
3조 6천억 개의 토큰과 3,400억 개의 매개변수로 구글의 대형 모델 PaLM 2의 세부 정보가 공개됐다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-21 08:07:20998검색
지난 목요일 2023 구글 I/O 컨퍼런스에서 구글 CEO 피차이는 GPT-4를 벤치마킹한 대형 모델인 PaLM 2의 출시를 발표하고, 수학, 코드, 추론, 다중성을 향상시킨 프리뷰 버전을 공식 출시했다. -언어 번역 및 자연어 생성 기능.

PaLM 2 모델은 소형부터 대형, 게코(Gecko), 수달(Otter), 들소(Bison), 유니콘(Unicorn)까지 다양한 크기의 4가지 버전으로 제공되므로 다양한 사용 사례에 맞게 배포하기가 더 쉽습니다. 그 중 경량 Gecko 모델은 모바일 장치에서 매우 빠르게 실행할 수 있으며 인터넷에 연결하지 않고도 장치에서 뛰어난 대화형 응용 프로그램을 실행할 수 있습니다.
그러나 Google은 회의에서 PaLM 2에 대한 구체적인 기술 세부 정보를 제공하지 않았으며 PaLM 2가 Google의 최신 JAX 및 TPU v4를 기반으로 구축되었다고만 밝혔습니다.

