
LLM 추론이 3배 더 빨라졌습니다! Microsoft, LLM Accelerator 출시: 참조 텍스트를 사용하여 무손실 가속 달성

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-27 10:40:061592검색
인공지능 기술의 급속한 발전으로 ChatGPT, New Bing, GPT-4 등의 신제품과 기술이 속속 출시되고 있으며, 많은 애플리케이션에서 기본 대형 모델이 점점 더 중요한 역할을 담당하게 될 것입니다.
현재 대규모 언어 모델의 대부분은 자동 회귀 모델입니다. 자기회귀는 모델이 출력 시 단어별 출력을 사용하는 경우가 많다는 것을 의미합니다. 즉, 각 단어를 출력할 때 모델은 이전에 출력된 단어를 입력으로 사용해야 합니다. 이 자동 회귀 모드는 일반적으로 출력 중 병렬 가속기의 전체 활용을 제한합니다.
많은 애플리케이션 시나리오에서 대규모 모델의 출력은 다음 세 가지 일반적인 시나리오와 같이 일부 참조 텍스트와 매우 유사한 경우가 많습니다.
1. 검색 강화 생성
When New Bing과 같은 검색 응용 프로그램은 사용자 입력에 응답하며 먼저 사용자 입력과 관련된 일부 정보를 반환한 다음 언어 모델을 사용하여 검색된 정보를 요약한 다음 사용자 입력에 응답합니다. 이 시나리오에서는 모델의 출력에 검색 결과의 많은 수의 텍스트 조각이 포함되는 경우가 많습니다.
2. 캐시 생성 사용
언어 모델의 대규모 배포 과정에서 과거 입력 및 출력이 캐시됩니다. 새 입력을 처리할 때 검색 애플리케이션은 캐시에서 유사한 입력을 찾습니다. 따라서 모델의 출력은 캐시의 해당 출력과 매우 유사한 경우가 많습니다.
3. 다단계 대화 생성
ChatGPT와 같은 애플리케이션을 사용할 때 사용자는 모델의 출력을 기반으로 반복적으로 수정 요청을 하는 경우가 많습니다. 이 다중 회전 대화 시나리오에서 모델의 여러 출력은 종종 작은 변화량과 높은 반복 수준을 갖습니다.
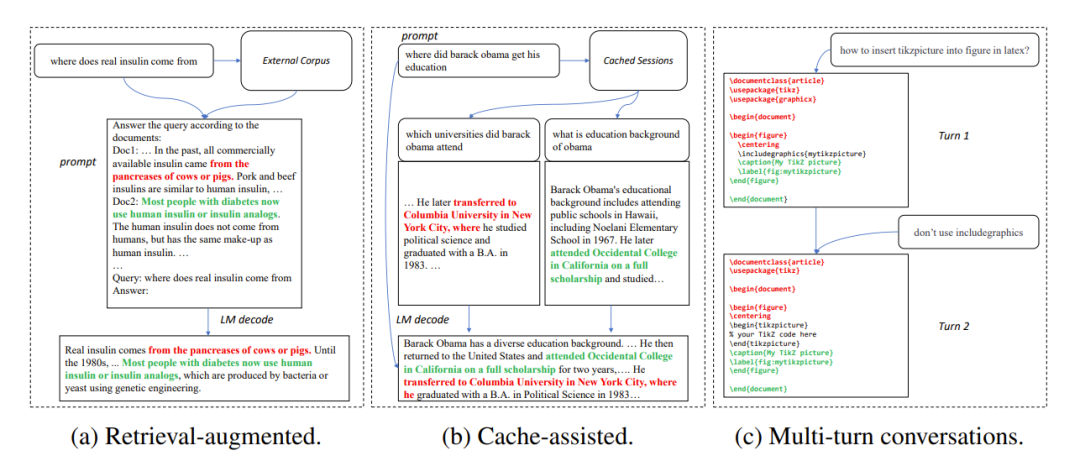
그림 1: 대규모 모델의 출력이 참조 텍스트와 유사한 일반적인 시나리오
위 관찰을 바탕으로 연구원들은 참조 텍스트와 모델의 반복성을 사용했습니다. 자동 회귀의 획기적인 출력 병목 현상에 초점을 맞춰 병렬 가속기의 활용도를 높이고 대규모 언어 모델 추론을 가속화할 수 있도록 하며, 출력 및 참조 텍스트의 반복을 사용하여 한 단계에 여러 단어를 출력하는 LLM Accelerator 방법을 제안합니다. .
