
재현 가능하고 자동화되었으며 저비용이며 높은 수준의 평가를 제공하는 최초의 대형 모델을 자동으로 평가하는 대형 모델인 PandaLM이 출시되었습니다.

- PHPz앞으로
- 2023-05-25 19:16:321874검색
대형 모델의 개발이 빠르다고 할 수 있습니다. 지시 미세 조정 방법이 비온 뒤 버섯처럼 생겨났습니다. 소위 ChatGPT "대체" 대형 모델이 속속 출시되었습니다. 대형 모델의 훈련 및 애플리케이션 개발에 있어서 오픈 소스, 폐쇄 소스, 자체 연구 등 다양한 대형 모델의 실제 역량에 대한 평가는 연구 개발 효율성과 품질을 향상시키는 중요한 연결고리가 되었습니다.
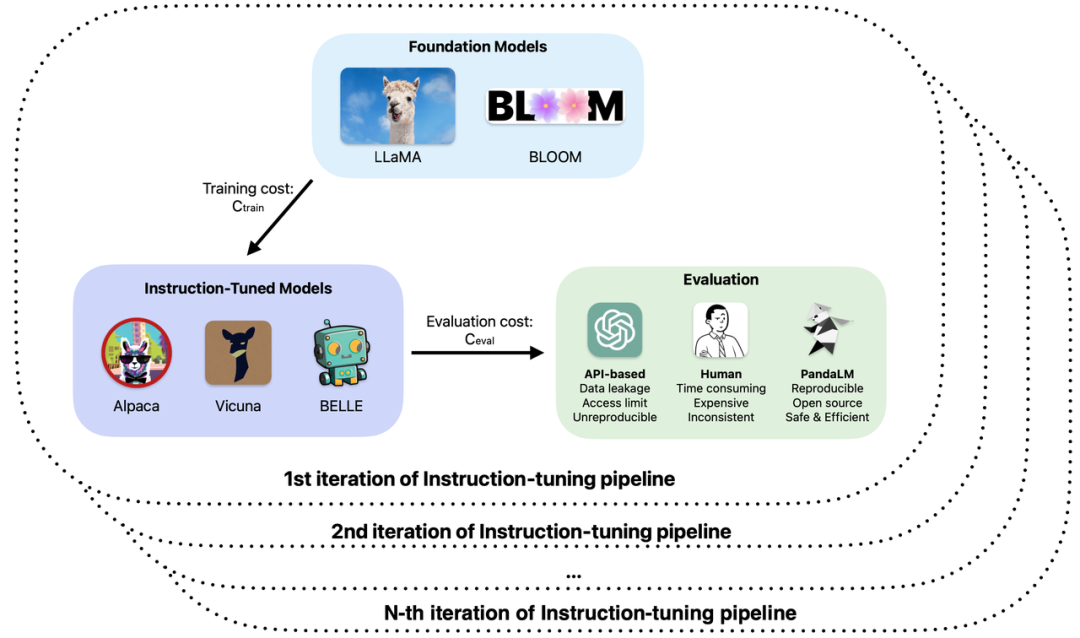
특히 대형 모델의 학습 및 적용에서 다음과 같은 문제가 발생할 수 있습니다.
1 대형 모델의 미세 조정 또는 강화된 사전 학습에 다른 기반이 사용됩니다. 관찰된 샘플 효과에 따르면 모델의 성능은 다양한 시나리오에서 장점과 단점을 가지고 있습니다. 실제 응용 프로그램에서 사용할 모델을 결정하는 방법은 무엇입니까?
2. ChatGPT를 사용하여 모델 출력을 평가하지만 ChatGPT는 동일한 입력에 대해 서로 다른 평가 결과를 사용해야 합니까?
3. 수동 주석을 사용하여 모델 생성 결과를 평가하는 것은 시간이 많이 걸리고 힘든 일입니다. 예산이 제한되어 있고 시간이 부족한 경우 평가 프로세스 속도를 높이고 비용을 줄이는 방법은 무엇입니까?
