
단어 집합으로부터 시각적 언어 모델 구축 가능성에 대한 연구

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-21 23:22:041489검색
Translator | Zhu Xianzhong
Reviewer | Chonglou
현재 멀티모달 인공지능이 되었습니다. 거리 토크 화제의 화제. 최근 GPT-4가 출시되면서 우리는 불과 6개월 전만 해도 상상할 수 없었던 수많은 새로운 애플리케이션과 미래 기술을 목격하게 되었습니다. 실제로 시각적 언어 모델은 일반적으로 다양한 작업에 유용합니다. 예를 들어 CLIP (Contrastive Language-Image Pre-training, 즉 "Contrastive Language-Image Pre-training")을 사용할 수 있습니다. 링크: https://www.php.cn/link /b02d46e8a3d8d9fd6028f3f2c2495864 보이지 않는 데이터세트에 대한 제로샷 이미지 분류; 일반적으로 아무런 훈련 없이도 우수한 성능을 얻을 수 있습니다.
그동안, 시각적 언어 모델 안 돼. 이 기사에서는 이러한 모델의 한계를 탐색하여 실패할 수 있는 위치와 이유를 강조할 예정입니다. 실제로 이 기사 에서는 짧고 높은 수준의 설명을 게시할 예정입니다. ICLR 2023 Oral논문으로 출판될 예정입니다. 확인하고 싶다면 전체 소스 코드를 확인하세요. 기사를 보려면 링크 https://www.php.cn/link/afb992000fcf79ef7a53fffde9c8e044를 클릭하세요. 소개시각 언어 모델이란 무엇입니까?
언어 모델은 다음을 활용하여 해당 분야에 혁명을 일으켰습니다. 다양한 작업을 수행하기 위한 시각적 데이터와 언어적 데이터의 시너지 효과 기존 문헌에 많은 시각적 언어 모델이 도입되었지만 CLIP(Contrast Language - Image Pre-training)은 여전히 가장 잘 알려져 있습니다. 이미지와 캡션을 동일한 벡터 공간에 삽입함으로써 CLIP 모델은 ~ 패턴 추론을 가능하게 하여 사용자가 제로샷 이미지 분류 및 텍스트와 같은 작업을 수행할 수 있습니다. 그리고 CLIP 모델은 대조 학습 방법을 사용하여 이미지와 캡션의 임베딩을 학습합니다.
대조 학습 소개 CLIP 모델은 이미지를 연관시키는 방법을 학습합니다. 공유 벡터 공간에서 이미지 사이의 거리를 최소화하여 해당 캡션. CLIP 모델과 기타 대비 기반 모델을 통해 얻은 순서는 이 접근 방식이 매우 효과적이라는 것을 보여줍니다. 대비 손실은 이미지와
title 쌍을 일괄적으로 비교하는 데 사용되며, 모델은 임베딩 쌍 간의 유사성을 최대화하고 일괄적으로 다른 이미지-텍스트 쌍 간의 유사성을 줄이도록 최적화되었습니다 아래 그림은 보여줍니다
가능한 일괄 처리 및 학습 단계의 예,where:
- 보라색 사각형에는 모든 제목에 대한 삽입이 포함되고, 녹색 사각형에는 모든 이미지에 대한 삽입이 포함됩니다.
- 행렬의 정사각형에는 배치의 모든 이미지 임베딩과 모든 텍스트 임베딩의 내적이 포함됩니다(임베딩이 정규화되었으므로 "코사인 유사성"을 읽으십시오).
