
Python으로 동적 시각화 차트를 그리는 것은 정말 멋집니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-24 12:01:062625검색

스토리텔링은 데이터 과학자에게 중요한 기술입니다. 자신의 생각을 표현하고 다른 사람을 설득하기 위해서는 효과적인 의사소통이 필요합니다. 그리고 아름다운 시각화는 이 작업을 위한 훌륭한 도구입니다.
이 기사에서는 데이터 스토리를 더욱 아름답고 효과적으로 만들 수 있는 5가지 비전통적인 시각화 기술을 소개합니다. 여기에서는 Python의 Plotly 그래픽 라이브러리를 사용하여 애니메이션 차트와 대화형 차트를 쉽게 생성할 수 있습니다.
모듈 설치
아직 Plotly를 설치하지 않았다면 터미널에서 다음 명령을 실행하여 설치를 완료하세요.
pip install plotly
동적 그래프 시각화
이 지표 또는 저 지표의 진화를 연구할 때 우리는 종종 다음과 같은 작업을 수행합니다. 시간 데이터. Plotly 애니메이션 도구를 사용하면 아래와 같이 단 한 줄의 코드로 시간에 따른 데이터 변화를 볼 수 있습니다.
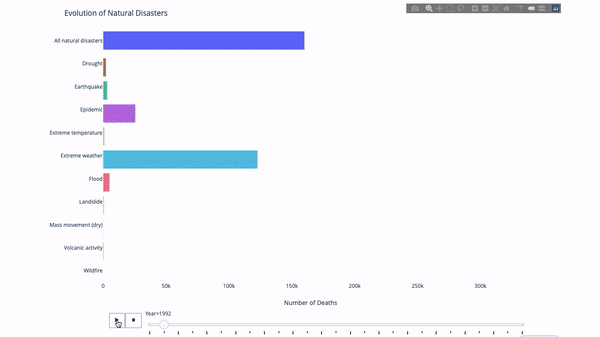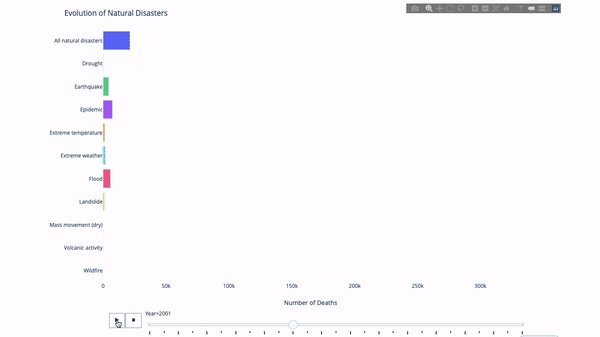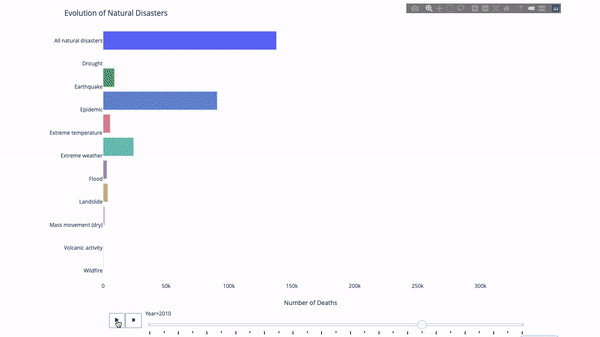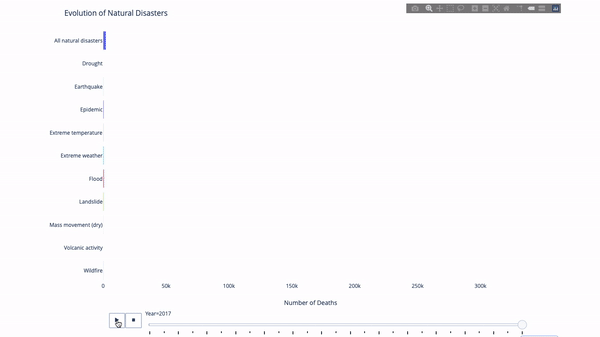
코드는 다음과 같습니다.
