
Baidu Wenxinyiyan은 국내 모델 중 꼴찌입니까? 나는 혼란스러웠다

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-24 09:25:051852검색
Xi Xiaoyao 기술 토크 원본
작성자 | Mengjiang 판매 최근 저희 공개 계정 커뮤니티에서는 SuperClue 리뷰라는 스크린샷을 전달하고 있습니다. iFlytek은 공식 계정에서도 이를 홍보했습니다.

iFlytek Spark 모델이 출시된 지 얼마 안 됐고 많이 플레이해 본 적이 없기 때문에 이 모델이 정말 가장 강력한 모델인지에 대해서는 감히 결론을 내릴 수 없습니다. 중국.
하지만 이 리뷰 스크린샷에서는 현재 국내에서 가장 인기 있는 모델인 Baidu Wenxinyiyan이 소규모 학술 오픈 소스 모델인 ChatGLM-6B조차 이길 수 없습니다. 이는 저자 자신의 경험과 심각하게 일치하지 않을 뿐만 아니라 전문 NLP 기술 커뮤니티에서도 모두가 혼란을 표현했습니다.
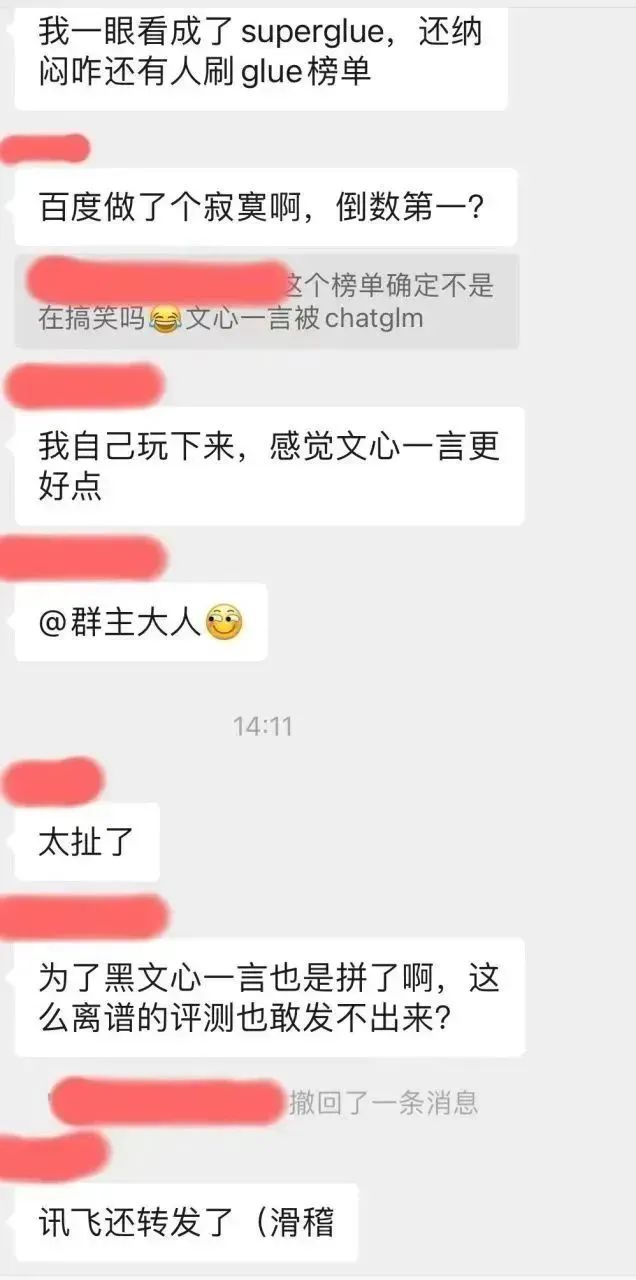
호기심으로 저자는 이 슈퍼클루 목록 github로 이동했습니다. 보고 싶습니다. 이 평가 결론이 도출되는 방법: https://www.php.cn/link/97c8dd44858d3568fdf9537c4b8743b2
우선 저자는 이 저장소에 몇 가지 문제가 있음을 발견했습니다.