4. ChatGPT/GPT4를 사용하든 모델 평가를 위해 라벨링 회사를 사용하든 관계없이 기밀 데이터를 다룰 때 데이터 보안을 보장하는 방법은 무엇입니까?
이러한 문제를 바탕으로 북경대학교, 서호대학교 및 기타 기관의 연구자들이 공동으로 새로운 대형 모델 평가 패러다임인 PandaLM을 제안했습니다. PandaLM은 평가를 위해 특별히 대규모 모델을 훈련하여 대규모 모델 기능에 대한 자동화되고 재현 가능한 테스트와 검증을 수행합니다. 4월 30일 GitHub에 출시된 PandaLM은 세계 최초의 대형 평가 모델입니다. 관련 논문은 조만간 출판될 예정이다.

GitHub 주소: https://github.com/WeOpenML/PandaLM
PandaLM은 대형 모델이 훈련을 통해 다양한 대형 모델에서 생성된 텍스트에 대한 전반적인 인간 선호도를 학습하도록 하는 것을 목표로 합니다. 그리고 선호도에 따라 상대적인 평가를 수행하여 수동 또는 API 기반 평가 방법을 대체하여 비용을 절감하고 효율성을 높입니다. PandaLM의 가중치는 완전히 공개되어 있으며 하드웨어 임계값이 낮은 소비자급 하드웨어에서 실행될 수 있습니다. PandaLM의 평가 결과는 신뢰할 수 있고 완벽하게 재현 가능하며 데이터 보안을 보호할 수 있습니다. 평가 프로세스는 로컬에서 완료할 수 있으므로 기밀 데이터가 필요한 학계 및 부서에서 사용하기에 매우 적합합니다. PandaLM을 사용하는 것은 매우 간단하며 호출하는 데 코드 세 줄만 필요합니다. PandaLM의 평가 기능을 검증하기 위해 PandaLM 팀은 세 명의 전문 주석자를 초대하여 다양한 대형 모델의 출력을 독립적으로 판단하고 50개 필드의 1,000개 샘플을 포함하는 다양한 테스트 세트를 구축했습니다. 이 테스트 세트에서 PandaLM의 정확도는 ChatGPT의 94% 수준에 도달했으며 PandaLM은 모델의 장단점에 대해 수동 주석과 동일한 결론을 내렸습니다.
PandaLM 소개
현재 대형 모델을 평가하는 두 가지 주요 방법이 있습니다.
(1) 타사의 API 인터페이스를 호출하여
(2) 수동 주석.
그러나 데이터를 제3자 회사에 전송하면 삼성 직원이 코드를 유출하고 [1] 전문가를 고용하여 대량의 데이터에 라벨을 붙이는 것과 유사한 데이터 침해 문제가 발생할 수 있습니다. 해결해야 할 시급한 문제는 개인정보를 보호하고 신뢰할 수 있으며 재현 가능하고 저렴한 대형 모델 평가를 달성하는 방법입니다.
이 두 가지 평가 방법의 한계를 극복하기 위해 본 연구에서는 대형 모델의 성능을 평가하는 데 특별히 사용되는 심판 모델인 PandaLM을 개발했으며 사용자는 PandaLM을 호출하여 세 가지만으로 개인 정보 보호를 달성할 수 있습니다. 코드 라인 보호적이고 안정적이며 반복 가능하고 경제적인 대규모 모델 평가. PandaLM에 대한 교육 세부정보는 오픈 소스 프로젝트를 참조하세요.
대형 모델을 평가하는 PandaLM의 능력을 검증하기 위해 연구팀은 인간이 생성한 컨텍스트와 레이블을 사용하여 약 1,000개의 샘플로 구성된 다양한 인간 주석이 달린 테스트 세트를 구성했습니다. 테스트 데이터 세트에서 PandaLM-7B는 ChatGPT(gpt-3.5-turbo)의 94% 정확도를 달성했습니다.
PandaLM을 어떻게 사용하나요?