어제 외신 CNBC가 본 내부 문서에 따르면 PaLM 2는 3조 6천억 개의 토큰으로 훈련을 받았습니다. 비교를 위해 이전 세대 PaLM은 7,800억 개의 토큰에 대해 교육을 받았습니다.
또한 Google은 이전에 PaLM 2가 이전 LLM보다 작기 때문에 더 복잡한 작업을 완료하면서 더 효율적일 수 있다고 밝혔습니다. 이는 내부 문서에서도 확인된 바 있으며, PaLM 2의 학습 매개변수 크기는 3400억으로 PaLM의 5400억보다 훨씬 작습니다. 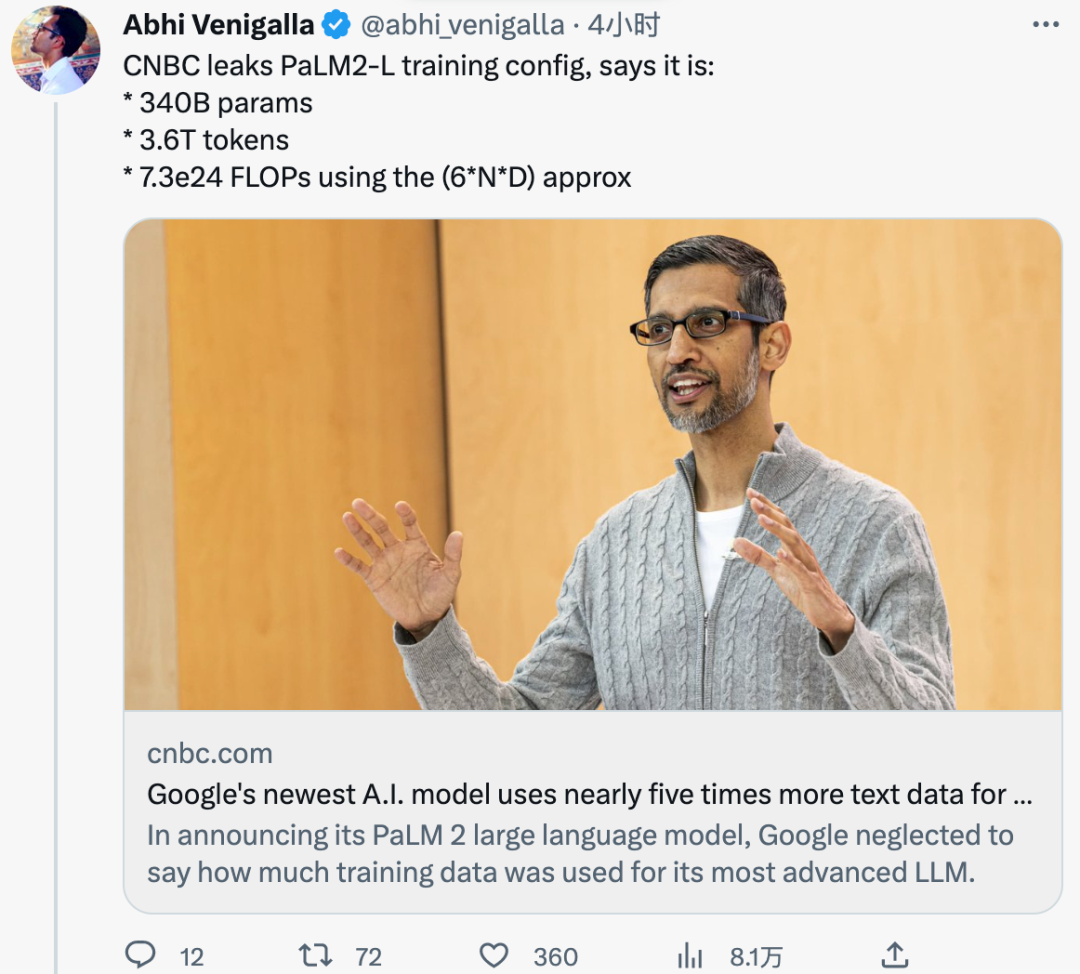
PaLM 2의 훈련 토큰과 매개변수는 다른 LLM과 어떻게 비교되나요? 비교를 위해 지난 2월 Meta가 출시한 LLaMA는 1조 4천억 개의 토큰으로 훈련되었습니다. OpenAI의 1,750억 매개변수 GPT-3는 3,000억 개의 토큰으로 훈련되었습니다.
Google은 AI 기술의 힘과 AI 기술이 검색, 이메일, 문서 처리 및 스프레드시트에 어떻게 포함될 수 있는지 보여주고 싶어 하는 동시에 훈련 데이터의 크기나 기타 세부 정보를 공개하는 것을 꺼려했습니다. . 실제로 OpenAI는 최신 다중 모드 대형 모델 GPT-4의 세부 사항에 대해서도 침묵하고 있습니다. 그들은 모두 세부 사항을 공개하지 않는 것은 사업의 경쟁적 성격에서 비롯된 것이라고 말했습니다.
그러나 AI 군비 경쟁이 계속 가열되면서 연구계에서는 점점 더 많은 투명성을 요구하고 있습니다. 그리고 얼마 전 유출된 Google 내부 문서에서 Google 내부 연구자들은 다음과 같은 견해를 밝혔습니다. 표면적으로는 OpenAI와 Google이 대규모 AI 모델에서 서로를 쫓고 있는 것처럼 보이지만 실제 승자는 반드시 이 둘에서 나오는 것은 아닙니다. 제3자 세력인 "오픈 소스"가 조용히 부상하고 있기 때문입니다.
현재 이 내부 문서의 진위 여부는 확인되지 않았으며 Google은 관련 내용에 대해 언급하지 않았습니다.
네티즌 댓글
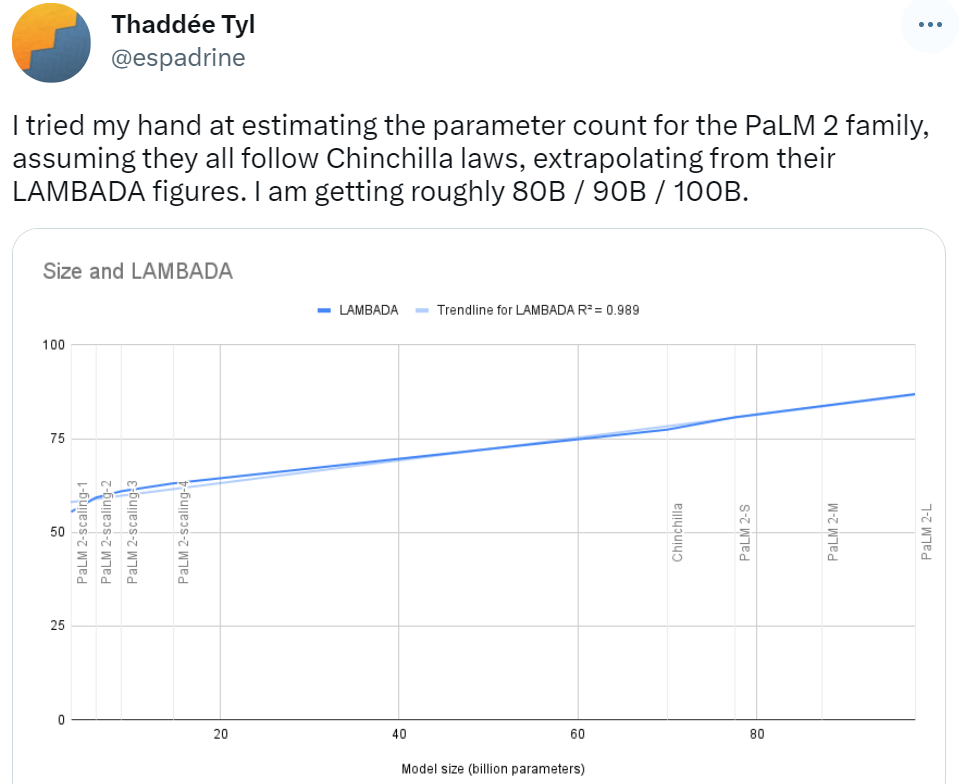
PaLM 2의 공식 발표 초반 일부 네티즌들은 친칠라의 법칙을 바탕으로 PaLM 2 모델군의 매개변수 결과가 80B/90B/100B가 될 것으로 예상했는데, 340B는 이번에 공개된 것과는 많이 다릅니다.
PaLM 2의 훈련 비용에 대해서도 누군가는 예측을 쏟아냈습니다. 이 네티즌은 과거 대형 모델 개발을 토대로 PaLM 2를 만드는 데 1억 달러가 소요될 것이라고 말했습니다.

PaLM 2개의 매개변수가 유출되었습니다. Bard를 추측해 보세요. 이 네티즌은 다음과 같이 말했습니다:
PaLM 2 토큰 수량 유출로 인해 네티즌들은 AGI가 도래하기 전 큰 전환점이 될 때까지 얼마나 많은 토큰이 필요할지 궁금하지 않을 수 없습니다.

위 내용은 3조 6천억 개의 토큰과 3,400억 개의 매개변수로 구글의 대형 모델 PaLM 2의 세부 정보가 공개됐다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!