
Redis의 Sentinel 장애 조치 원칙은 무엇입니까?

- 王林앞으로
- 2023-05-27 10:55:171651검색
Sentinel이란?
Sentinel은 앞서 이야기한 마스터-슬레이브 복제가 고가용성의 기반입니다. 그러나 순수 마스터-슬레이브 복제는 장애 조치를 완료하기 위해 수동 개입이 필요합니다. 이 문제의 경우 마스터-슬레이브 복제의 경우 마스터 노드에 장애가 발생하면 Sentinel은 자동으로 장애를 감지하고 장애 조치를 완료하여 진정한 Redis 고가용성을 달성할 수 있습니다. sentinel 클러스터에서 sentinel은 모든 redis 서버 및 기타 sentinel 노드의 상태를 모니터링하고 적시에 장애를 감지하고 전송을 완료함으로써 redis의 고가용성을 보장합니다.
Sentinel 클러스터 구축
Sentinel은 본질적으로 Redis 서비스이지만 일반 Redis 서비스와는 다른 기능을 제공합니다. Sentinel은 분산 아키텍처입니다. 왜냐하면 Redis의 고가용성을 보장하려면 먼저 고유한 고가용성을 보장해야 하기 때문입니다. 따라서 Sentinel을 구축해야 하는 경우 최소 3개의 인스턴스(바람직하게는 홀수)를 배포해야 합니다. , 후속 장애 조치에는 투표가 포함되기 때문입니다.
redis GitHub 프로젝트 아래에 sentinel 구성 파일을 다운로드할 수 있습니다. 프로젝트 아래에 sentinel.conf라는 파일이 있습니다. 이를 sentinel 구성 템플릿으로 사용할 수 있습니다. 물론 redis.conf 구성 파일을 사용할 수도 있습니다. . 센티넬 관련 구성을 추가하면 됩니다.
Sentinel과 관련된 구성 항목은 많지 않습니다. 주로 다음과 같은 구성 항목이 있습니다.
// 端口号,默认是 redis 实例+20000,所以我们沿用这个规则就好了 port 26379 // 是否守护进程运行 daemonize yes // 日志存放的位置,这个非常重要,通过日志可以查看故障转移的过程 logfile "26379.log" // 监视一个名为 mymaster(自定义) 的 redis 主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6379 , // 最后面的 2 代表着至少有两个哨兵认为主服务器出现故障才会进行故障转移,否则认定主服务未失效 sentinel monitor mymaster 127.0.0.1 6379 2 // 哨兵判断服务器失效的响应时间,超过这个时间未接收到服务器的回应,就认为该服务器失效了 sentinel down-after-milliseconds mymaster 30000 // 完成故障转移之后,最多多少个从服务器可以同时发起数据复制,数字越小,说明完成全部从服务数据复制的时间越长 // 数字越大,对主服务器的压力就变大了 sentinel parallel-syncs mymaster 1 // 故障转移超时时间 sentinel failover-timeout mymaster 180000
각 Sentinel 인스턴스 구성마다 포트 및 로그 파일이 다른 것을 제외하면 다른 구성 항목은 동일합니다. 구성을 수정한 후 ./redis-sentinel sentinel.conf 명령을 사용하여 sentinel을 시작할 수 있습니다. 이 명령은 redis 인스턴스 시작과 유사합니다. 왜냐하면 sentinel도 redis 인스턴스이기 때문에 ./redis-를 사용할 수 있습니다. cli -p 26379 info sentinel 명령을 사용하면 현재 sentinel 정보는 아래 그림과 같습니다.
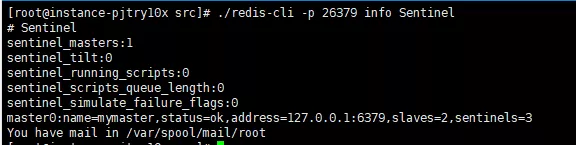
Sentinel information
질문: 마스터 서버만 구성된 경우 슬레이브 서버와 다른 Sentinel을 검색하는 방법 ?
슬레이브 서버를 검색하기 위해 Sentinel은 마스터 서버에 서버로부터 정보를 얻도록 요청할 수 있습니다. 다른 Sentinel 노드를 검색하려면 게시 및 구독 기능을 통해 sentinel:hello 채널에 정보를 전송하여 구현됩니다.
1. 각 Sentinel은 게시 및 구독 기능을 통해 모든 마스터 서비스 및 슬레이브 서버의 sentinel:hello 채널로 메시지가 전송됩니다. 메시지에는 Sentinel의 IP 주소, 포트 번호가 포함됩니다. 및 실행 ID(runid)
2. 각 Sentinel은 구독됩니다. Sentinel:hello가 모니터링하는 모든 마스터 서버와 슬레이브 서버의 채널은 이전에 나타나지 않은 센티널을 찾습니다(알 수 없는 센티널을 찾습니다). Sentinel이 새로운 Sentinel을 발견하면 동일한 마스터 서버를 모니터링하는 Sentinel에 알려진 다른 모든 Sentinel을 포함하는 목록에 새 Sentinel을 추가합니다.