두 개의 서로 다른 대규모 모델이 동일한 지침과 맥락에 대해 서로 다른 응답을 생성하는 경우 PandaLM의 목표는 두 모델의 응답 품질을 비교하고 다음에 대한 비교 결과, 비교 근거 및 응답을 출력하는 것입니다. 참조 . 세 가지 비교 결과가 있습니다. 응답 1이 더 좋고, 응답 2가 더 좋습니다. 여러 대형 모델의 성능을 비교할 때 PandaLM을 사용하여 쌍별 비교를 수행한 다음 이러한 비교를 집계하여 모델 성능의 순위를 매기거나 모델의 부분 순서를 표시하면 됩니다. 이를 통해 다양한 모델 간의 성능 차이를 시각적으로 분석할 수 있습니다. PandaLM은 로컬에만 배포하면 되고 사람의 개입이 필요하지 않으므로 개인 정보를 보호하고 저렴한 방식으로 평가할 수 있습니다. 더 나은 해석 가능성을 제공하기 위해 PandaLM은 선택 항목을 자연어로 설명하고 추가 참조 응답 세트를 생성할 수도 있습니다.
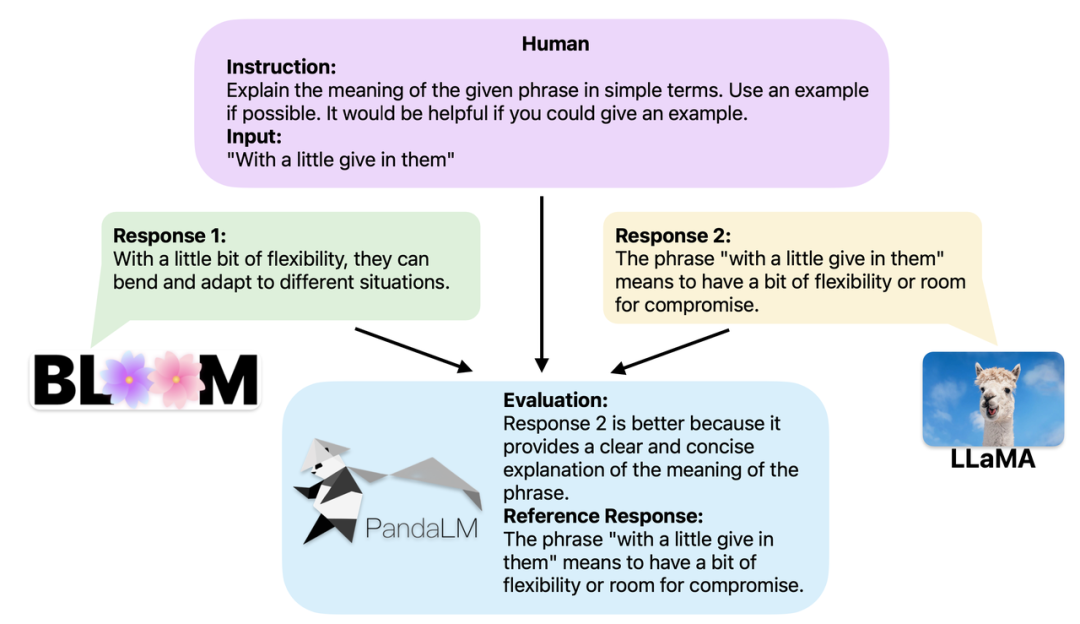
PandaLM은 사례 분석을 위한 웹 UI 사용을 지원할 뿐만 아니라 임의 모델 및 데이터에서 생성된 텍스트 평가를 위해 PandaLM을 호출하는 세 줄의 코드도 지원합니다. 많은 기존 모델과 프레임워크가 오픈 소스가 아니거나 로컬에서 추론하기 어려울 수 있다는 점을 고려하여 PandaLM에서는 모델 가중치를 지정하여 평가할 텍스트를 생성하거나 평가할 텍스트가 포함된 .json 파일을 직접 전달할 수 있습니다. 사용자는 PandaLM을 활용하여 모델 이름, HuggingFace 모델 ID 또는 .json 파일 경로 목록을 제공함으로써 사용자 정의 모델과 입력 데이터를 평가할 수 있습니다. 다음은 최소한의 사용 예입니다.