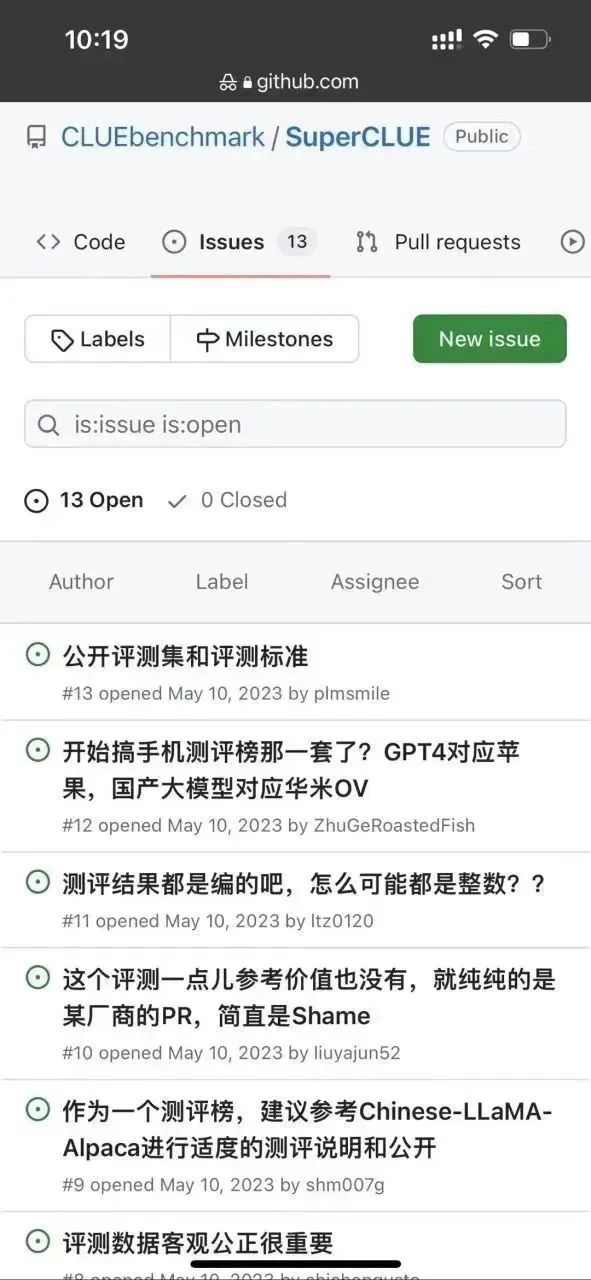
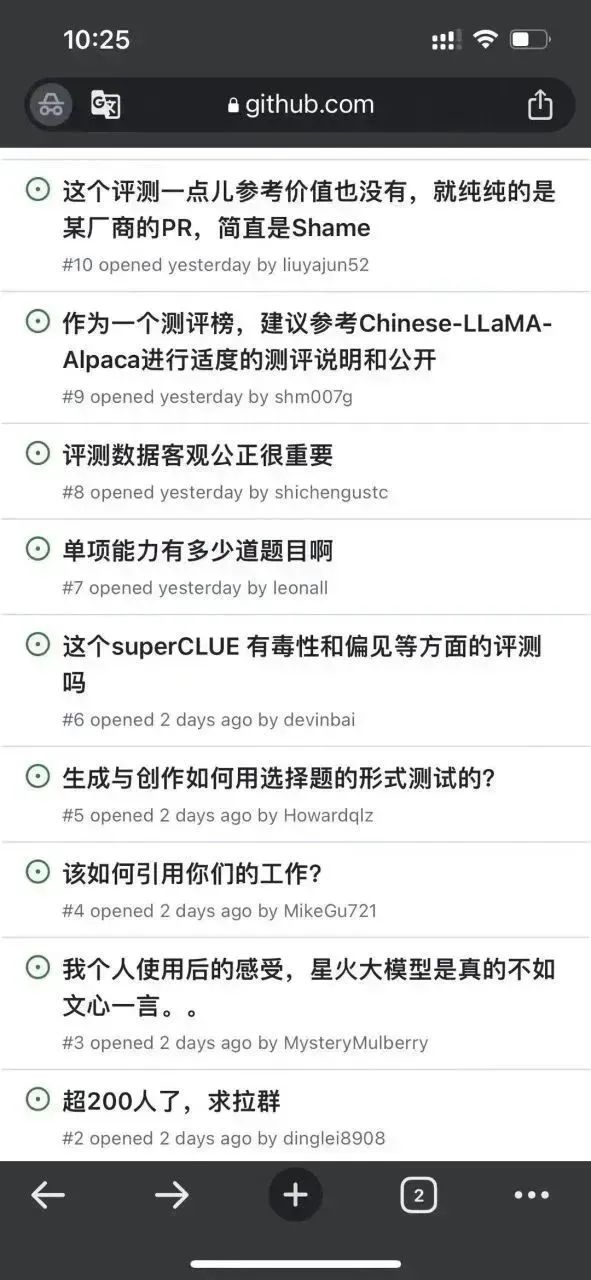
그것은 보인다 이 터무니없는 감정은 작가 본인뿐만 아니라, 역시 대중의 시선은 여전히 날카롭다. . .
