



Technical Background
이전 블로그에서는 vaex와 같은 대규모 데이터 처리 솔루션에 중점을 둔 python3를 사용하여 테이블 형식 데이터를 처리하는 몇 가지 방법을 소개했습니다. 이 데이터 처리 솔루션은 메모리 맵 파일을 생성함으로써 소스 데이터를 메모리에 직접 로드하여 발생하는 대규모 메모리 사용 문제를 방지합니다. 이를 통해 대규모 프로세스가 아닌 로컬 컴퓨터 메모리 크기를 사용할 수 있습니다. 매우 큰 조건의 데이터. Python 3에는 메모리 매핑 파일을 직접 생성하는 데 사용할 수 있는 mmap이라는 라이브러리가 있습니다.
tracemalloc을 사용하여 Python 프로그램 메모리 사용량 추적
여기에서는 메모리 매핑 기술의 실제 메모리 사용량을 비교하기를 원하므로 Python 기반 메모리 추적 도구인 Tracemalloc을 소개해야 합니다. 먼저 간단한 예를 들어 보겠습니다. 즉, 임의의 배열을 만든 다음 배열이 차지하는 메모리 크기를 관찰해 보겠습니다
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)출력 결과는 다음과 같습니다.
[dechin@dechin-manjaro mmap]$ python3 Tracem. py
[Top 10 ]
tracem.py:8: size=78.2 KiB, count=2,average=39.1 KiB
top 명령을 사용하여 메모리를 직접 감지하면 Google Chrome에 최고 메모리 공유:
top - 10:04:08 최대 6일, 15:18, 사용자 5명, 로드 평균: 0.23, 0.33, 0.27
작업: 총 309개, 실행 중 1개, 절전 모드 264개, 정지 23개, 좀비 21개
%Cpu(s): 0.6 us, 0.2 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem: 총 39913.6, 25450.8 무료, 1875.7 사용됨, 12587.1 버프/캐시
Mi B 스왑: 총 16384.0, 무료 16384.0, 0.0 사용됨 36775.8 avail Mem
프로세스 ID USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
286734 dechin 20 0 36.6g 175832 117544 S 4.0 0.4 1:02.32 크롬
그래서 프로세스 번호를 기준으로 하위 항목 추적 프로세스의 메모리 사용량은 Tracemalloc 사용의 핵심입니다. 여기에서 크기가 10000인 numpy 벡터의 메모리 사용량은 약 39.1KiB이며 이는 실제로 우리의 기대와 일치합니다.
In [3]: 39.1*1024/ 4
Out[3]: 10009.6
이것은 거의 10000 float32 부동 소수점 숫자의 메모리 공간이기 때문에 이는 모든 요소가 메모리에 저장되었음을 나타냅니다.
tracemalloc을 사용하여 메모리 변경 사항 추적
이전 장에서 스냅샷 메모리 스냅샷의 사용을 소개했는데, 그러면 두 개의 메모리 스냅샷을 "찍고" 스냅샷의 변경 사항을 비교하는 것을 쉽게 생각할 수 있습니다. 기억의 변화? 다음으로 간단한 시도를 해보세요:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)실행 결과는 다음과 같습니다:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[상위 10개 차이점]
comp_tracem.py:9: size=78.2 KiB (+78.2 KiB), count=2 (+2),average=39.1 KiB
벡터의 차원을 1000000으로 변경하면 이 스냅샷 전후의 평균 메모리 크기 차이가 39.1 KiB임을 알 수 있습니다.
length=1000000
다시 실행 효과 살펴보기:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[상위 10가지 차이점]
comp_tracem.py:9: size=7813 KiB (+7813 KiB ), count=2 (+2) ,average=3906KiB
결과는 3906으로 100배 증폭된 것과 동일하며 기대치에 더 부합하는 것으로 나타났습니다. 물론 신중하게 계산해 보면
In [4]: 3906*1024/4
Out[4]: 999936.0
완전한 float32 유형과 비교하면 완전히 float32 유형이 아니라는 것을 알 수 있습니다. type 메모리 크기 중 일부가 누락되었습니다. 중간에 0이 일부 생성되어 크기가 자동으로 압축되었는지 궁금합니다. 그러나 이 문제는 우리가 집중하고 싶은 것이 아닙니다. 우리는 메모리 변화 곡선을 아래쪽으로 계속 테스트하고 있습니다.
메모리 사용량 곡선
이전 두 장의 내용을 이어갑니다. 주로 다양한 차원의 무작위 배열에 필요한 메모리 공간을 테스트합니다. 위 코드 모듈을 기반으로 for 루프가 추가됩니다.
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')렌더링