또한, 누구나 무료 평가를 위해 PandaLM을 유연하게 사용할 수 있도록 연구팀은 HuggingFace 웹사이트에 PandaLM의 모델 가중치를 공개했습니다. 다음 명령을 사용하여 PandaLM-7B 모델을 쉽게 로드할 수 있습니다.

PandaLM의 기능
PandaLM의 기능에는 재현성, 자동화, 개인 정보 보호, 저비용 및 높은 평가 수준 대기가 포함됩니다.
1. 재현성: PandaLM의 가중치는 공개되어 있으므로 언어 모델 출력에 무작위성이 있더라도 PandaLM의 평가 결과는 무작위 시드를 수정한 후에도 일관되게 유지됩니다. 온라인 API에 의존하는 평가 방법은 불투명한 업데이트로 인해 서로 다른 시점에 일관되지 않은 업데이트가 있을 수 있으며, 모델이 반복됨에 따라 API의 이전 모델에 더 이상 액세스할 수 없으므로 온라인 API 기반 평가가 재현되지 않는 경우가 많습니다.
2. 자동화, 개인정보 보호 및 저렴한 비용: 사용자는 PandaLM 모델을 로컬에 배포하고 기성 명령을 호출하기만 하면 다양한 대형 모델을 평가할 수 있으며 실시간 통신을 유지할 필요가 없으며 데이터 유출에 대해 걱정할 필요가 없습니다. 전문가를 고용하는 것과 같습니다. 동시에 PandaLM의 전체 평가 프로세스에는 API 수수료나 인건비가 포함되지 않아 매우 저렴합니다.
3. 평가 수준: PandaLM의 신뢰성을 검증하기 위해 본 연구에서는 세 명의 전문가를 고용하여 독립적으로 반복 주석을 완료하고 수동 주석 테스트 세트를 만들었습니다. 테스트 세트에는 각각 여러 작업이 포함된 50가지 시나리오가 포함되어 있습니다. 이 테스트 세트는 다양하고 신뢰할 수 있으며 텍스트에 대한 인간의 선호도와 일치합니다. 테스트 세트의 각 샘플은 지침과 컨텍스트, 서로 다른 대형 모델에서 생성된 두 가지 응답으로 구성되며 두 응답의 품질은 사람이 비교합니다.
이 연구에서는 주석자 간 차이가 큰 샘플을 제거하여 최종 테스트 세트에서 각 주석자의 IAA(Inter Annotator Agreement)가 0.85에 가깝도록 보장합니다. PandaLM 훈련 세트와 이 연구에서 생성된 수동으로 주석이 달린 테스트 세트 간에는 전혀 겹치는 부분이 없다는 점에 유의해야 합니다.
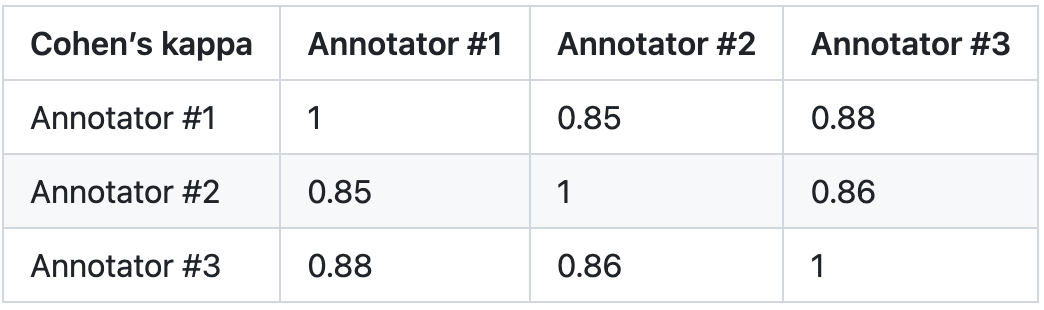
이러한 필터링된 샘플에는 판단을 돕기 위해 추가 지식이 필요하거나 얻기 어려운 정보가 필요하므로 인간이 정확하게 라벨을 붙이기가 어렵습니다. 필터링된 테스트 세트에는 1000개의 샘플이 포함되어 있고, 필터링되지 않은 원래 테스트 세트에는 2500개의 샘플이 포함되어 있습니다. 테스트 세트의 분포는 {0:105, 1:422, 2:472}입니다. 여기서 0은 두 응답의 품질이 유사함을 나타내고, 1은 응답 1이 더 우수함을 나타내고, 2는 응답 2가 더 우수함을 나타냅니다.