작가는 이 목록의 평가 방법을 자세히 살펴보았습니다.

오빠, 소위 대형 생성 모델 테스트는 모두 모델에게 객관식 질문을 하도록 요구하는 것이라는 사실이 밝혀졌습니다. . .
분명히 이 객관식 평가 방법은 BERT 시대의 차별적 AI 모델을 겨냥한 것입니다. 당시 AI 모델은 일반적으로 생성 기능이 없고 차별 기능만 있었습니다(예: , 질문에 대한 정답이 무엇인지, 두 텍스트의 의미가 일치하는지 판단하는 옵션 중에서 텍스트가 어떤 카테고리에 속하는지 결정할 수 있습니다.
생성 모델의 평가는 차별 모델의 평가와 상당히 다릅니다.
예를 들어 기계 번역과 같은 특수 생성 작업의 경우 일반적으로 BLEU와 같은 평가 지표를 사용하여 모델에서 생성된 응답과 참조 응답 간의 "어휘 및 구문 적용 범위"를 감지합니다. 그러나 기계 번역과 같은 참조 응답이 포함된 생성 작업은 거의 없으며 대부분의 생성 평가에는 수동 평가가 필요합니다.
예를 들어 채팅 스타일 대화 생성, 텍스트 스타일 전송, 장 생성, 제목 생성 및 텍스트 요약과 같은 생성 작업에서는 각 모델을 평가하여 자유롭게 응답을 생성한 다음 생성된 응답의 품질을 수동으로 비교해야 합니다. 이러한 다양한 모델을 사용하거나 작업 요구 사항이 충족되는지 수동으로 확인합니다.
현재 AI 대회는 모델 판별 역량 경쟁이 아닌 모델 생성 역량 경쟁입니다. 평가해야 할 가장 강력한 것은 더 이상 냉담한 학술 목록이 아닌 실제 사용자 평판입니다. 게다가 모델 생성 기능을 전혀 테스트하지 않는 목록입니다.
지난 몇 년을 되돌아보며 -
2019년 OpenAI가 GPT-2를 출시했을 때 우리는 순위를 갱신하기 위한 트릭을 쌓았습니다.
2020년 OpenAI가 GPT-3을 출시했을 때 우리는 트릭을 쌓았습니다. 순위 새로고침 ;
2021~2022년에 FLAN, T0, InstructGPT 등과 같은 지침 튜닝 및 RLHF 작업이 발생했을 때 여전히 순위를 새로 고치기 위해 트릭을 쌓아야 한다고 주장하는 팀이 많이 있습니다...
희망합니다 생성 모델 군비 경쟁의 물결 속에서 우리는 같은 실수를 다시는 하지 않기를 바랍니다.
그렇다면 생성 AI 모델은 어떻게 테스트해야 할까요?
죄송합니다. 편견 없는 테스트를 달성하려면 생성 모델을 직접 개발하는 것보다 매우 어렵고 훨씬 더 어렵다고 앞서 말씀드렸습니다. 어려움은 무엇입니까? 몇 가지 구체적인 질문:
- 평가 차원을 어떻게 나눌 수 있나요? 이해, 기억, 추론, 표현으로? 전문 분야별로? 아니면 전통적인 NLP 생성 평가 작업을 결합하시겠습니까?
- 평가자는 어떻게 교육을 받나요? 코딩, 디버깅, 수학적 파생, 재무, 법률, 의료 Q&A 등 전문적인 기준이 매우 높은 테스트 질문의 경우 테스트할 인력을 어떻게 모집합니까?
- 매우 주관적인 시험 문제(예: Xiaohongshu 스타일 카피라이팅 생성)에 대한 평가 기준을 어떻게 정의합니까?
- 몇 가지 일반적인 작문 질문을 하는 것이 모델의 텍스트 생성/작성 능력을 나타낼 수 있나요?
- 모델의 텍스트 생성 하위 기능을 살펴보세요. 장 생성, 질문 및 답변 생성, 번역, 요약, 스타일 이전이 포함되나요? 각 작업의 비율이 균일합니까? 심사기준이 명확한가요? 통계적으로 유의미한?
- 위 질문과 답변 생성 하위 작업에는 과학, 의료, 자동차, 엄마와 아기, 금융, 공학, 정치, 군사, 엔터테인먼트 등 수직 카테고리가 모두 포함되나요? 비율이 균일한가요?
- 대화 능력을 평가하는 방법은 무엇입니까? 일관성, 다양성, 주제의 깊이, 대화의 의인화를 위한 점검 과제를 어떻게 설계할 것인가?
- 동일 능력시험에 간단한 문제, 중간 난이도 문제, 복잡한 장기 문제가 포함되나요? 어떻게 정의하나요? 그들은 어떤 비율을 차지합니까?
