
전직 Google 엔지니어는 Jeff Dean의 신성한 요약을 모방하여 모든 개발자가 알아야 할 'LLM 개발 비밀'을 공유했습니다!

- 王林앞으로
- 2023-05-25 22:25:291513검색
최근 한 네티즌은 'LLM 개발자가 꼭 알아야 할 숫자' 목록을 정리하고 이 숫자가 왜 중요한지, 어떻게 사용해야 하는지 설명했습니다.
그가 구글에 있을 때, 전설적인 엔지니어 Jeff Dean이 편집한 "Numbers Every Engineer Should Know"라는 문서가 있었습니다.

Jeff Dean: "모든 엔지니어가 알아야 할 숫자"
LLM(Large Language Model) 개발자에게는 비슷한 대략적인 추정치가 있습니다. 숫자도 매우 유용합니다.

Prompt
40-90%: 프롬프트에 "concise and concise"를 추가한 후 비용 절감
출력 중 LLM에서 사용하는 토큰을 기반으로 한다는 것을 알아야 합니다. 유급의.
이는 모델을 간결하게 함으로써 많은 비용을 절약할 수 있다는 의미입니다.
동시에 이 개념은 더 많은 곳으로 확장될 수 있습니다.
예를 들어 원래 GPT-4를 사용하여 10개의 대안을 생성하려고 했지만 이제는 먼저 5개를 제공하도록 요청한 다음 나머지 절반을 유지할 수 있습니다.
1.3: 단어당 평균 토큰 수
LLM은 토큰 단위로 운영됩니다.
그리고 토큰은 단어 또는 단어의 하위 부분입니다. 예를 들어 "eating"은 "eat"와 "ing"이라는 두 개의 토큰으로 분해될 수 있습니다.
일반적으로 750개의 영어 단어가 약 1000개의 토큰을 생성합니다.
영어 이외의 언어의 경우 LLM 임베딩 코퍼스의 공통성에 따라 단어당 토큰 수가 늘어납니다.

Price
LLM을 사용하는 데 드는 비용이 매우 높다는 점을 고려하면 가격과 관련된 숫자가 특히 중요해집니다.
~50: GPT-4 대 GPT-3.5 터보의 비용 비율
GPT-3.5-Turbo를 사용하는 것은 GPT-4보다 약 50배 저렴합니다. GPT-4는 프롬프트와 생성에 따라 요금이 다르게 청구되기 때문에 "대략"이라고 말합니다.
그래서 실제 적용에서는 GPT-3.5-Turbo가 귀하의 요구 사항을 충족하기에 충분한지 확인하는 것이 가장 좋습니다.
예를 들어 요약과 같은 작업의 경우 GPT-3.5-Turbo로 충분합니다.