인간 테스트 세트를 기준으로 PandaLM과 gpt-3.5-turbo의 성능 비교는 다음과 같습니다.
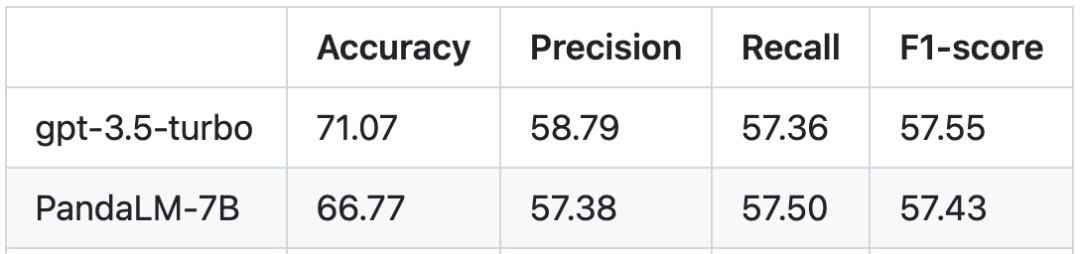
PandaLM-7B가 gpt-3.5-in에 도달한 것을 볼 수 있습니다. 정확도 Turbo는 94% 수준에 도달하며 정밀도, 재현율, F1 점수 측면에서 PandaLM-7B는 gpt-3.5-turbo와 거의 동일합니다. PandaLM-7B는 이미 gpt-3.5-turbo와 동등한 대규모 모델 평가 능력을 갖추고 있다고 할 수 있습니다.
본 연구에서는 테스트 세트의 정확성, 정밀성, 재현율, F1 점수 외에도 비슷한 크기의 5개 대형 오픈 소스 모델 간의 비교 결과도 제공합니다. 이 연구는 먼저 동일한 훈련 데이터를 사용하여 5개 모델을 미세 조정한 다음 인간, gpt-3.5-turbo 및 PandaLM을 사용하여 5개 모델의 쌍 비교를 수행했습니다. 아래 표의 첫 번째 행에 있는 첫 번째 튜플(72, 28, 11)은 Bloom-7B보다 나은 LLaMA-7B 응답이 72개 있고 Bloom-7B보다 나쁜 LLaMA-7B 응답이 28개 있음을 나타냅니다. 모델에는 비슷한 품질의 응답이 11개 있었습니다. 따라서 이 예에서 인간은 LLaMA-7B가 Bloom-7B보다 낫다고 생각합니다. 다음 세 표의 결과는 인간, gpt-3.5-turbo 및 PandaLM-7B가 각 모델의 우월성과 열등성에 대한 판단에서 완전히 일관됨을 보여줍니다.
