
머신러닝 가속기의 5가지 유형을 간략하게 설명하세요.

- 王林앞으로
- 2023-05-25 14:55:251750검색
번역가 | Bugatti
리뷰어 | Sun Shujuan
지난 10년은 딥러닝의 시대였습니다. 우리는 AlphaGo부터 DELL-E 2까지 일련의 대규모 이벤트를 기대하고 있습니다. 알렉사 디바이스, 광고 추천, 창고 로봇, 자율주행차 등 인공지능(AI)이 주도하는 수많은 제품이나 서비스가 일상생활에 등장했다.

최근 몇 년 동안 딥 러닝 모델의 규모가 기하급수적으로 증가했습니다. 이는 새로운 소식이 아닙니다. Wu Dao 2.0 모델에는 1조 7500억 개의 매개변수가 포함되어 있으며 SageMaker 교육 플랫폼의 240 ml.p4d.24xlarge 인스턴스에서 GPT-3을 교육하는 데 약 25일밖에 걸리지 않습니다.
그러나 딥 러닝 훈련 및 배포가 발전함에 따라 점점 더 어려워지고 있습니다. 딥 러닝 모델이 발전함에 따라 확장성과 효율성은 교육 및 배포에 있어 두 가지 주요 과제입니다.
이 문서에서는 기계 학습(ML) 가속기의 5가지 주요 유형을 요약합니다.
AI 엔지니어링의 ML 수명 주기를 이해하세요
ML 가속기를 포괄적으로 소개하기 전에 ML 수명 주기를 살펴보는 것이 좋습니다.
ML 수명주기는 데이터와 모델의 수명주기입니다. 데이터는 ML의 뿌리라고 할 수 있으며 모델의 품질을 결정합니다. 수명주기의 모든 측면에는 가속화의 기회가 있습니다.
MLOps는 ML 모델 배포 프로세스를 자동화할 수 있습니다. 그러나 운영 특성상 AI 워크플로우의 수평적 프로세스에 국한되어 훈련 및 배포를 근본적으로 개선할 수 없습니다.
AI 엔지니어링은 MLOps의 범위를 훨씬 뛰어넘어 기계 학습 워크플로 프로세스는 물론 교육 및 배포 아키텍처 전체(수평 및 수직)를 설계할 수 있습니다. 또한 전체 ML 수명주기의 효율적인 조정을 통해 배포 및 교육을 가속화합니다.
전체적인 ML 수명 주기와 AI 엔지니어링을 기반으로 ML 가속기(또는 가속 측면)에는 하드웨어 가속기, AI 컴퓨팅 플랫폼, AI 프레임워크, ML 컴파일러, 클라우드 서비스 등 5가지 주요 유형이 있습니다. 먼저 아래의 관계 다이어그램을 살펴보세요.
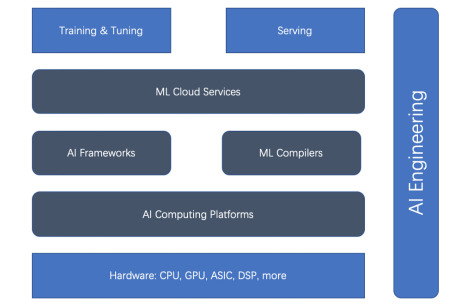
그림 1. 훈련과 배포 가속기의 관계
하드웨어 가속기와 AI 프레임워크가 가속의 주류임을 알 수 있습니다. 그러나 최근에는 ML 컴파일러, AI 컴퓨팅 플랫폼, ML 클라우드 서비스가 점점 더 중요해지고 있습니다.
아래에 하나씩 소개합니다.
1. AI 프레임워크
ML 훈련 및 배포를 가속화하려면 올바른 AI 프레임워크를 선택하는 것을 피할 수 없습니다. 안타깝게도 모든 경우에 적용되는 완벽하거나 최적의 AI 프레임워크는 없습니다. 연구 및 생산에 널리 사용되는 세 가지 AI 프레임워크는 TensorFlow, PyTorch 및 JAX입니다. 이들은 각각 사용 용이성, 제품 성숙도, 확장성 등 다양한 측면에서 탁월합니다.
TensorFlow: TensorFlow는 대표적인 AI 프레임워크입니다. TensorFlow는 처음부터 딥 러닝 오픈소스 커뮤니티를 장악해 왔습니다. TensorFlow Serving은 잘 정의된 성숙한 플랫폼입니다. 인터넷과 IoT의 경우 TensorFlow.js와 TensorFlow Lite도 성숙합니다.
그러나 딥 러닝의 초기 탐구의 한계로 인해 TensorFlow 1.x는 Python이 아닌 방식으로 정적 그래프를 구축하도록 설계되었습니다. 이는 PyTorch가 연구 분야에서 빠르게 발전할 수 있도록 하는 "열심히" 모드를 사용하여 즉각적인 평가를 하는 데 장애가 됩니다. TensorFlow 2.x는 따라잡으려고 노력하지만 불행히도 TensorFlow 1.x에서 2.x로 업그레이드하는 것은 번거롭습니다.
TensorFlow는 전반적인 사용을 더 쉽게 하기 위해 Keras를 도입하고, 최하위 계층의 속도를 높이기 위해 최적화 컴파일러인 XLA(Accelerated Linear Algebra)도 도입했습니다.
PyTorch: eager 모드와 Python과 유사한 접근 방식을 갖춘 PyTorch는 오늘날 딥 러닝 커뮤니티의 일꾼이며 연구부터 생산까지 모든 분야에서 사용됩니다. TorchServe 외에도 PyTorch는 Kubeflow와 같은 프레임워크에 구애받지 않는 플랫폼과도 통합됩니다. 또한, PyTorch의 인기는 Hugging Face의 Transformers 라이브러리의 성공과 불가분의 관계에 있습니다.