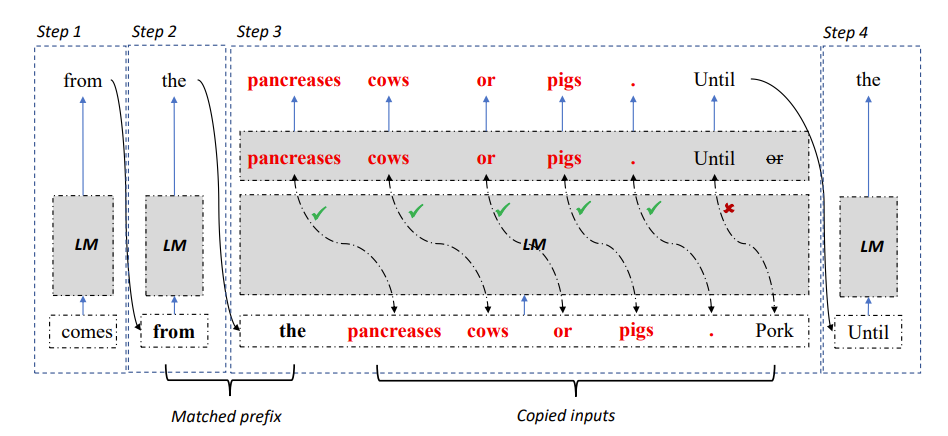
그림 2: LLM 가속기 디코딩 알고리즘
구체적으로, 각 디코딩 단계에서 모델이 먼저 기존 출력 결과 및 참조 텍스트와 일치하도록 합니다. 기존 출력과 일치하면 모델은 기존 참조 텍스트를 계속 출력할 가능성이 높습니다.
따라서 연구진은 참조 텍스트의 후속 단어를 모델에 입력으로 추가하여 한 번의 디코딩 단계에서 여러 단어를 출력할 수 있도록 했습니다.
입력과 출력이 정확한지 확인하기 위해 연구원들은 모델에서 출력된 단어와 참조 문서에서 입력된 단어를 추가로 비교했습니다. 두 가지가 일치하지 않으면 잘못된 입력 및 출력 결과가 삭제됩니다.
위 방법을 사용하면 디코딩 결과가 기본 방법과 완전히 일치하는지 확인할 수 있으며 각 디코딩 단계에서 출력 단어 수를 늘릴 수 있으므로 대규모 모델 추론의 무손실 가속을 달성할 수 있습니다.
LLM Accelerator는 추가 보조 모델이 필요하지 않고 사용이 간편하며 다양한 애플리케이션 시나리오에 쉽게 배포할 수 있습니다.
논문 링크: https://arxiv.org/pdf/2304.04487.pdf
프로젝트 링크: https://github.com/microsoft/LMOps
LLM Accelerator를 사용하여, 조정해야 할 하이퍼파라미터는 2개입니다.
먼저, 일치 메커니즘을 실행하는 데 필요한 출력과 참조 텍스트 사이의 일치하는 단어 수: 일치하는 단어의 수가 길수록 정확도가 높아져 참조 텍스트에서 복사된 단어가 더 잘 맞는지 확인할 수 있습니다. 올바른 출력, 불필요한 트리거링 및 계산 감소, 더 짧은 일치, 더 적은 디코딩 단계, 잠재적으로 더 빠른 속도 향상.