5 LLM 생성을 사용하는 것이 훨씬 저렴합니다. 구체적으로 신경 정보 검색 시스템에서 검색하는 비용은 GPT-3.5-Turbo에 문의하는 것보다 약 5배 저렴합니다. GPT-4와 비교하면 비용 차이가 250배나 됩니다! 10: OpenAI 임베딩과 자체 호스팅 임베딩의 비용 비율 참고: 이 숫자는 임베딩의 로드 및 배치 크기에 매우 민감하므로 대략적인 것으로 간주하십시오. g4dn.4xlarge(주문형 가격: $1.20/시간)를 사용하면 HuggingFace(OpenAI의 임베딩과 유사)가 포함된 SentenceTransformers를 활용하여 초당 최대 9000개의 토큰을 삽입할 수 있습니다. 이 속도와 노드 유형에서 몇 가지 기본 계산을 수행하면 자체 호스팅 임베드가 10배 더 저렴할 수 있음을 알 수 있습니다. 6: OpenAI 기본 모델과 미세 조정 모델 간의 쿼리 비용 비율 OpenAI에서 미세 조정 모델의 비용은 기본 모델의 6배입니다. 이는 커스텀 모델을 미세 조정하는 것보다 기본 모델의 팁을 조정하는 것이 비용 효율적이라는 의미이기도 합니다. 1: 자체 호스팅 기본 모델과 미세 조정 모델 쿼리의 비용 비율 모델을 직접 호스팅하는 경우 미세 조정 모델과 기본 모델의 비용은 거의 동일합니다. 매개변수 수는 두 모델 모두 동일합니다. ~100만 달러: 1.4조 토큰 논문 주소: https://arxiv.org/pdf/2302.13971. pdf LLaMa 논문에서는 LLaMa 모델을 훈련하는 데 21일이 걸렸으며 2048 A100 80GB GPU를 사용했다고 언급했습니다. Red Pajama 훈련 세트에서 모델을 훈련시키고 모든 것이 충돌 없이 잘 작동하고 처음 성공한다고 가정하면 위의 숫자를 얻게 됩니다. 또한 이 프로세스에는 2048 GPU 간의 조정도 포함됩니다. 대부분의 회사에서는 이를 수행할 수 있는 조건이 없습니다. 그러나 가장 중요한 메시지는 자체 LLM을 교육하는 것이 가능하지만 프로세스가 저렴하지 않다는 것입니다. 그리고 실행할 때마다 며칠이 걸립니다. 이에 비해 사전 훈련된 모델을 사용하는 것이 훨씬 저렴합니다. < 0.001: 미세 조정 비용과 처음부터 훈련하는 비용 이 수치는 전반적으로 미세 조정 비용은 미미합니다. 예를 들어 6B 매개변수 모델을 약 $7에 미세 조정할 수 있습니다. 훈련 및 미세 조정
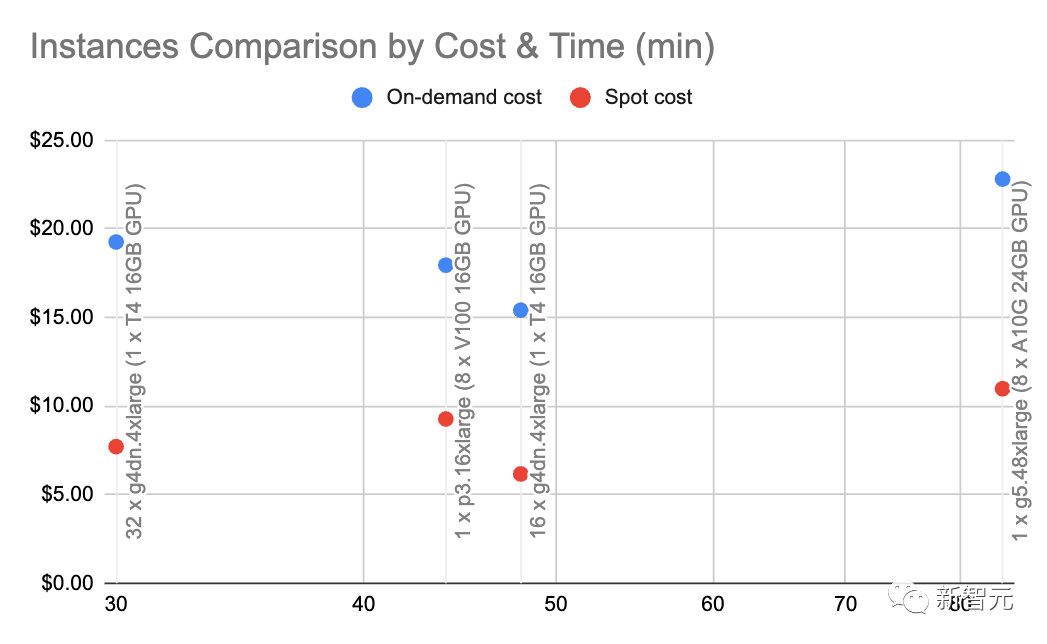
가장 비싼 미세 조정 모델인 Davinci의 OpenAI 요율을 적용해도 토큰 1,000개당 3센트에 불과합니다.
즉, 셰익스피어의 전체 작품(약 100만 단어)을 미세 조정하려면 40~50달러만 지출하면 됩니다.
그러나 미세 조정과 처음부터 훈련하는 것은 별개입니다...
GPU 메모리
모델을 자체 호스팅하는 경우 GPU 메모리를 이해하는 것이 매우 중요합니다. 왜냐하면 LLM은 GPU의 메모리를 한계까지 밀어붙입니다.
다음 통계는 특별히 추론을 위한 것입니다. 훈련이나 미세 조정을 하려면 꽤 많은 비디오 메모리가 필요합니다.