JAX: Google에서는 기기 가속 NumPy 및 JIT를 기반으로 하는 JAX를 출시했습니다. PyTorch가 몇 년 전 그랬던 것처럼, 이는 연구 커뮤니티에서 빠르게 인기를 얻고 있는 보다 네이티브한 딥 러닝 프레임워크입니다. 하지만 구글이 주장하는 것처럼 아직은 "공식적인" 구글 제품이 아닙니다.
2. 하드웨어 가속기
NVIDIA의 GPU가 딥 러닝 훈련을 가속화할 수 있다는 것은 의심의 여지가 없지만 원래는 비디오 카드용으로 설계되었습니다.
범용 GPU가 등장한 이후 신경망 훈련에 사용되는 그래픽 카드가 큰 인기를 끌었습니다. 이러한 범용 GPU는 서브루틴 렌더링뿐만 아니라 임의의 코드를 실행할 수 있습니다. NVIDIA의 CUDA 프로그래밍 언어는 C와 유사한 언어로 임의의 코드를 작성하는 방법을 제공합니다. 범용 GPU는 상대적으로 편리한 프로그래밍 모델, 대규모 병렬성 메커니즘 및 높은 메모리 대역폭을 갖추고 있으며 이제 신경망 프로그래밍을 위한 이상적인 플랫폼을 제공합니다.
현재 NVIDIA는 데스크탑부터 모바일, 워크스테이션, 모바일 워크스테이션, 게임 콘솔 및 데이터 센터에 이르기까지 다양한 GPU를 지원합니다.
Nvidia GPU의 큰 성공과 함께 AMD의 GPU 및 Google의 TPU ASIC과 같은 후속 제품이 부족하지 않았습니다.
3. AI 컴퓨팅 플랫폼
앞서 언급했듯이 ML 학습 및 배포 속도는 하드웨어(예: GPU 및 TPU)에 따라 크게 달라집니다. 이러한 드라이버 플랫폼(예: AI 컴퓨팅 플랫폼)은 성능에 매우 중요합니다. 잘 알려진 AI 컴퓨팅 플랫폼에는 CUDA와 OpenCL이라는 두 가지가 있습니다.
CUDA: CUDA(Compute Unified Device Architecture)는 NVIDIA가 2007년에 출시한 병렬 프로그래밍 패러다임입니다. 그래픽 프로세서 및 GPU의 다양한 범용 애플리케이션용으로 설계되었습니다. CUDA는 NVIDIA의 Tesla 아키텍처 GPU만 지원하는 독점 API입니다. CUDA가 지원하는 그래픽 카드에는 GeForce 8 시리즈, Tesla 및 Quadro가 포함됩니다.
OpenCL: OpenCL(개방형 컴퓨팅 언어)은 원래 Apple에서 개발되었으며 현재 CPU, GPU, DSP 및 기타 유형의 프로세서를 포함한 이기종 컴퓨팅을 위해 Khronos 팀에서 유지관리하고 있습니다. 이 이식 가능한 언어는 Nvidia의 GPU를 포함한 모든 하드웨어 플랫폼에서 고성능을 구현할 수 있을 만큼 충분히 적응 가능합니다.
NVIDIA는 이제 R465 이상의 드라이버와 함께 사용할 수 있도록 OpenCL 3.0을 준수합니다. OpenCL API를 사용하면 GPU에서 C 프로그래밍 언어의 제한된 하위 집합으로 작성된 계산 커널을 시작할 수 있습니다.
4. ML 컴파일러
ML 컴파일러는 훈련 및 배포를 가속화하는 데 중요한 역할을 합니다. ML 컴파일러는 대규모 모델 배포의 효율성을 크게 향상시킬 수 있습니다. Apache TVM, LLVM, Google MLIR, TensorFlow XLA, Meta Glow, PyTorch nvFuser 및 Intel PlaidML과 같은 널리 사용되는 컴파일러가 많이 있습니다.
5. ML 클라우드 서비스
ML 클라우드 플랫폼 및 서비스는 클라우드에서 ML 플랫폼을 관리합니다. 효율성을 높이기 위해 여러 가지 방법으로 최적화할 수 있습니다.
Amazon SageMaker를 예로 들어 보겠습니다. 선도적인 ML 클라우드 플랫폼 서비스입니다. SageMaker는 준비, 구축, 교육/조정부터 배포/관리까지 ML 수명주기에 대한 광범위한 기능을 제공합니다.
GPU의 다중 모델 엔드포인트, 이기종 클러스터를 사용한 비용 효율적인 교육, CPU 기반 ML 추론에 적합한 독점 Graviton 프로세서 등 교육 및 배포 효율성을 향상시키기 위해 여러 측면을 최적화합니다.
결론
딥 러닝 교육 및 배포 규모가 계속 확장됨에 따라 과제도 점점 더 커지고 있습니다. 딥 러닝 훈련 및 배포의 효율성을 높이는 것은 복잡합니다. ML 수명 주기에 따라 ML 교육 및 배포를 가속화할 수 있는 5가지 측면은 AI 프레임워크, 하드웨어 가속기, 컴퓨팅 플랫폼, ML 컴파일러 및 클라우드 서비스입니다. AI 엔지니어링은 이 모든 것을 조정하고 엔지니어링 원칙을 사용하여 전반적으로 효율성을 향상시킬 수 있습니다.
원제: 5가지 ML 가속기 유형, 저자: Luhui Hu
위 내용은 머신러닝 가속기의 5가지 유형을 간략하게 설명하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!