- 파란색 정사각형에는 모델이 유사성을 최대화해야 하는 이미지-텍스트 쌍 사이의 내적이 포함되어 있고, 다른 흰색 정사각형은 우리가 최소화하려는 유사성입니다(각 정사각형에는 일치된 유사성이 포함되어 있으므로 고양이 이미지 및 "내 빈티지 의자"
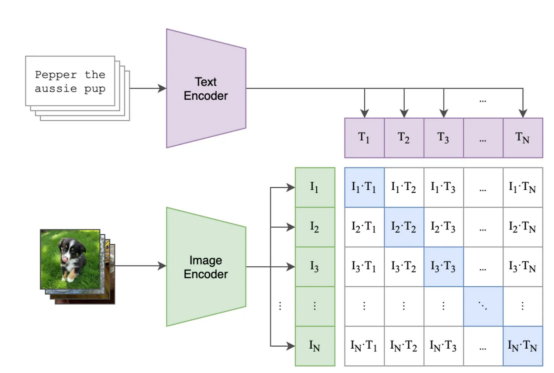
( 파란색 사각형이 있는 곳) 유사성을 최적화하려는 이미지-텍스트 쌍 )
교육 후에는 의미 있는 벡터 공간의 이미지와제목을 인코딩할 수 있는 코드를 생성할 수 있어야 합니다. 각 이미지와 각 텍스트에 콘텐츠를 삽입하면 제목에 더 적합한 이미지를 확인하는 등의 작업을 수행할 수 있습니다(예: “2017 여름 휴가 사진 앨범 해변의 개” 찾기)(해변의 개). )) 또는 어떤 텍스트 라벨이 주어진 그림과 더 유사한지 찾아보세요(예: 개와 고양이의 이미지가 여러 개 있고 어느 것이 어느 것인지 식별할 수 있기를 원함). CLIP과 같은 언어 모델은 시각적 정보와 언어적 정보를 통합하여 복잡한 인공 지능 작업을 해결하는 강력한 도구가 되었습니다. 공유 벡터 공간에 이러한 두 가지 유형의 데이터를 삽입하는 기능은 전례 없는 정확성과 광범위한 응용 프로그램을 제공합니다. 시각 언어 모델이 언어를 이해할 수 있습니까?
우리
는 정확히 이에 답하기 위해 몇 가지 조치를 취하려고 합니다. 딥 모델이 언어를 어느 정도 이해할 수 있는지 여기서 우리의 목표는 시각적 언어 모델과 그 합성 기능을 연구하는 것입니다.먼저 이 새로운 벤치마크를 ARO(Attribution, Relations, and Order: Attributes
, 관계 및 순서) 다음으로 이 경우 대비 손실이 제한될 수 있는 이유를 살펴보겠습니다. 마지막으로 이 문제에 대한 간단하지만 유망한 솔루션을 제안합니다. : ARO.(속성, 관계 및 순서)CLIP(및 Salesforce의 최근 BLIP)과 같은 모델이 언어를 얼마나 잘 이해하는지
우리는 속성 기반 합성 제목(예: "빨간 문과 서있는 남자"(빨간 문과 서있는 남자)) 세트를 수집했습니다. 제목(예: "말이 풀을 먹고 있습니다"말이 풀을 먹고 있습니다))과 일치하는 이미지의 관계 기반 합성입니다. 그런 다음 뒤의 를 대체하는 가짜 제목 을 생성합니다. 예를 들어 "풀이 말을 먹고 있습니다"(잔디가 말을 먹고 있습니다 ) . 모델들이 적합한 직함을 찾을 수 있을까요? 또한 단어 섞기의 효과도 조사했습니다. 모델이 섞이지 않은 titles을 섞은 titles보다 선호합니까?
속성 ) benchmark에 대해 생성한 4개의 데이터 세트는 아래와 같습니다(주문 부분 에는 두 개의 데이터 세트가 포함되어 있습니다).

우리가 만든 다양한 데이터 세트 에는 관계, 귀속 및 순서가 포함됩니다. 각 데이터세트에 대해 이미지 예시와 다른 제목을 보여줍니다. 그 중 제목은 하나만 정확하며, 모델은 이 정확한 제목을 식별해야 합니다.
- 속성부동산에 대한 이해도 테스트결과는: "포장된 도로와 하얀 집" (포장된 도로와 하얀 집)with "하얀 길과 포장된 집"(白路和狠的屋).
- 관계에 대한 이해 테스트 결과는 : “말이 풀을 먹고 있다”(말이 풀을 먹고 있다) 과 “풀이 먹고 있다” 말”(풀이 풀을 먹고 있어요).
- 마지막으로 Order는 순서 섞기 주문에 대한 모델의 탄력성을 테스트했습니다. 결과 : 표준 데이터 세트(예: MSCOCO)의 제목을 무작위로 섞었습니다.
시각 언어 모델이 이미지에 맞는 올바른 캡션을 찾을 수 있나요? 작업은 쉬워 보입니다. 모델이 "말이 풀을 먹고 있습니다"와 "풀이 풀을 먹고 있습니다"의 차이를 이해하기를 원합니다. 그렇죠? 내 말은, 누가 풀을 먹는 것을 본 적이 있습니까?