import plotly.express as px from vega_datasets import data df = data.disasters() df = df[df.Year > 1990] fig = px.bar(df, y="Entity", x="Deaths", animation_frame="Year", orientation='h', range_x=[0, df.Deaths.max()], color="Entity") # improve aesthetics (size, grids etc.) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', title_text='Evolution of Natural Disasters', showlegend=False) fig.update_xaxes(title_text='Number of Deaths') fig.update_yaxes(title_text='') fig.show()
필터링할 시간 변수가 있는 한, 거의 모든 차트에 애니메이션이 적용됩니다. 다음은 분산형 차트 애니메이션의 예입니다.
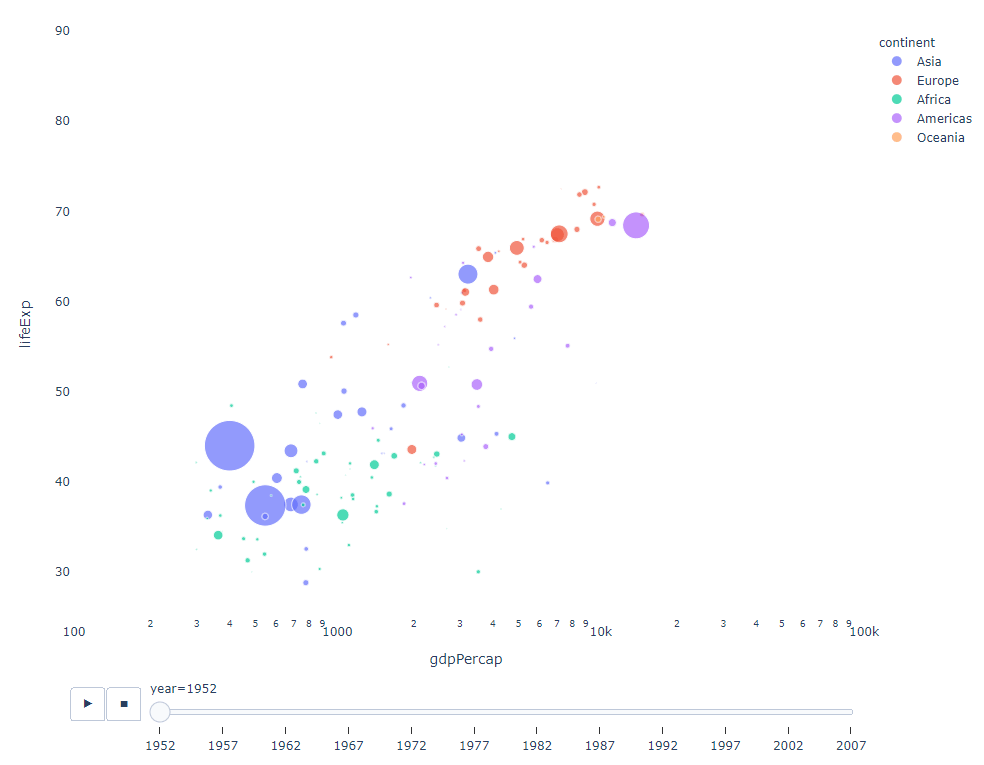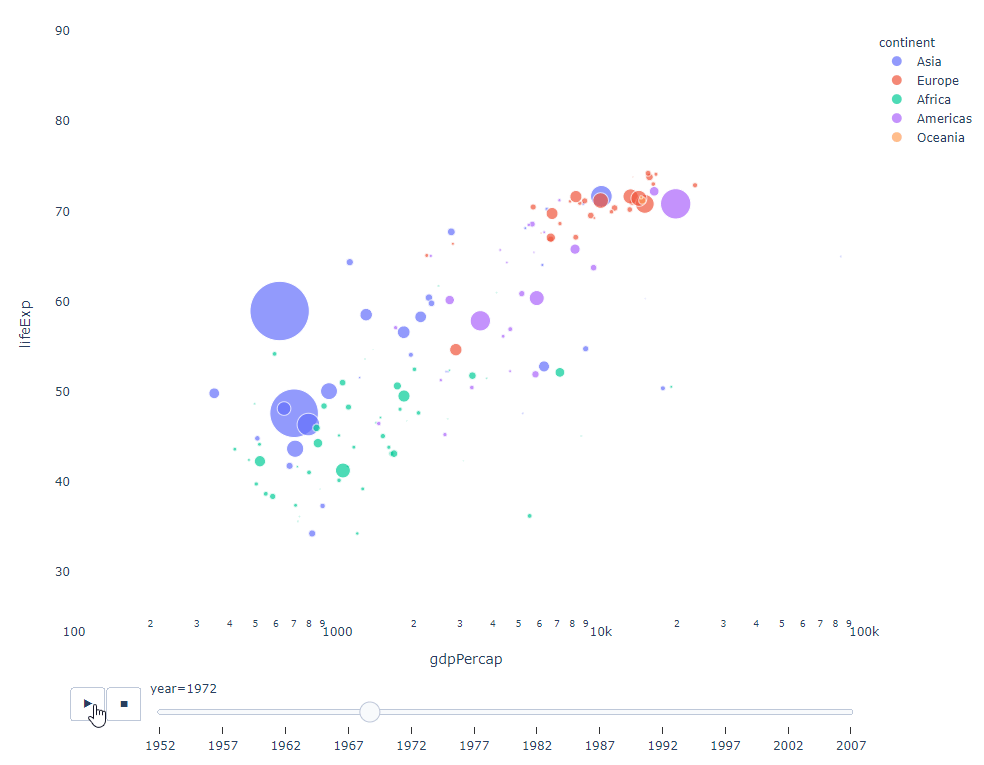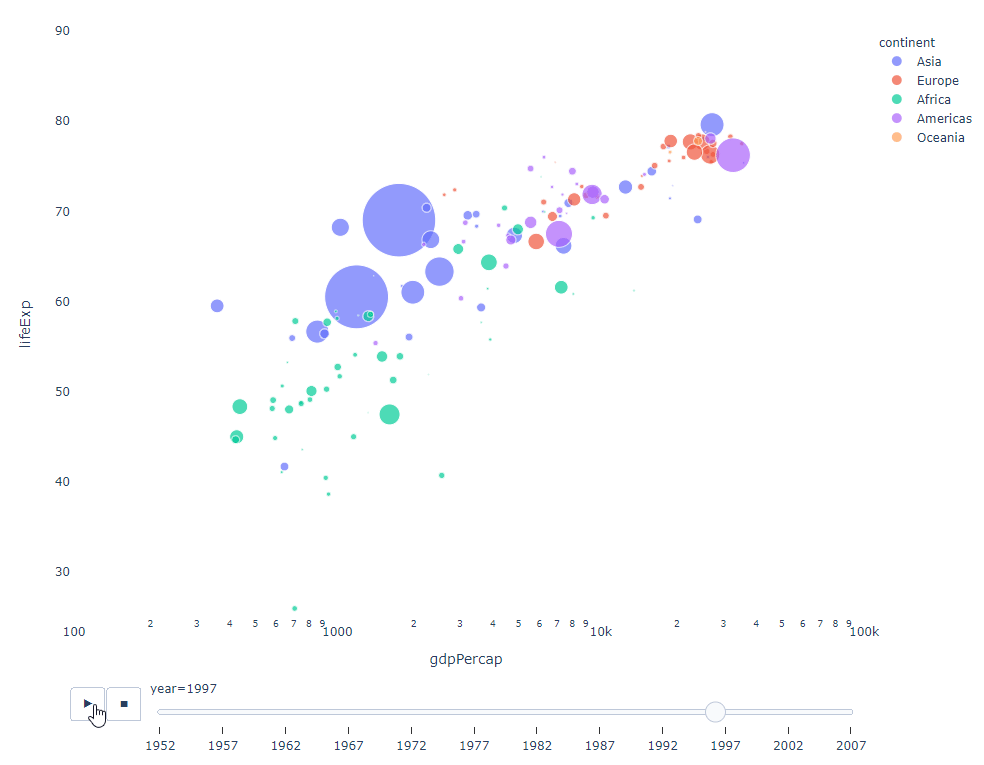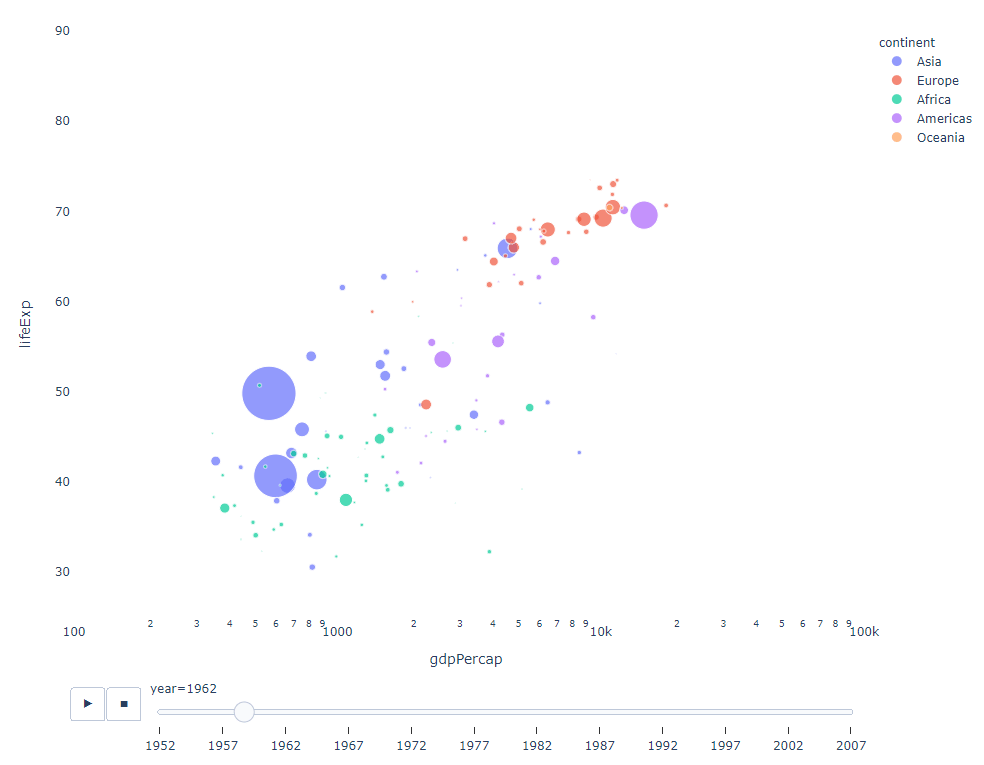
import plotly.express as px df = px.data.gapminder() fig = px.scatter( df, x="gdpPercap", y="lifeExp", animation_frame="year", size="pop", color="continent", hover_name="country", log_x=True, size_max=55, range_x=[100, 100000], range_y=[25, 90], # color_continuous_scale=px.colors.sequential.Emrld ) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
선버스트 차트
선버스트 차트는 문별로 그룹을 시각화하는 좋은 방법입니다. 하나 이상의 범주형 변수로 주어진 수량을 분류하려면 태양 차트를 사용하세요.
평균 팁 데이터를 성별과 시간대에 따라 분류한다고 가정하면 이 이중 그룹별 진술은 테이블에 비해 시각화를 통해 더 효과적으로 표시될 수 있습니다.