이들은 해결해야 할 몇 가지 기본적인 문제일 뿐입니다. 실제 벤치마크 설계 과정에서는 위의 문제보다 훨씬 더 어려운 수많은 문제에 직면하게 됩니다.
그러므로 저자는 AI 실무자로서 다양한 AI 모델의 순위를 합리적으로 볼 것을 모두에게 당부합니다. 공정한 테스트 벤치마크도 없는데 이 순위가 무슨 소용이 있겠습니까?
앞서 말했듯이 생성 모델이 좋은지 아닌지는 실제 사용자에 따라 다릅니다.
목록에서 아무리 높은 순위에 있는 모델이라도 자신이 관심 있는 문제를 해결할 수 없다면 그 모델은 평범한 모델일 뿐입니다. 즉, 최하위에 랭크된 모델이 당신이 우려하는 시나리오에서 매우 강한 모델이라면 당신에게는 보물모델이다.
여기서 저자는 우리 팀이 직접 작성한 하드케이스(어려운 케이스) 테스트 세트를 공개합니다. 이 테스트 세트는 어려운 문제/지침을 해결하는 모델의 능력에 중점을 둡니다.
이 어려운 테스트 세트는 모델의 언어 이해, 복잡한 지침 이해 및 따르기, 텍스트 생성, 복잡한 콘텐츠 생성, 여러 라운드의 대화, 모순 감지, 상식 추론, 수학적 추론, 반사실적 추론, 위험한 정보 식별 및 법률에 중점을 둡니다. 윤리의식, 한문지식, 교차언어능력, 코딩능력 등
이것은 생성 모델의 어려운 예제 해결 능력을 테스트하기 위해 저자 팀이 만든 사례 세트라는 점을 다시 강조합니다. 평가 결과는 "어떤 모델이 저자 팀에 더 좋다고 느끼는지"만을 나타낼 수 있습니다. 편견 없는 테스트 결론. 편견 없는 테스트 결론을 원한다면 먼저 위에서 언급한 평가 질문에 답한 다음 권위 있는 테스트 벤치마크를 정의하세요.
직접 평가하고 검증하고 싶은 친구들은 이 공개 계정 '시샤오야오 테크놀로지' 백그라운드에서 [AI 평가] 비밀번호를 답장해 테스트 파일을 다운로드할 수 있다
다음은 현재 가장 논란이 되고 있는 소식이다. superclue list 세 가지 모델의 평가 결과: Feixinghuo, Wenxinyiyan 및 ChatGPT:



난해한 사례 해결률:
- ChatGPT(GPT-3.5-turbo): 11/24=45.83%
- Wen Xinyiyan(2023.5.10 버전): 13/24=54.16%
- iFlytek Spark(2023.5.10 버전): 7/24=29.16%
iFlytek Spark가 Wen A 단어만큼 좋지 않다는 것을 증명하기 위한 것입니다. 마음에서? 이전 글을 잘 읽어보시면 글쓴이가 무슨 말을 하고 싶은지 아실 겁니다.
실제로 Spark 모델이 우리 팀 내의 어려운 케이스 세트에서 Wen Xinyiyan만큼 좋지는 않지만, 이것이 전체적으로 다른 케이스 세트보다 확실히 낫다는 것을 의미하지는 않습니다. 우리 팀 Wenxinyiyan은 ChatGPT보다 더 어려운 두 가지 사례를 해결하는 등 최고의 성과를 거두었습니다.
간단히 질문드리자면, 실제로 국내 모델과 ChatGPT는 큰 차이가 없습니다. 어려운 문제의 경우 각 모델마다 고유한 장점이 있습니다. 저자 팀의 포괄적인 경험으로 판단하면 Wen Xinyiyan은 학술 테스트에서 ChatGLM-6B와 같은 오픈 소스 모델을 능가하기에 충분합니다. 일부 기능은 ChatGPT보다 열등하고 일부 기능은 ChatGPT를 능가합니다.
Alibaba Tongyi Qianwen, iFlytek Spark 등 다른 주요 제조업체에서 생산하는 국내 모델도 마찬가지입니다.
그래도 지금은 공정한 테스트 벤치마크조차 없는 상태인데, 모델 순위를 매겨도 무슨 소용이 있겠습니까?
다양한 편향된 순위에 대해 논쟁하기보다는 우리 팀처럼 관심 있는 테스트 세트를 만드는 것이 좋습니다.
문제를 해결할 수 있는 모델이 좋은 모델입니다.
위 내용은 Baidu Wenxinyiyan은 국내 모델 중 꼴찌입니까? 나는 혼란스러웠다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!