두 번째는 매번 복사되는 단어 수입니다. 단어가 많이 복사될수록 가속 가능성은 커지지만, 잘못된 출력이 폐기되는 경우도 많아 컴퓨팅 리소스가 낭비될 수 있습니다. 연구자들은 실험을 통해 보다 공격적인 전략(단어 트리거 일치, 한 번에 15~20단어 복사)이 종종 더 나은 가속 비율을 달성할 수 있음을 발견했습니다.
LLM Accelerator의 효과를 검증하기 위해 연구진은 검색 향상 및 캐시 지원 생성에 대한 실험을 수행하고 MS-MARCO 단락 검색 데이터 세트를 사용하여 실험 샘플을 구성했습니다.
검색 향상 실험에서 연구원들은 검색 모델을 사용하여 각 쿼리에 대해 가장 관련성이 높은 10개의 문서를 반환한 다음 이 10개의 문서를 참조 텍스트로 사용하여 모델에 대한 입력으로 쿼리에 연결했습니다.
캐시 지원 생성 실험에서 각 쿼리는 4개의 유사한 쿼리를 생성한 다음 모델을 사용하여 해당 쿼리를 참조 텍스트로 출력합니다.
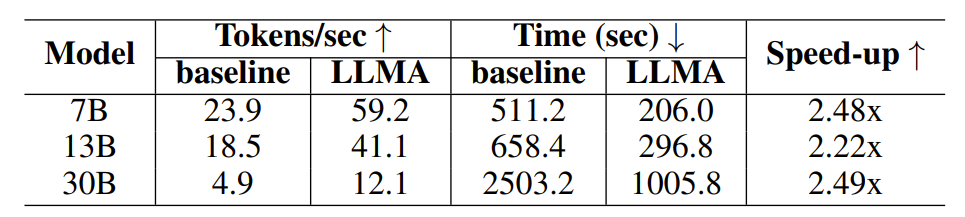
표 1: 검색 강화 생성 시나리오의 시간 비교
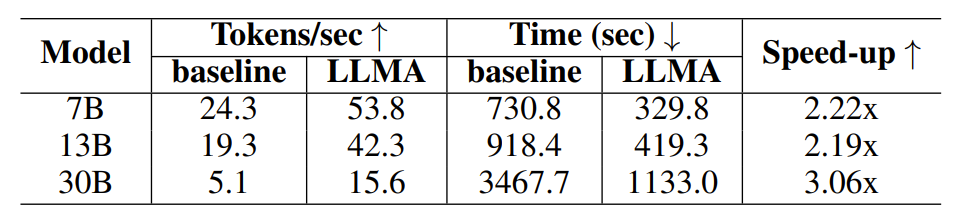
표 2: 캐시를 사용한 생성 시나리오의 시간 비교
연구진은 고품질의 출력을 얻기 위해 OpenAI 인터페이스를 통해 얻은 Davinci-003 모델의 출력을 목표 출력으로 사용했습니다. 필요한 입력, 출력 및 참조 텍스트를 얻은 후 연구원들은 오픈 소스 LLaMA 언어 모델에 대한 실험을 수행했습니다.
LLaMA 모델의 출력이 Davinci-003 출력과 일치하지 않기 때문에 연구원들은 목표 지향적 디코딩 방법을 사용하여 이상적인 출력(Davinci-003 모델 결과) 하에서 속도 향상 비율을 테스트했습니다.
연구원들은 그리디 디코딩 중에 목표 출력을 생성하는 데 필요한 디코딩 단계를 얻기 위해 알고리즘 2를 사용했으며, 획득된 디코딩 단계에 따라 LLaMA 모델이 강제로 디코딩되도록 했습니다.

그림 3: 알고리즘 2를 사용하여 그리디 디코딩 중에 목표 출력을 생성하는 데 필요한 디코딩 단계를 얻음
매개변수 양이 7B와 13B인 모델의 경우 연구원들은 단일 32G NVIDIA 실험은 매개변수 크기가 30B인 모델에 대해 V100 GPU에서 수행되었으며, 실험은 4개의 동일한 GPU에서 수행되었습니다. 모든 실험은 반정밀도 부동 소수점 수를 사용하고 디코딩은 탐욕적 디코딩이며 배치 크기는 1입니다.
