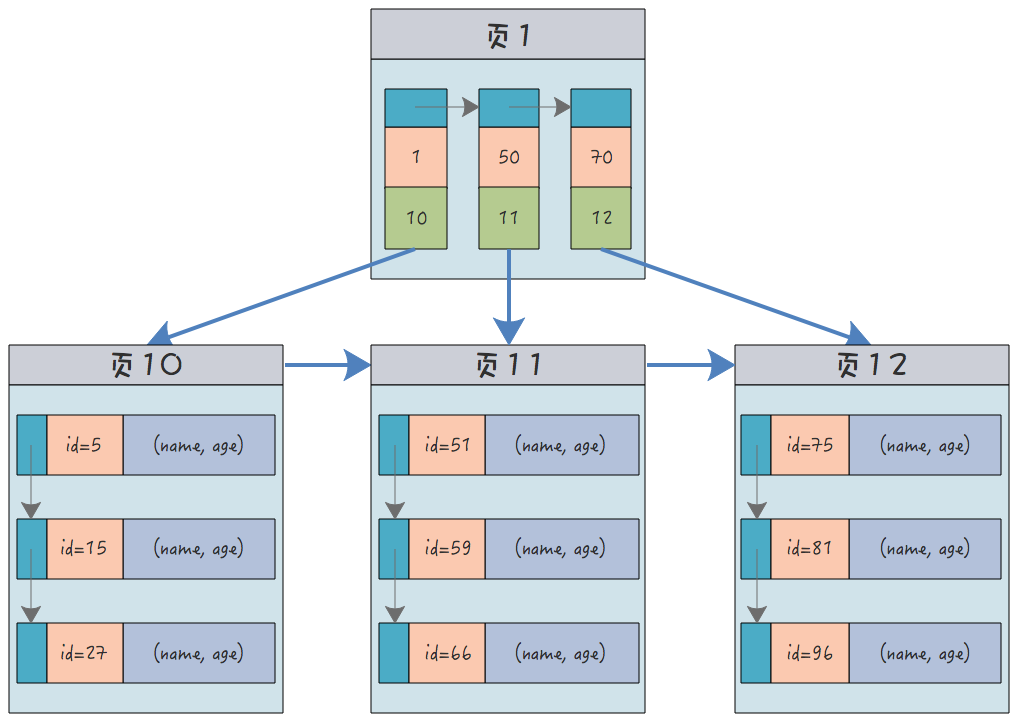
그러면 클러스터형 인덱스는 다음과 같을 것입니다.

보시다시피 리프에는 기본 키 값(인덱스)과 데이터 행이 모두 있고 리프에는 기본 키 값(인덱스)만 있습니다. 노드.
친구 여러분, 생각해 보세요. MySQL 테이블의 데이터는 디스크에 하나의 복사본에만 저장할 수 있으며 두 개의 복사본을 저장하는 것은 불가능합니다. 따라서 테이블에는 여러 개가 아닌 하나의 클러스터형 인덱스만 있을 수 있습니다. .
2. 클러스터링된 인덱스와 기본 키
어떤 친구들은 둘 사이의 관계에 대해 명확하지 않으며 심지어 둘을 동일시하는 경우도 있습니다.
일부 데이터베이스에서는 개발자가 클러스터형 인덱스로 사용할 인덱스를 자유롭게 선택할 수 있지만 MySQL은 이 기능을 지원하지 않습니다.
MySQL에서 테이블 자체에 기본 키가 설정되어 있으면 기본 키는 클러스터형 인덱스입니다. 테이블 자체에 기본 키가 설정되어 있지 않으면 테이블의 비어 있지 않은 고유 인덱스가 클러스터형 인덱스로 선택됩니다. 클러스터형 인덱스; 테이블에 비어 있지 않은 고유 인덱스가 없는 경우 테이블의 암시적 기본 키가 자동으로 클러스터형 인덱스로 선택됩니다. 송 형제는 향후 기사에서 MySQL 테이블의 암시적 기본 키를 소개할 것입니다.