V100: 16GB, A10G: 24GB, A100: 40/80GB: GPU 메모리 용량
다양한 유형의 GPU에 대한 비디오 메모리 양을 이해하는 것이 중요합니다. 매개변수 수량을 가질 수 있습니다.
일반적으로 우리는 A10G를 사용하는 것을 선호합니다. AWS의 온디맨드 가격은 GPU 메모리 24G 기준 시간당 1.5~2달러이고 A100당 시간당 약 5달러이기 때문입니다.
2x 매개변수 수: LLM의 일반적인 GPU 메모리 요구 사항
예를 들어 70억 개의 매개변수 모델이 있는 경우 약 14GB의 GPU 메모리가 필요합니다.
이는 대부분의 경우 각 매개변수에 16비트 부동 소수점(또는 2바이트)이 필요하기 때문입니다.
일반적으로 16비트 이상의 정밀도는 필요하지 않지만 대부분의 경우 정밀도가 8비트에 도달하면 해상도가 감소하기 시작합니다(어떤 경우에는 이것도 허용 가능함).
물론 이러한 상황을 개선한 프로젝트도 있습니다. 예를 들어 llama.cpp는 6GB GPU에서 4비트(8비트도 허용됨)로 양자화하여 130억 개의 매개변수 모델을 실행했지만 이는 일반적이지 않습니다.
~1GB: 임베딩 모델을 위한 일반적인 GPU 메모리 요구 사항
문을 임베드할 때마다(클러스터링, 의미 검색 및 분류 작업을 위해 자주 수행하는 작업) 문 변환기와 같은 것이 필요합니다. 모델. OpenAI에는 자체 상용 임베딩 모델도 있습니다.
일반적으로 GPU에서 얼마나 많은 비디오 메모리 임베딩이 차지하는지 걱정할 필요가 없습니다. 비디오 메모리 임베딩은 매우 작으며 동일한 GPU에 LLM을 임베드할 수도 있습니다.
>10배: LLM 요청을 일괄 처리하여 처리량 향상
GPU를 통한 LLM 쿼리 실행 지연 시간은 매우 높습니다. 초당 0.2 쿼리 처리량에서는 지연 시간이 5초가 걸릴 수 있습니다.
흥미롭게도 두 가지 작업을 실행하는 경우 지연 시간은 5.2초에 불과할 수 있습니다.
즉, 25개의 쿼리를 함께 묶을 수 있으면 약 10초의 지연 시간이 필요한 반면 처리량은 초당 2.5개의 쿼리로 증가했습니다.
그러나 아래 내용을 계속 읽어주세요.
~1MB: 130억 개의 매개변수 모델이 1개의 토큰을 출력하는 데 필요한 GPU 메모리
필요한 비디오 메모리는 생성하려는 최대 토큰 수에 정비례합니다.
예를 들어 최대 512개 토큰(약 380단어)의 출력을 생성하려면 512MB의 비디오 메모리가 필요합니다.
별거 아니라고 생각할 수도 있습니다. 비디오 메모리가 24GB인데 512MB가 얼마죠? 그러나 더 큰 배치를 실행하려는 경우 이 숫자가 합산되기 시작합니다.
예를 들어 16개의 배치를 수행하려는 경우 비디오 메모리가 8GB로 직접 증가됩니다.
위 내용은 전직 Google 엔지니어는 Jeff Dean의 신성한 요약을 모방하여 모든 개발자가 알아야 할 'LLM 개발 비밀'을 공유했습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!