글쎄, 아마도 BLIP 모델은 "말이 풀을 먹고 있다"와 "풀이 풀을 먹고 있다"의 차이를 이해하지 못하기 때문일 것입니다:

BLIP 모델은 "풀이 풀을 먹고 있다"와 "말이 풀을 먹고 있다"의 차이를 이해하지 못합니다. (여기서 에는 시각적 게놈 데이터 세트의 요소가 포함되어 있습니다 , 이미지 제공 제공됨 )
이제 , 실험결과를 살펴보겠습니다. 가능성을 능가할 수 있는 모델은 거의 없습니다. 관계를 폭넓게 이해하는 것 (for 예를 들어, 먹기——먹기). 그러나 CLIP 모델 은 속성 의 가장자리 및 관계 측면에서 이 가능성 보다 약간 높습니다. 이것은 실제로 시각적 언어 모델에 문제가 있음을 보여줍니다 still.
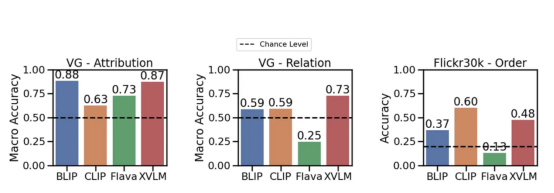
속성, 관계 및 순서(Flick30k) 벤치마크에 대한 다양한 모델의 성능. CLIP, BLIP 및 기타 SoTA 모델을 사용한검색 및 비교 손실 평가
이 작업의 주요 결과 중 하나는 언어 학습에 필요한 가능성이 있다는 것입니다. 표준 대비 손실뿐만 아니라. 이게 왜?
처음부터 시작해 보겠습니다. 시각적 언어 모델은 종종 검색 작업에서 평가됩니다. 제목을 가져와서 매핑되는 이미지를 찾으세요. 이러한 모델을 평가하는 데 사용되는 데이터 세트(예: MSCOCO, Flickr30K)를 보면 구성 기술에 대한 이해가 필요한titles로 설명된 이미지가 포함된 경우가 많다는 것을 알 수 있습니다(예: "주황색 고양이는 on the red table": 주황색 고양이가 빨간 테이블 위에 있습니다). 그렇다면 title이 복잡하다면 왜 모델은 구성 이해를 학습할 수 없나요? [Description]
이러한 데이터 세트를 검색하는 데 반드시 구성에 대한 이해가 필요한 것은 아닙니다. 문제를 더 잘 이해하려고 노력했으며 제목에서 단어 순서를 섞을 때 모델의 검색 성능을 테스트했습니다. "사람을 보는 책은"
이라는 제목에 맞는 이미지를 찾을 수 있을까요? 대답이 '예'라면이는 , 올바른 이미지를 찾는 데 지침 정보가 필요하지 않음을 의미합니다.
저희 테스트 모델은 뒤섞인 제목을 사용하여 검색하는 작업을 담당합니다. 캡션을 뒤섞더라도 모델은 해당 이미지를 올바르게 찾을 수 있습니다(그 반대도 마찬가지). 이는 검색 작업이 너무 단순할 수 있음을 시사합니다. , 작가가 제공한 이미지.
다양한 shuffle 프로세스를 테스트한 결과 긍정적이었습니다. 다른 shuffle 기술을 사용하더라도 검색 성능은 기본적으로 영향을 받지 않습니다.
다시 말해 보겠습니다. 시각적 언어 모델은 명령 정보에 액세스할 수 없는 경우에도 이러한 데이터 세트에서 고성능 검색을 달성합니다. 이러한 모델은 순서가 중요하지 않은 단어 더미 처럼 동작할 수 있습니다. 모델이 검색을 잘 수행하기 위해 단어 순서를 이해할 필요가 없다면 실제로 검색에서 무엇을 측정하는 것일까요? ?
어떻게 해야 하나요?
이제 문제가 있다는 것을 알았으므로 해결책을 찾고 싶을 수도 있습니다. 가장 간단한 방법은 CLIP 모델이 "The cat is on the table"과 "the table is on the cat"이 다르다는 것을 이해하도록 하는 것입니다.