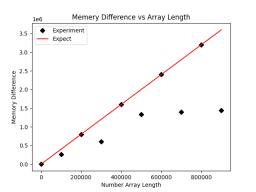
여기에서도 대부분의 경우 메모리 사용량이 예상과 일치하지만 예상보다 적게 차지하는 지점이 많기 때문에 요소가 0개이기 때문에 발생하는 것으로 의심됩니다. 0이 최대한 발생하지 않도록 코드를 약간 수정하고 원본 코드를 기반으로 연산을 추가했습니다.
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')업데이트 후 결과 그림은 다음과 같습니다.
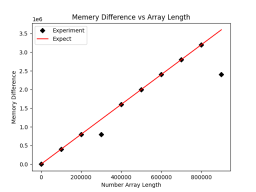
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
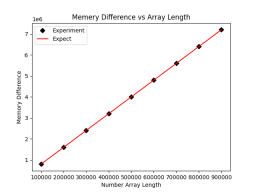
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
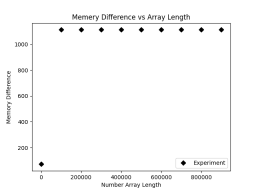
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。
위 내용은 Python3에서 Tracemalloc을 사용하여 mmap 메모리 변경 사항을 추적하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Python vs. C : 응용 및 사용 사례가 비교되었습니다Apr 12, 2025 am 12:01 AM
Python vs. C : 응용 및 사용 사례가 비교되었습니다Apr 12, 2025 am 12:01 AMPython은 데이터 과학, 웹 개발 및 자동화 작업에 적합한 반면 C는 시스템 프로그래밍, 게임 개발 및 임베디드 시스템에 적합합니다. Python은 단순성과 강력한 생태계로 유명하며 C는 고성능 및 기본 제어 기능으로 유명합니다.
 2 시간의 파이썬 계획 : 현실적인 접근Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근Apr 11, 2025 am 12:04 AM2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 파이썬 : 기본 응용 프로그램 탐색Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색Apr 10, 2025 am 09:41 AMPython은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?Apr 09, 2025 pm 04:33 PM
2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?Apr 09, 2025 pm 04:33 PM2 시간 이내에 파이썬의 기본 사항을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우십시오. 이를 통해 간단한 파이썬 프로그램 작성을 시작하는 데 도움이됩니다.
 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?Apr 02, 2025 am 07:18 AM10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?
 중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?Apr 02, 2025 am 07:15 AM
중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?Apr 02, 2025 am 07:15 AMFiddlerevery Where를 사용할 때 Man-in-the-Middle Reading에 Fiddlereverywhere를 사용할 때 감지되는 방법 ...
 Python 3.6에 피클 파일을로드 할 때 '__builtin__'모듈을 찾을 수없는 경우 어떻게해야합니까?Apr 02, 2025 am 07:12 AM
Python 3.6에 피클 파일을로드 할 때 '__builtin__'모듈을 찾을 수없는 경우 어떻게해야합니까?Apr 02, 2025 am 07:12 AMPython 3.6에 피클 파일로드 3.6 환경 보고서 오류 : modulenotfounderror : nomodulename ...
 경치 좋은 스팟 코멘트 분석에서 Jieba Word 세분화의 정확성을 향상시키는 방법은 무엇입니까?Apr 02, 2025 am 07:09 AM
경치 좋은 스팟 코멘트 분석에서 Jieba Word 세분화의 정확성을 향상시키는 방법은 무엇입니까?Apr 02, 2025 am 07:09 AM경치 좋은 스팟 댓글 분석에서 Jieba Word 세분화 문제를 해결하는 방법은 무엇입니까? 경치가 좋은 스팟 댓글 및 분석을 수행 할 때 종종 Jieba Word 세분화 도구를 사용하여 텍스트를 처리합니다 ...


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

Dreamweaver Mac版
시각적 웹 개발 도구

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