Sentinel Failover 원칙
Failover가 Sentinel의 주요 작업입니다. 구체적인 구현 논리에 대해서는 관련 서적을 확인하세요. Sentinel 장애 조치에 대한 다음 세 가지 사항을 요약했습니다.
1. Listening 서버
Sentinel 노드는 ping 명령을 마스터 노드, 슬레이브 노드, 기타 Sentinel 노드를 1초마다 하트비트 감지를 통해 서버 상태를 확인합니다.
노드는 Sentinel에도 그에 따라 응답합니다. 이 응답 중 다음 세 가지 응답이 유효한 응답입니다. 노드가 Sentinel 구성 파일에 설정된 master-down-after-milliseconds 옵션 값 내에서 유효한 응답을 하나도 받지 못한 경우 Sentinel은 서버를 오프라인으로 표시합니다. 즉, 이 센티넬만이 서버가 오프라인이라고 생각합니다.
- 주관적으로 오프라인인 서버가 메인 서버인 경우, 메인 서버가 실제로 오프라인인지 확인하기 위해 센티넬은 메인 서버를 모니터링하고 있는 다른 센티널들에게도 메인 서버가 오프라인 상태라고 생각하는지 물어봅니다. 온라인 상태에서 충분한 수의 Sentinel이 메인 서버가 오프라인이라고 판단하면 Sentinel은 메인 서버를 객관적인 오프라인, 즉 실제 오프라인으로 판단하고 장애 조치 작업을 수행합니다.
- 2. Sentinel 노드를 선택하여 전송 작업을 완료합니다
모든 Sentinel이 장애 조치를 완료하는 것은 아니지만 장애 조치를 완료하기 위해 Sentinel 노드를 리더로 선출하므로 메인 서버가 객관적으로 표시되면 온라인일 때 센티넬은 Raft 알고리즘을 통해 리더를 선출하여 장애 조치 작업을 완료합니다. 일반적인 규칙과 방법은 다음과 같습니다. Redis는 센티넬 리더 선출을 실시합니다
모든 온라인 센티널은 리더로 선출될 수 있습니다. 이는 모든 센티널이 리더가 될 수 있는 기회를 갖는다는 것을 의미합니다
sentinel이 마스터 서버를 주관적으로 오프라인으로 표시하면 sentinel is-master-down-by-addr 명령을 다른 Sentinel 노드에 보내 자신을 리더로 설정하도록 요청합니다
명령, 선착순 규칙을 채택하여 다른 Sentinel 노드의 sentinel is-master-down-by-addr 명령이 동의되지 않으면 요청이 승인되고 그렇지 않으면 거부됩니다
센티넬 노드가 자신의 투표 수가 절반을 초과한 것을 발견하면 리더가 됩니다
센티넬 노드가 지정된 시간 내에 선출되지 않으면 센티넬 리더가 선출될 때까지 일정 시간 후에 다시 선출됩니다. 선출.
3. 장애 조치를 완료하려면 새 마스터 서버를 선택하세요.
선출된 센티널 리더는 나머지 장애 조치 작업을 완료합니다.
(1) 새 마스터를 선택합니다. server
오프라인 마스터 서버의 모든 슬레이브 서버 중 슬레이브 서버를 선택하여 마스터 서버로 전환합니다. 새로운 마스터 서버를 선택하는 규칙은 다음과 같습니다.
마스터 서버가 실패한 경우 마스터 서버 아래 슬레이브 서버 중 주관적으로 오프라인, 연결 끊김으로 표시되거나 PING 명령에 대한 마지막 응답이 5초 이상인 슬레이브 서버는 제거됩니다
실패한 마스터 서버 아래의 슬레이브 서버 중 , down-after 옵션에서 지정한 시간보다 10배 이상 장애가 발생한 마스터 서버와의 연결이 끊어진 슬레이브 서버는 제거됩니다
-
위의 두 차례 제거 후 나머지 슬레이브 서버가 선택됩니다. 복제 오프셋이 가장 큰 슬레이브 서버가 새 마스터 서버가 됩니다. 복제 오프셋을 사용할 수 없거나 슬레이브 서버의 복제 오프셋이 동일한 경우 실행 ID가 가장 작은 슬레이브 서버가 새 마스터 서버가 됩니다.
선택한 슬레이브 서버에서 Slaveof no one 명령을 실행하여 마스터 노드로 만듭니다.
(2) 다른 슬레이브 서버의 복제 대상 수정
새 마스터 서버가 나타나면 센티널 리더가 해야 할 다음 단계는 다른 슬레이브 서버가 다른 슬레이브에게 메시지를 보내 새 마스터 서버를 복제하도록 하는 것입니다. 서버는 완료를 위해 Slaveof new_master port 명령을 보냅니다. 복제 규칙은 구성 파일의 parallel-syncs 매개변수와 관련됩니다. (3) 장애 조치에서 마지막으로 수행할 작업은 다음과 같습니다. 작업은 오프라인 서버를 오프라인으로 전환하는 것입니다. 마스터 서버를 새로운 마스터 서비스의 슬레이브 서버로 설정하고 이를 감시하며 복구 후 새 마스터 노드를 복제하도록 명령합니다.
위 내용은 Redis의 Sentinel 장애 조치 원칙은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!