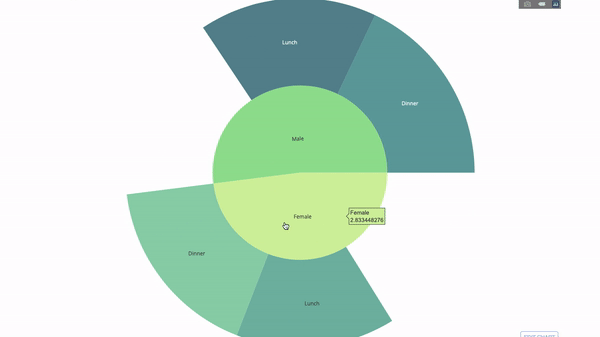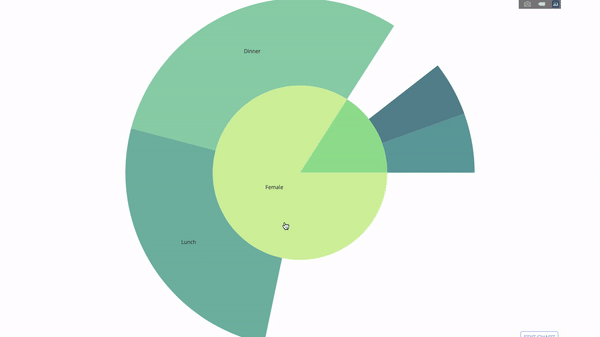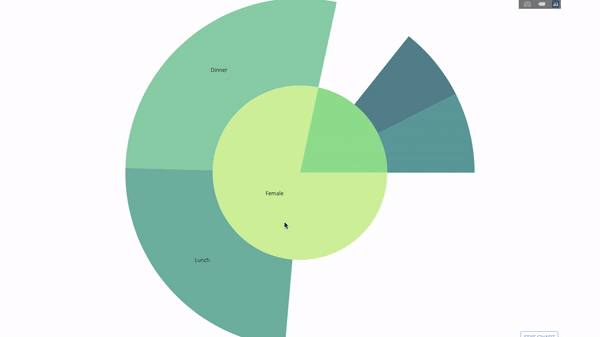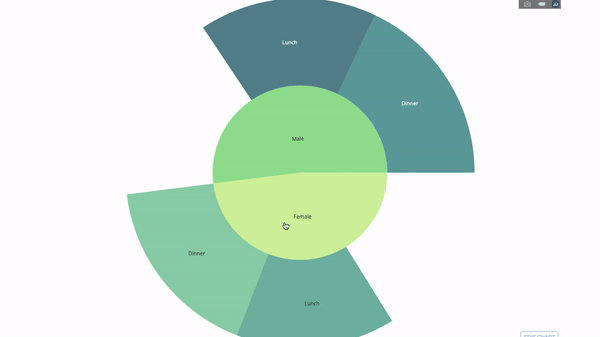
이 차트는 대화형이므로 카테고리를 직접 클릭하고 탐색할 수 있습니다. 모든 범주를 정의하고, 범주 사이의 계층 구조를 선언하고(아래 코드의 parent 매개변수 참조) 해당 값을 할당하기만 하면 됩니다. 이 경우 이는 group by 문의 출력입니다.
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
이제 이 계층 구조에 레이어를 하나 더 추가합니다.