그러나 일반적으로 암시적 기본 키는 자동 증가하고 자동 증가에 문제가 있으므로 테이블의 기본 키를 직접 설정하는 것이 좋습니다. 매우 높은 잠금 경쟁이 발생합니다. 자동 증가 값에 문제가 있습니다. 상한은 핫 데이터라고 합니다. 모든 삽입 작업에는 기본 키가 증가해야 하고 반복할 수 없으므로 잠금 경쟁이 발생하고 성능이 저하되기 때문입니다.
위의 소개를 바탕으로 MySQL의 클러스터형 인덱스와 기본 키 인덱스의 관계를 다음과 같이 요약할 수 있습니다.
3. Clustered index의 장점과 단점
먼저 장점부터 이야기해보겠습니다.
상호 연관된 데이터를 함께 저장할 수 있습니다. 예를 들어 사용자 주문 테이블이 있습니다. 사용자 ID + 주문 ID를 기준으로 모든 데이터를 집계할 수 있습니다. 사용자 ID는 반복될 수 있지만 이러한 방식으로 모든 주문 관련 데이터를 저장할 수 있습니다. 사용자의 모든 주문을 쿼리해야 하는 경우 매우 빠르며 소량의 디스크 IO만 필요합니다.
테이블을 반환할 필요가 없으므로 데이터 액세스가 더 빠릅니다. 클러스터형 인덱스에서는 인덱스와 데이터가 동일한 B+트리에 있으므로 클러스터형 인덱스에서 데이터를 얻는 것이 비클러스터형 인덱스에서 데이터를 얻는 것보다 빠릅니다(비클러스터형 인덱스에는 테이블 지원이 필요함).
첫 번째 경우, 사용자 ID를 기반으로 이 사용자의 모든 주문 ID를 쿼리하려면 현재 리프 노드로 갈 필요가 없습니다. 지원 노드에 우리가 보유한 데이터가 있기 때문입니다. 필요하므로 커버링 인덱스의 특성을 직접 이용하여 필요한 데이터를 읽어올 수 있습니다.
이것은 클러스터형 인덱스의 몇 가지 일반적인 장점입니다. 실제로 일상적인 테이블 디자인에서는 이러한 장점을 최대한 활용해야 합니다.
단점을 살펴보겠습니다.
친구들은 앞서 언급한 클러스터형 인덱스의 장점은 주로 클러스터형 인덱스가 IO 수를 줄여 데이터베이스 성능을 향상시킨다는 점을 발견했습니다. 집약적인 애플리케이션에서는 충분히 큰 메모리를 직접 로드하고 모든 데이터를 메모리로 읽어 작업하는 것이 가능할 수 있습니다. 이 경우 클러스터형 인덱스는 이점이 없습니다.
임의의 기본 키는 페이지 분할 문제를 야기합니다. 기본 키를 순차적으로 삽입하면 효율성이 상대적으로 높아집니다. B+Tree에서는 기본 키를 계속 추가하면 되기 때문입니다. 비순차적으로 삽입하면 페이지 분할이 포함될 수 있으므로 효율성이 훨씬 낮아집니다. 위 그림을 예로 들면, 각 노드가 3개의 데이터를 저장할 수 있다고 가정하고 이제 기본 키가 4.5인 레코드를 삽입하려면 기본 키 값인 5를 뒤로 이동해야 합니다. 기본 키가 8인 노드도 뒤로 이동하게 됩니다. 페이지 분할로 인해 데이터 삽입 효율성이 떨어지고 더 많은 저장 공간을 차지합니다.
비클러스터형 인덱스(보조 인덱스)는 쿼리 시 테이블을 반환해야 합니다. 인덱스는 인덱스 트리이고 데이터는 모두 클러스터형 인덱스에 있으므로 비클러스터형 인덱스를 사용하여 검색하면 비클러스터형 인덱스의 리프에 기본 키 값이 먼저 저장됩니다. , 그리고 Hold 클러스터형 인덱스에서 기본 키 값을 검색하여 총 2개의 인덱스 트리가 쿼리되는 것이 테이블 반환입니다.