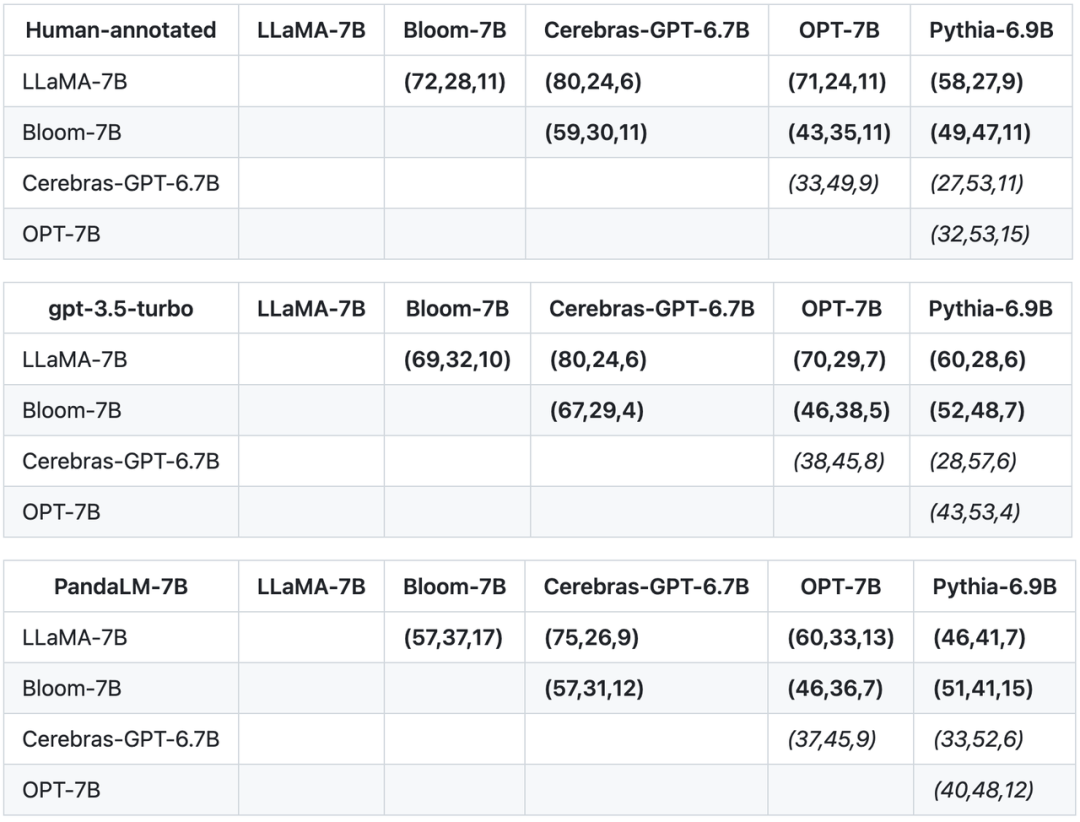
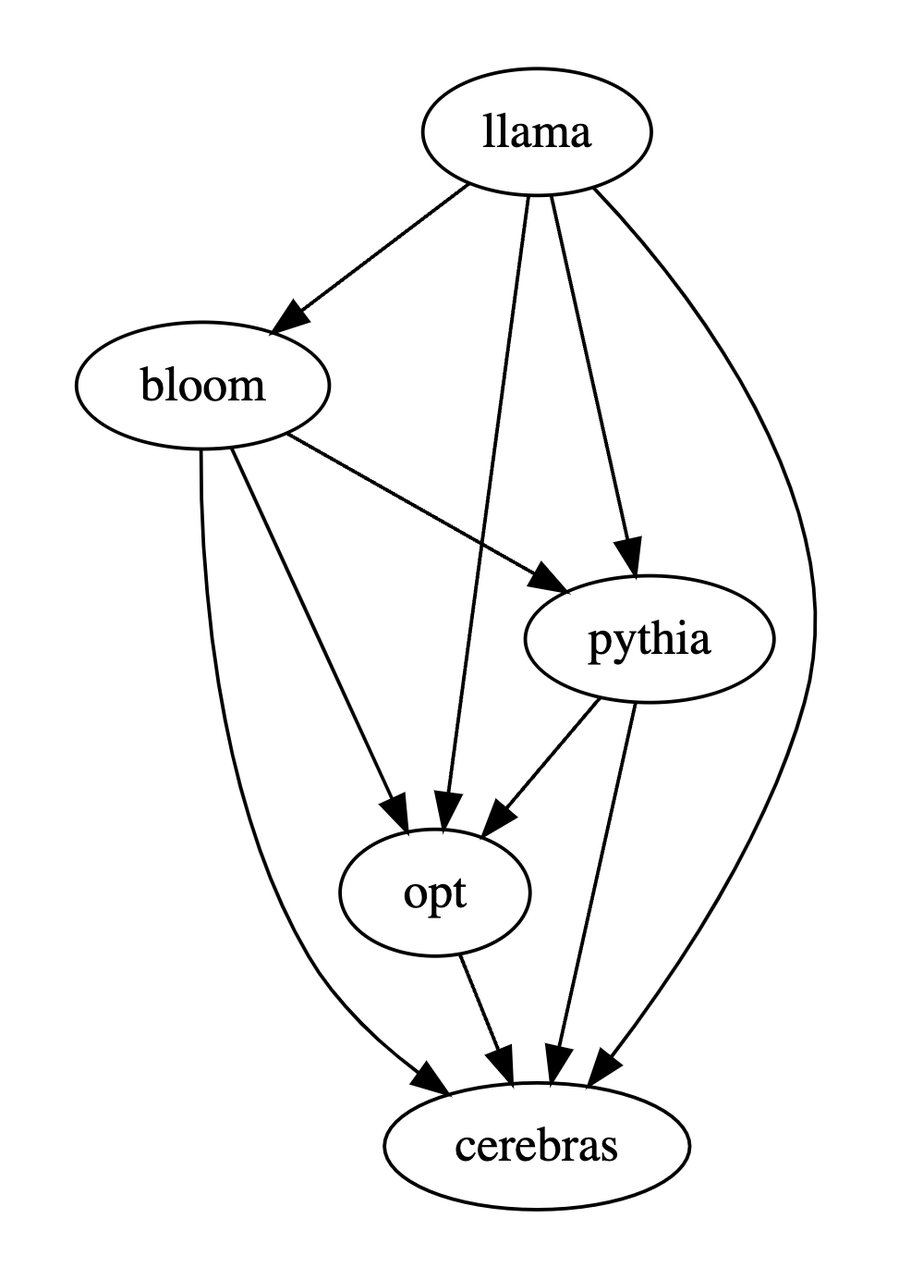
본 연구에서는 위의 세 가지 테이블을 기반으로 모델의 장단점에 대한 부분 순서 다이어그램을 생성했습니다. 이 부분 순서 다이어그램은 다음과 같이 표현될 수 있는 전체 순서 관계를 구성합니다. 7B > 블룸-7B > 피티아-6.9B > 세레브라스-GPT-6.7B.
요약
요약하자면, PandaLM은 수동 평가 및 타사 API 외에 대규모 모델을 평가하기 위한 세 번째 옵션을 제공합니다. PandaLM의 평가 수준은 높을 뿐만 아니라 결과의 재현성이 뛰어나고 평가 프로세스가 고도로 자동화되어 있으며 개인정보가 보호되고 비용이 저렴합니다. 연구팀은 PandaLM이 학계와 산업계에서 대규모 모델에 대한 연구를 촉진하고 더 많은 사람들이 이 연구 분야의 발전으로 혜택을 누릴 수 있게 해줄 것이라고 믿습니다. 누구나 PandaLM 프로젝트에 관심을 가져주세요. 더 많은 교육, 테스트 세부 정보, 관련 기사 및 후속 작업이 프로젝트 웹사이트(https://github.com/WeOpenML/PandaLM
)에 게시됩니다. the 저자 팀
저자 Wang Yitong*은 북경 대학교 소프트웨어 공학 국립 공학 센터(박사) 및 서호 대학교(연구 조교) 출신이며, Yu Zhuohao*, Zeng Zhengran , Jiang Chaoya, Xie Rui, Ye Wei† 및 Zhang Shikun†은 Peking University 소프트웨어 공학 국립 엔지니어링 센터 출신이고, Yang Linyi, Wang Cunxiang 및 Zhang Yue†는 Westlake 대학교 출신이고 Heng Qiang은 North Carolina 주립대학교 출신입니다. University, Chen Hao는 Carnegie Mellon University 출신이고 Wang Jindong과 Xie Xing은 Microsoft Research Asia 출신입니다. *는 공동 제1저자를 나타내고, †는 공동 교신저자를 나타냅니다.
위 내용은 재현 가능하고 자동화되었으며 저비용이며 높은 수준의 평가를 제공하는 최초의 대형 모델을 자동으로 평가하는 대형 모델인 PandaLM이 출시되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!