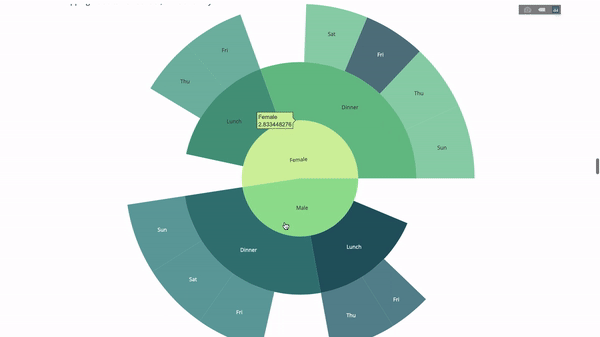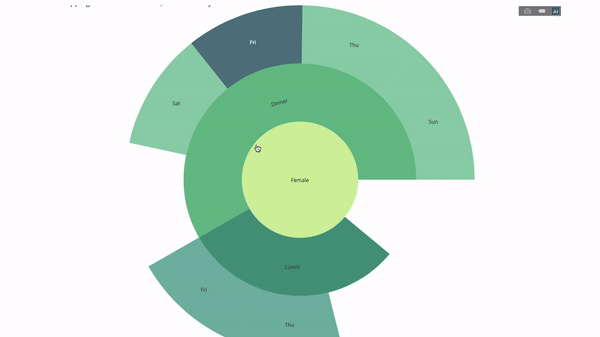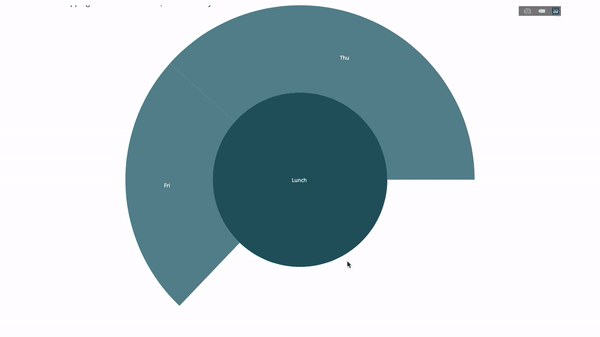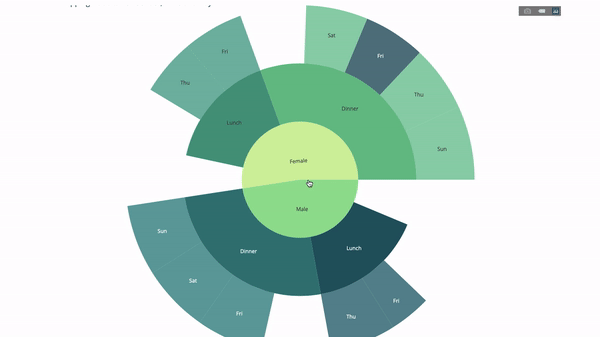
이를 위해 세 개의 범주형 변수를 포함하는 문별 다른 그룹의 값을 추가합니다.
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri', 'Sat', 'Sun', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
포인터 차트
포인터 차트는 단지 보기 위한 것입니다. KPI와 같은 성공 측정항목을 보고하고 목표에 얼마나 근접했는지 보여줄 때 이 유형의 차트를 사용하세요.
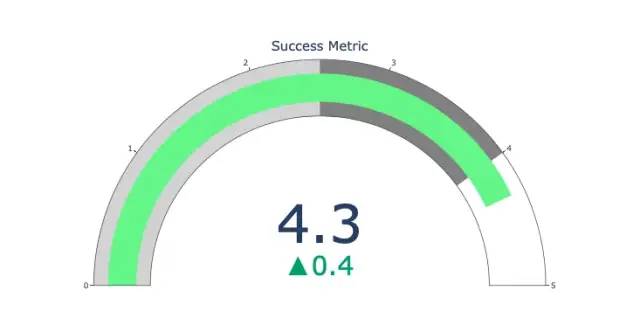
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
Sankey Plot
범주형 변수 간의 관계를 탐색하는 또 다른 방법은 다음 평행 좌표 플롯입니다. 언제든지 값을 끌어서 놓기, 강조 표시 및 탐색할 수 있어 프레젠테이션에 적합합니다.
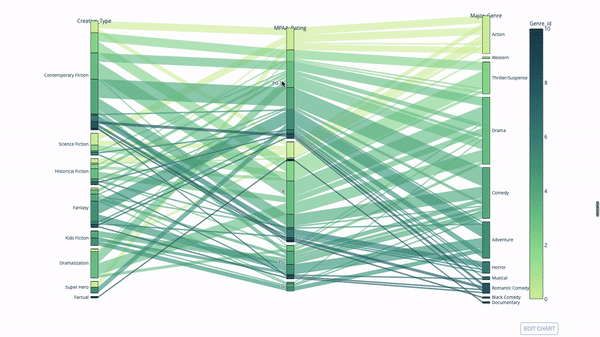
코드는 다음과 같습니다.