사실 우리가 제안한 방법 중 하나는 이 문제를 해결하기 위해 특별히 제작된 하드 네거티브를 추가하여 CLIP 교육 을 개선하는 것입니다. 이는 매우 간단하고 효율적인 솔루션입니다. 전체 성능에 영향을 주지 않고 원본 CLIP 손실에 대한 아주 작은 편집이 필요합니다(문서에서 몇 가지 주의 사항을 읽을 수 있음). 우리는 이 버전의 CLIP을 NegCLIP이라고 부릅니다.
CLIP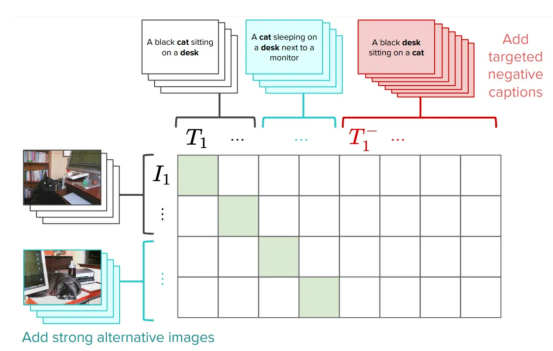
에 하드 네거티브 도입 기본적으로는 NegCLIP 모델에게 “책상에 앉아 있는 검은 고양이”라는 문장 위에 검은 고양이의 이미지를 배치해 달라고 요청합니다. 가깝지만 멀다문장
"검은 책상 고양이 위에 앉아'(고양이 위에 앉아 있는 검은 책상). 참고, 후자는 POS 태그를 사용하여 자동으로 생성됩니다. 이 수정의 효과는 검색 성능이나 검색 및 분류와 같은 다운스트림 작업의 성능을 저하시키지 않고 실제로 ARO 벤치마크의 성능을 향상시킨다는 것입니다. 다양한 벤치마크 결과는 아래 그림을 참조하세요(자세한 내용은 해당 문서 참조).
NegCLIPmodel과 CLIPmodel이 서로 다른 벤치마크에서 비교되었습니다. 그 중 blue 벤치마크는 저희가 소개한 벤치마크이고, green 벤치마크는 networkdocumentation(작가가 제공한 사진)
You에서 따왔습니다. 이는 ARO 벤치마크에 비해 크게 개선되었으며, 다른 다운스트림 작업에서도 edge개선 또는 유사한 성능이 나타났습니다.
프로그래밍 구현
Mert(논문의 주 저자)이 작은 라이브러리 를 만들어 시각적 언어 모델을 테스트하는 중입니다. 완료. 그의 코드를 사용하여 결과를 복제하거나 새로운 모델을 실험할 수 있습니다.
몇 라인의 P만 필요합니다.
import clip
from dataset_zoo import VG_Relation, VG_Attribution
model, image_preprocess = clip.load("ViT-B/32", device="cuda")
root_dir="/path/to/aro/datasets"
#把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话
#对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集
vgr_dataset = VG_Relation(image_preprocess=preprocess,
download=True, root_dir=root_dir)
vga_dataset = VG_Attribution(image_preprocess=preprocess,
download=True, root_dir=root_dir)
#可以对数据集作任何处理。数据集中的每一项具有类似如下的形式:
# item = {"image_options": [image], "caption_options": [false_caption, true_caption]}또한 NegCLIP 을 구현했습니다. 모델 (실제로 업데이트된 사본입니다) OpenCLIP)의 전체 코드 다운로드 주소는 https://github.com/vinid/neg_clip입니다.
결론
요컨대, 시각적 언어 모델은 현재 많은 일을할 수 있습니다. 다음으로, GPT4와 같은 미래 모델이 무엇을 할 수 있을지 기대됩니다!
번역가 소개
Zhu Xianzhong, 51CTO 커뮤니티 편집자, 51CTO 전문 블로거, 강사, 웨이팡 대학의 컴퓨터 교사이자 프리랜스 프로그래밍 업계의 베테랑입니다.
원제: 귀하의 비전-언어 모델은 단어의 가방이 될 수 있습니다, 저자: Federico Bianchi
위 내용은 단어 집합으로부터 시각적 언어 모델 구축 가능성에 대한 연구의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!