실험 결과에 따르면 LLM Accelerator는 다양한 모델 크기(7B, 13B, 30B) 및 다양한 애플리케이션 시나리오(검색 향상, 캐시 지원)에서 2~3배의 가속 비율을 달성한 것으로 나타났습니다.
추가 실험 분석에 따르면 LLM Accelertator는 필요한 디코딩 단계를 크게 줄일 수 있으며 가속 비율은 디코딩 단계의 감소 비율과 양의 상관관계가 있는 것으로 나타났습니다.
한편으로는 디코딩 단계가 적다는 것은 각 디코딩 단계가 더 많은 출력 단어를 생성한다는 것을 의미하며, 이는 GPU 계산의 계산 효율성을 향상시킬 수 있는 반면, 다중 카드 병렬 처리가 필요한 30B 모델의 경우 이는 의미합니다. 다중 카드 동기화가 줄어들어 속도가 더 빨라집니다.
절제 실험에서 개발 세트에서 LLM Accelertator의 하이퍼파라미터를 분석한 결과, 단일 단어를 일치시킬 때(즉, 복사 메커니즘을 트리거할 때) 15~15개를 복사할 때 속도 향상 비율이 최대에 도달할 수 있는 것으로 나타났습니다. 한 번에 20단어입니다(그림 4 참조).
그림 5에서 일치하는 단어의 수가 1이므로 복사 메커니즘을 더 많이 트리거할 수 있으며 복사 길이가 증가함에 따라 각 디코딩 단계에서 허용되는 출력 단어가 증가하고 디코딩 단계가 감소하므로 더 높은 가속 비율에 도달합니다.
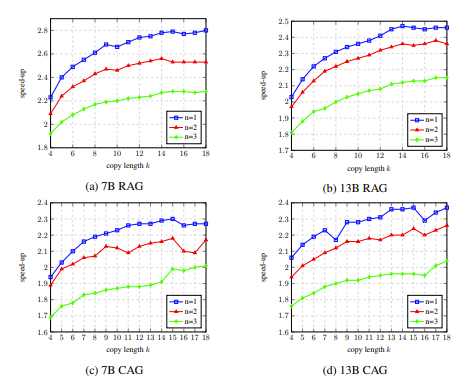
그림 4: 절제 실험에서 개발 세트
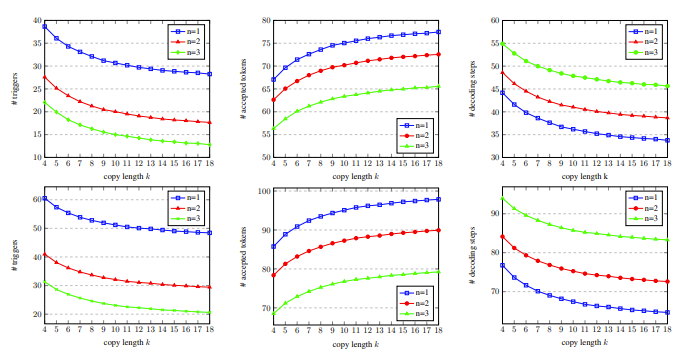
그림 5: 개발 과정 세트, 서로 다른 일치하는 단어 수 n과 복사된 단어 수 k에 대한 디코딩 단계의 통계 데이터 포함
LLM Accelertator는 Microsoft Research Asia Natural Language Computing Group의 향후 대규모 언어 모델 가속화에 대한 일련의 작업 중 하나입니다. 연구자들은 관련 문제를 계속해서 더 깊이 탐구할 것입니다.
위 내용은 LLM 추론이 3배 더 빨라졌습니다! Microsoft, LLM Accelerator 출시: 참조 텍스트를 사용하여 무손실 가속 달성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!