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_categories( df, dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'], color="Genre_id", color_continuous_scale=px.colors.sequential.Emrld, ) fig.show()
평행 좌표 플롯
평행 좌표 플롯은 위 차트에서 파생된 것입니다. 여기서 각 문자열은 단일 관측값을 나타냅니다. 이는 이상값(나머지 데이터에서 멀리 떨어져 있는 단일 선), 군집, 추세 및 중복 변수(예: 두 변수의 값이 비슷한 경우 동일한 수평선에 위치함)를 식별하는 데 사용할 수 있는 방법입니다. 모든 관찰에서), 중복성의 존재를 나타내는 유용한 도구입니다.
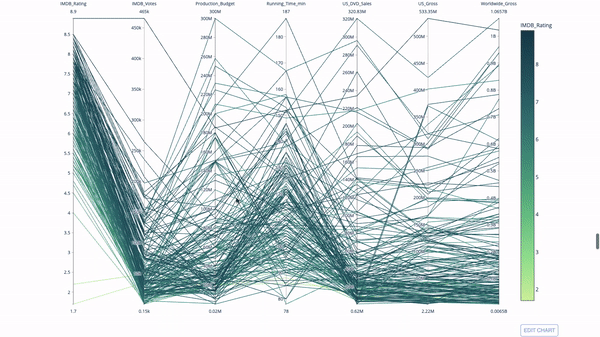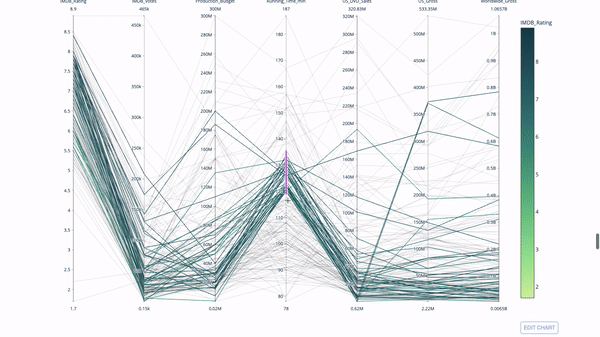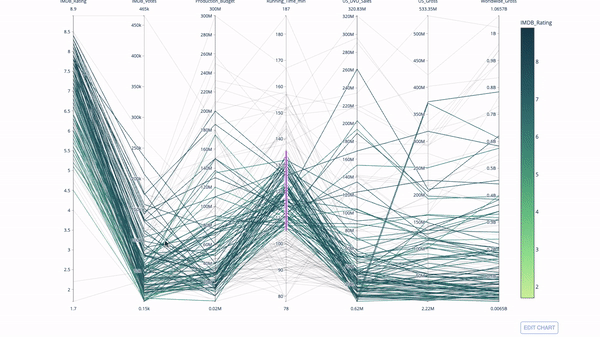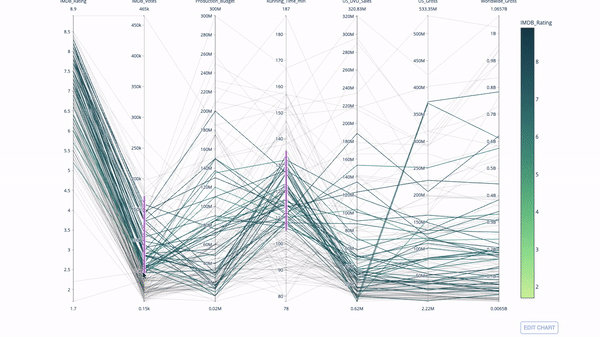
코드는 다음과 같습니다.
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_coordinates( df, dimensions=[ 'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales' ], color='IMDB_Rating', color_continuous_scale=px.colors.sequential.Emrld) fig.show()
위 내용은 Python으로 동적 시각화 차트를 그리는 것은 정말 멋집니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!